
In response to the challenging task of generating realistic 3D human-object interactions (HOIs) guided by textual prompts, researchers from Northeastern University, Hangzhou Dianzi University, Stability AI, and Google Research have introduced an innovative solution called HOI-Diff. The intricacies of human-object interactions in computer vision and artificial intelligence have posed a significant hurdle for synthesis tasks.…
LLMs have ushered in a new era of general-purpose vision systems, showcasing their prowess in processing visual inputs. This integration has led to the unification of diverse vision-language tasks through instruction tuning, marking a significant stride in the convergence of natural language understanding and visual perception.
Researchers from Johns Hopkins University, Meta, University of Toronto,…
The challenge of seamlessly translating textual prompts or spontaneous scribbles into intricate 3D multi-view wire art has long been a pursuit at the intersection of artificial intelligence and artistic expression. Traditional methods like ShadowArt and MVWA have focused on geometric optimization or visual hull reconstruction to synthesize multi-view wire art. However, these approaches often need…
In a recent move, Microsoft’s Azure AI platform has expanded its range by introducing two advanced AI models, Llama 2 and GPT-4 Turbo with Vision. This addition marks a significant expansion in the platform’s AI capabilities.
The team at Microsoft Azure AI recently announced the arrival of Llama 2, a set of models developed by…
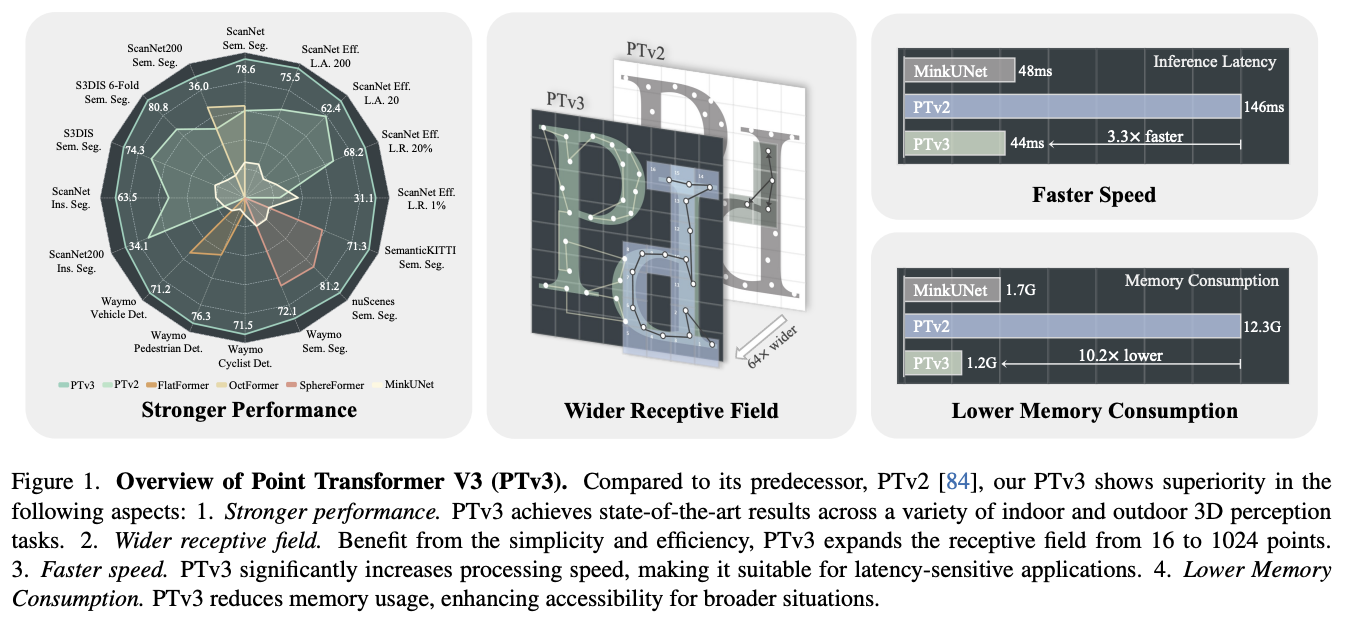
In the digital transformation era, the three-dimensional revolution is underway, reshaping industries with unprecedented precision and depth. At the heart of this revolution lies point cloud processing – an innovative approach that captures the intricacies of our physical world in a digital format. From autonomous vehicles navigating complex terrains to architects designing futuristic structures, point…
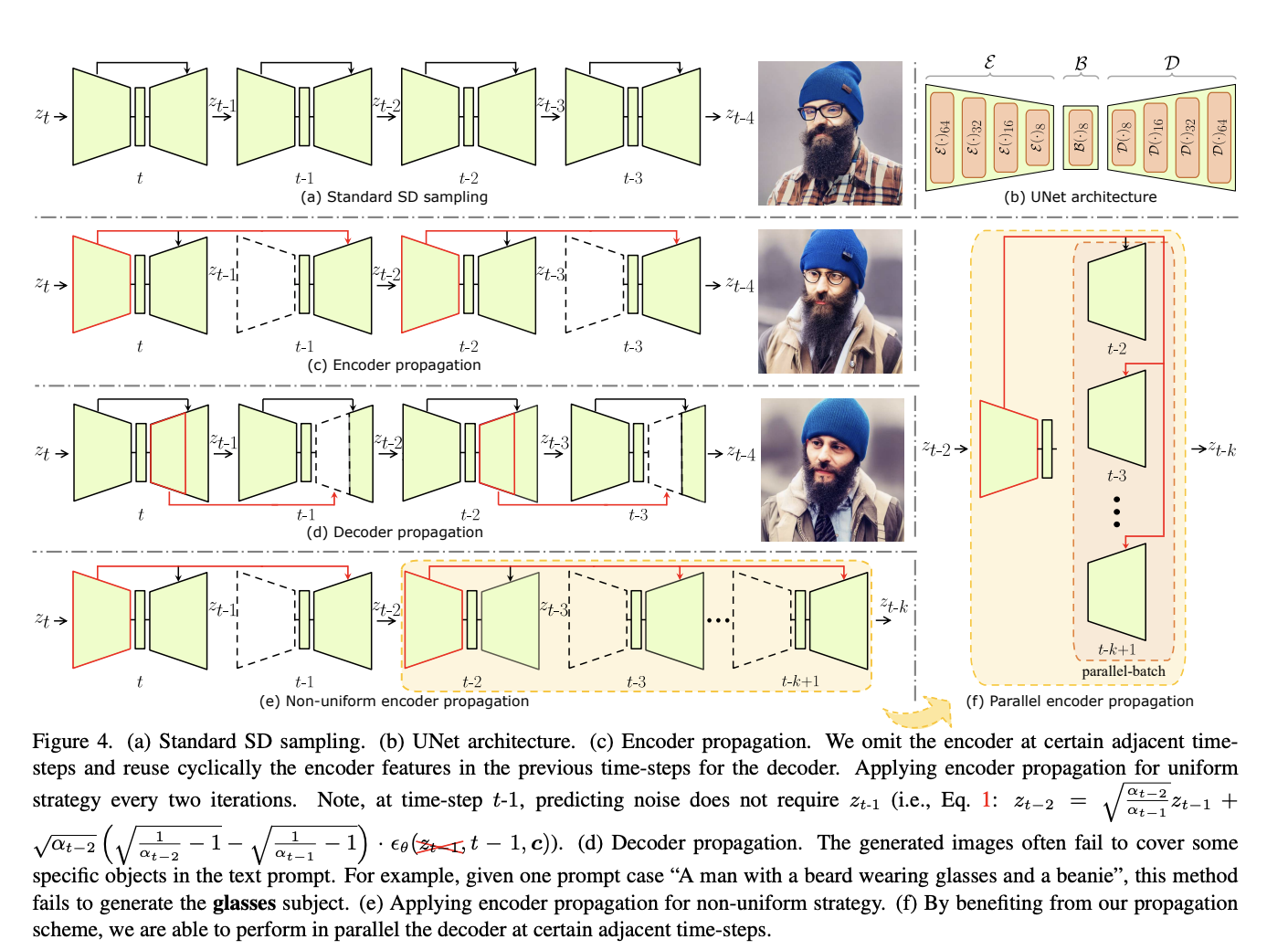
Diffusion models represent a cutting-edge approach to image generation, offering a dynamic framework for capturing temporal changes in data. The UNet encoder within diffusion models has recently been under intense scrutiny, revealing intriguing patterns in feature transformations during inference. These models use an encoder propagation scheme to revolutionize diffusion sampling by reusing past features, enabling…

Addressing the challenge of efficient and controllable image synthesis, the Alibaba research team introduces a novel framework in their recent paper. The central problem revolves around the need for a method that generates high-quality images and allows precise control over the synthesis process, accommodating diverse conditional inputs. The existing methods in image synthesis, such as…
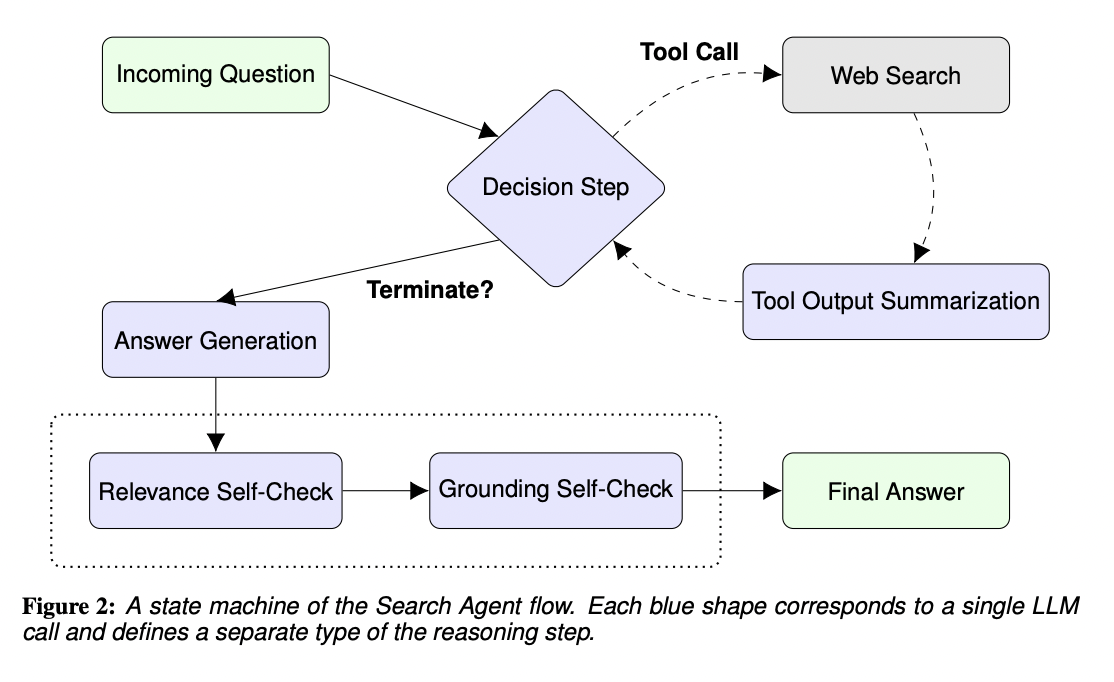
With the recent introduction of Large Language Models (LLMs), the field of Artificial Intelligence (AI) has significantly outshined. Though these models have successfully demonstrated incredible performance in tasks like content generation and question answering, there are still certain challenges in answering complicated, open-ended queries that necessitate interaction with other tools or APIs.
Outcome-based systems, where…
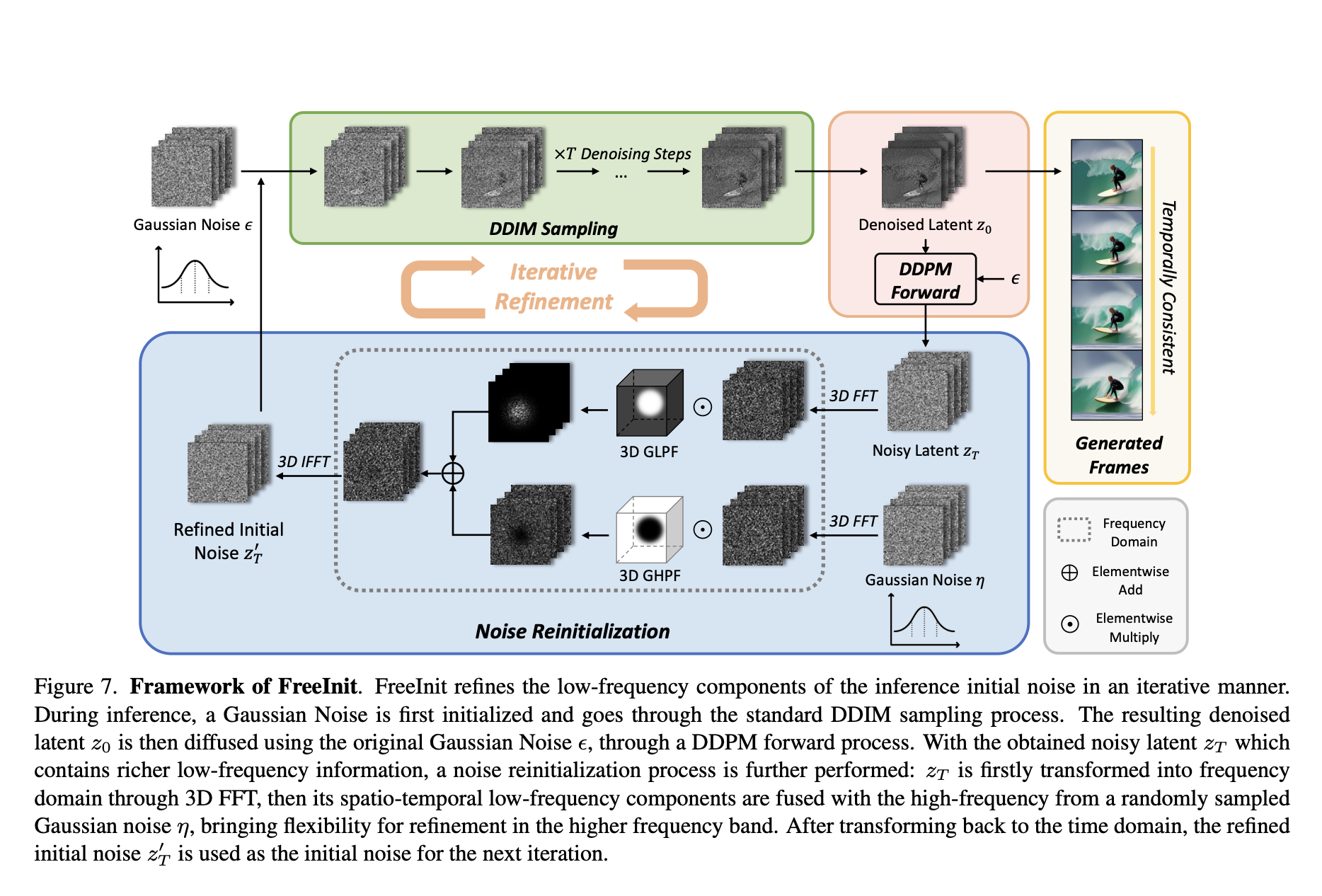
In the realm of video generation, diffusion models have showcased remarkable advancements. However, a lingering challenge persists—the unsatisfactory temporal consistency and unnatural dynamics in inference results. The study explores the intricacies of noise initialization in video diffusion models, uncovering a crucial training-inference gap.
The study addresses challenges in diffusion-based video generation, identifying a training-inference gap…
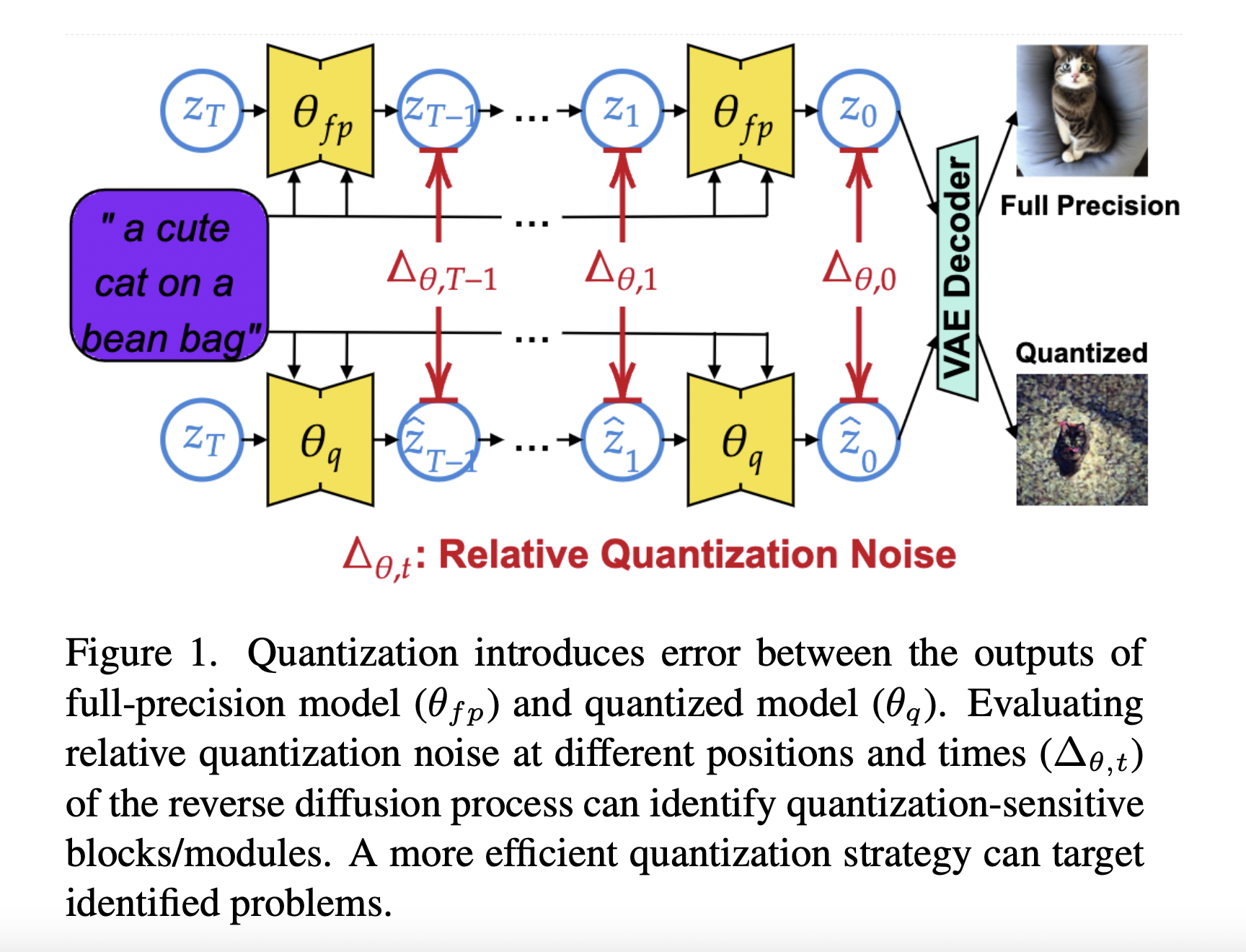
In the era of edge computing, deploying sophisticated models like Latent Diffusion Models (LDMs) on resource-constrained devices poses a unique set of challenges. These dynamic models, renowned for capturing temporal evolution, demand efficient strategies to navigate the limitations of edge devices. This study addresses the challenge of deploying LDMs on edge devices by proposing a…