LLMs have ushered in a new era of general-purpose vision systems, showcasing their prowess in processing visual inputs. This integration has led to the unification of diverse vision-language tasks through instruction tuning, marking a significant stride in the convergence of natural language understanding and visual perception.
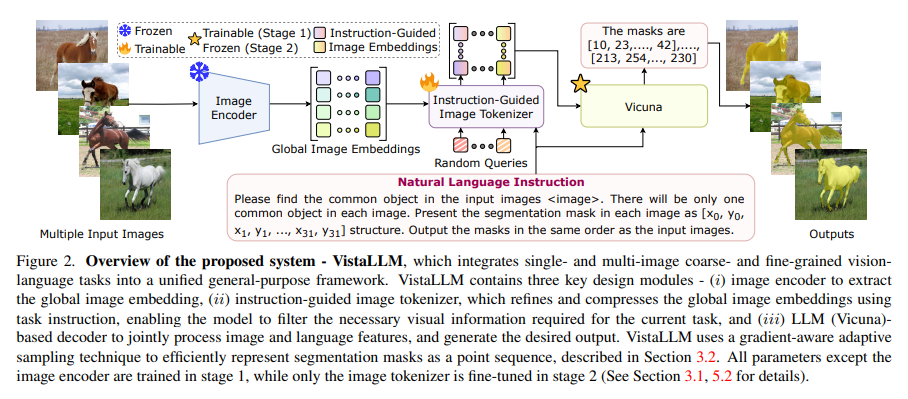
Researchers from Johns Hopkins University, Meta, University of Toronto, and the University of Central Florida propose VistaLLM, a robust visual system tackling coarse and fine-grained vision-language tasks across single and multiple input images through a unified framework. Employing an instruction-guided image tokenizer and a gradient-aware adaptive sampling technique extracts compressed and refined features, representing binary segmentation masks as sequences.
Multimodal large language models (MLLMs), initially designed for image-level tasks like visual question answering and captioning, have evolved to address region-specific vision and language challenges. Recent advancements, exemplified by models like KOSMOS-2, VisionLLM, Shikra, GPT4RoI, and Image Encoder Instruction-Guided Image Tokenizer, showcase the integration of region-based referring and grounding tasks within general-purpose vision systems. This progress signifies a shift towards enhanced region-level vision-language reasoning, marking a substantial leap in the capabilities of MLLMs for complex multimodal tasks.
Large language models excel in natural language processing, but designing general-purpose vision models for zero-shot solutions to diverse vision problems proves challenging. Existing models need to be improved in integrating varied input-output formats and representing visual features effectively. VistaLLM, a model, addresses coarse- and fine-grained vision-language tasks for single and multiple input images using a unified framework.
VistaLLM is an advanced visual system for processing images from single or multiple sources using a unified framework. It uses an instruction-guided image tokenizer to extract refined features and a gradient-aware adaptive sampling technique for representing binary segmentation masks as sequences. The study also highlights the compatibility of EVA-CLIP with the instruction-guided image tokenizer module in the final model.
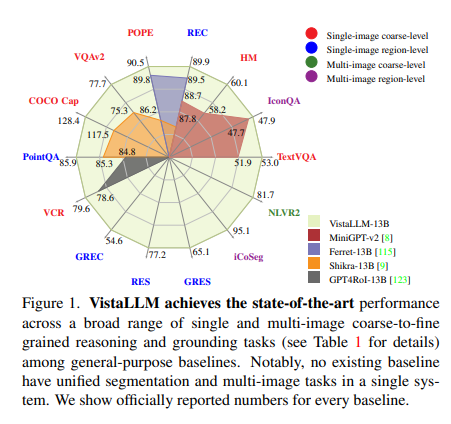
VistaLLM consistently outperforms strong baselines in a broad spectrum of vision and vision-language tasks. It surpasses the general-purpose state-of-the-art on VQAv2 COCO Captioning by 2.3 points and achieves a substantial 10.9 CIDEr points gain over the best baseline. Image captioning matches fine-tuned specialist models, showcasing the language generation capabilities of LLMs. In single-image grounding tasks like REC and RES, VistaLLM also outperforms existing baselines and matches specialist models in RES. It sets new state-of-the-art on diverse studies like PQA BQA, VCR Novel Tasks, CoSeg, and NLVR, demonstrating robust comprehension and performance across various vision-language challenges.
In conclusion, the study can be presented in summary in the following points:
- VistaLLM is a vision model that can handle coarse- and fine-grained reasoning and grounding tasks in single or multiple-input images.
- It converts functions into a sequence-to-sequence format and uses an instruction-guided image tokenizer for refined features.
- The researchers have introduced a gradient-aware adaptive contour sampling scheme to improve sequence-to-sequence segmentation.
- They have created a large instruction-tuning dataset called CoinIt and introduced AttCoSeg to address the lack of multi-image grounding datasets.
- Extensive experiments have shown that VistaLLM consistently outperforms other models across diverse vision and vision-language tasks.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.