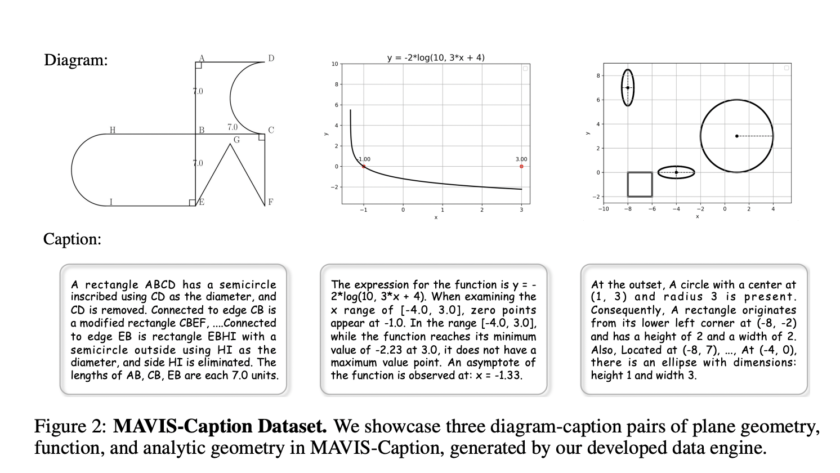
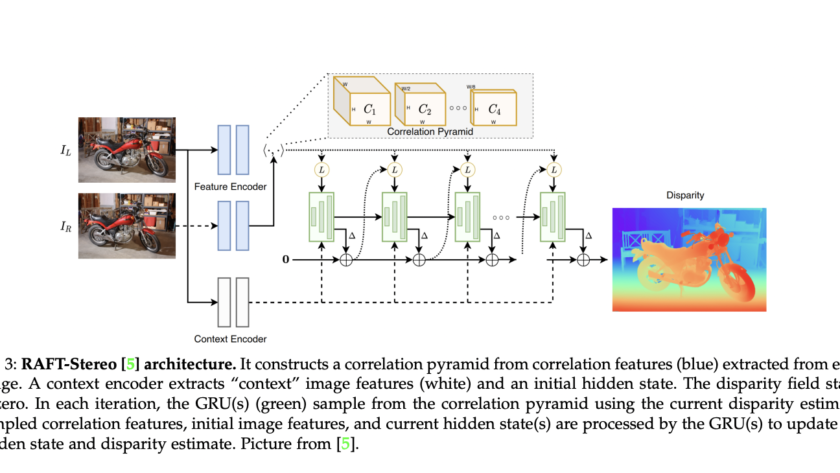
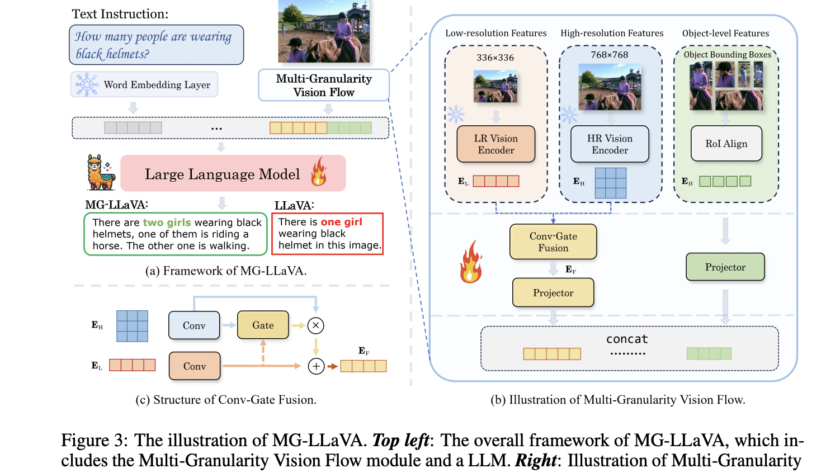
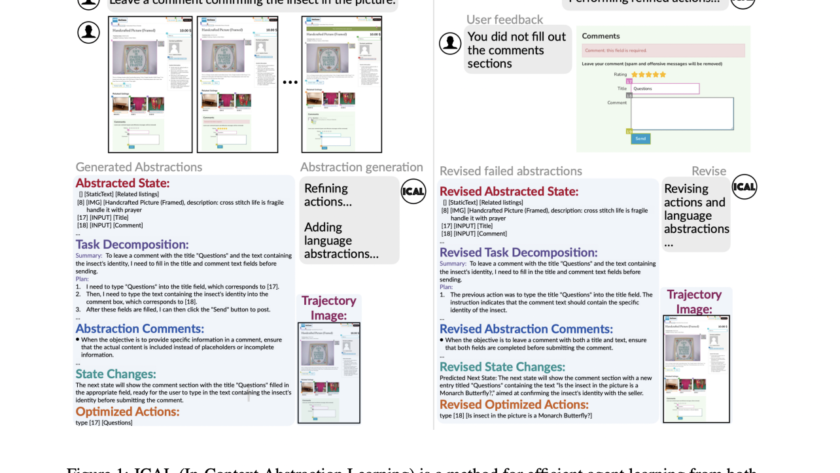
A significant challenge in the field of visual question answering (VQA) is the task of Multi-Image Visual Question Answering (MIQA). This involves generating relevant and grounded responses to natural language queries based on a large set of images. Existing Large Multimodal Models (LMMs) excel in single-image visual question answering but face substantial difficulties when queries…