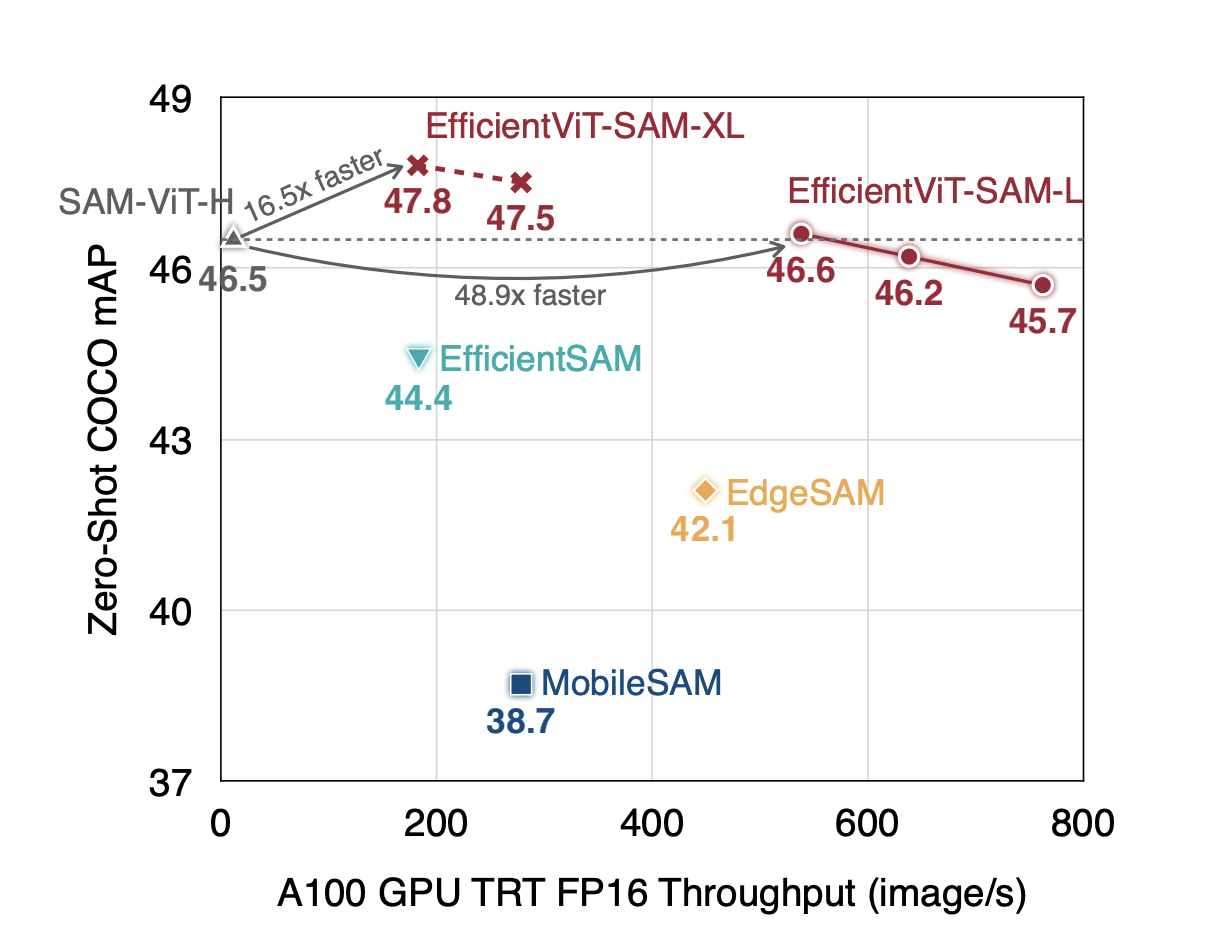
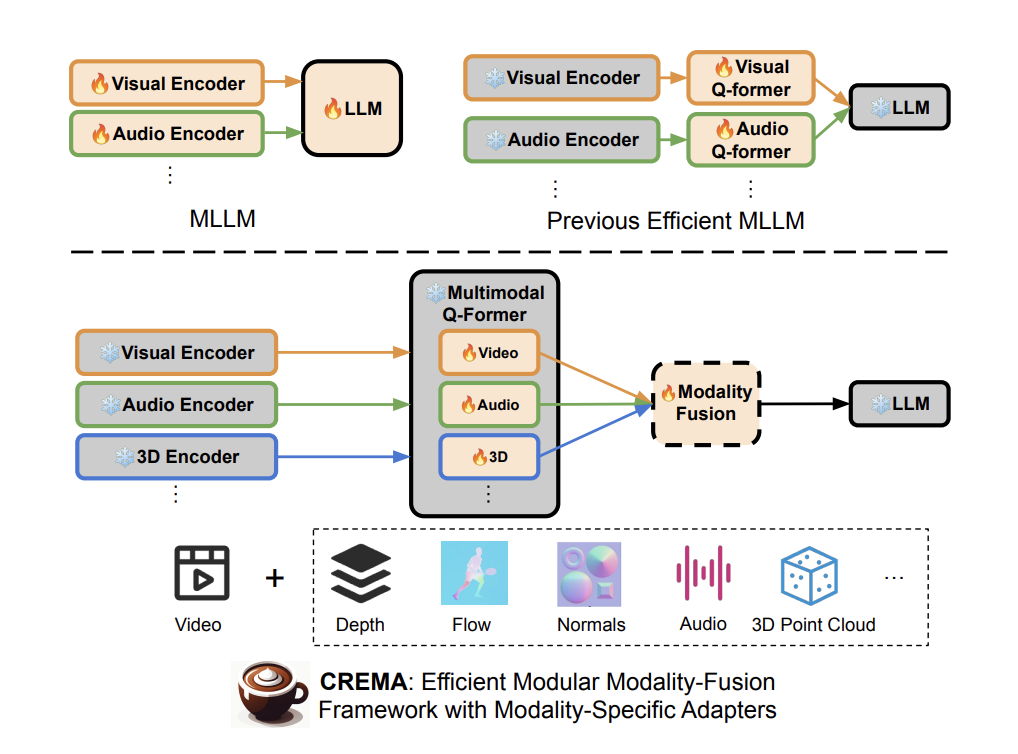
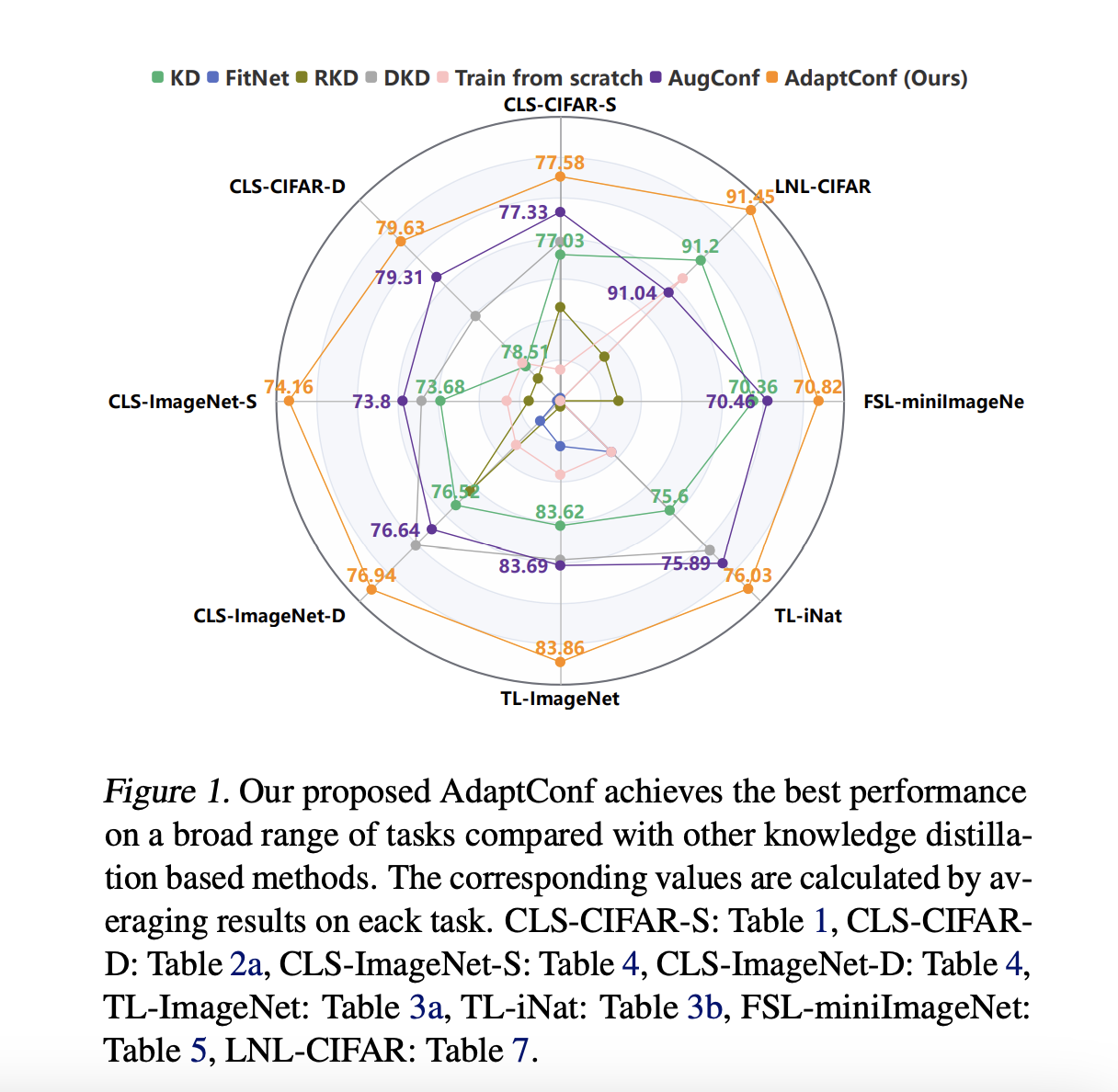
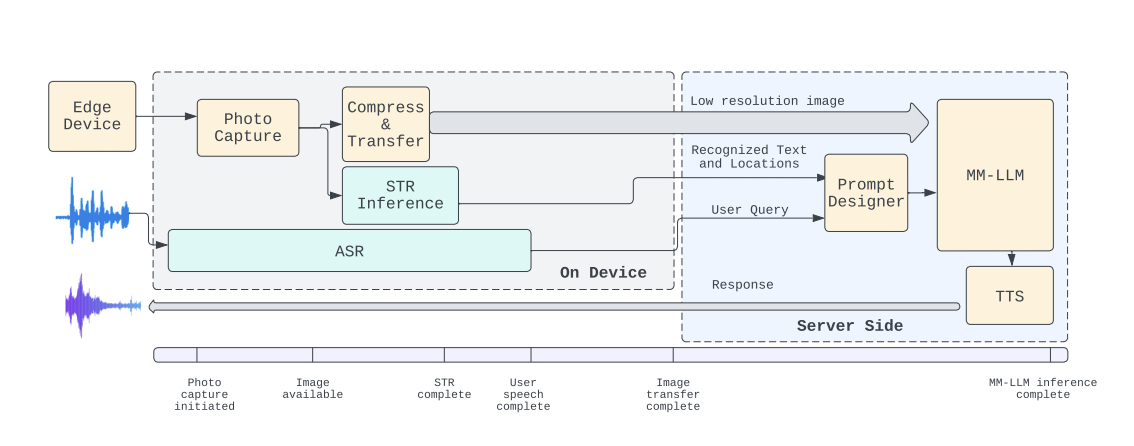
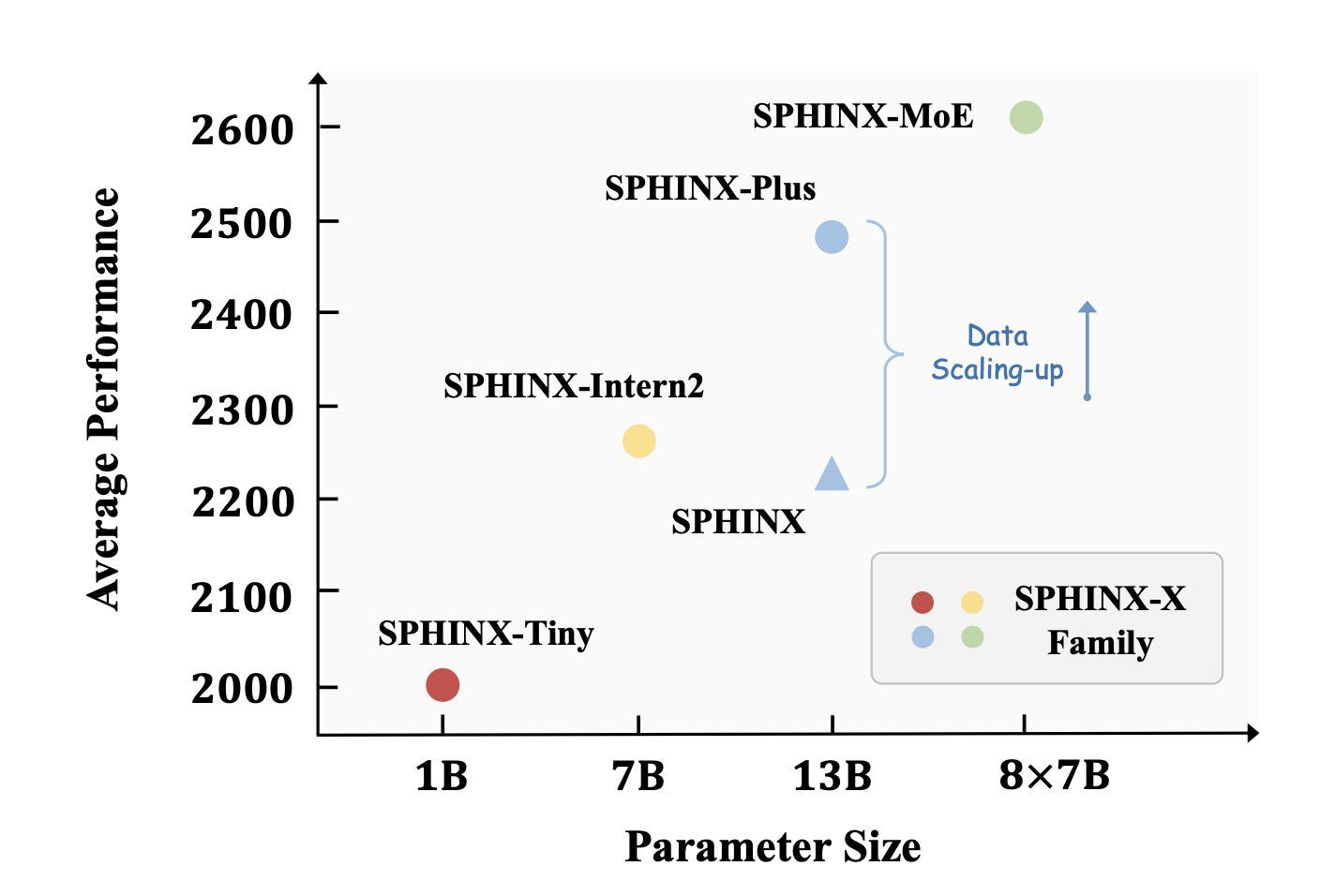
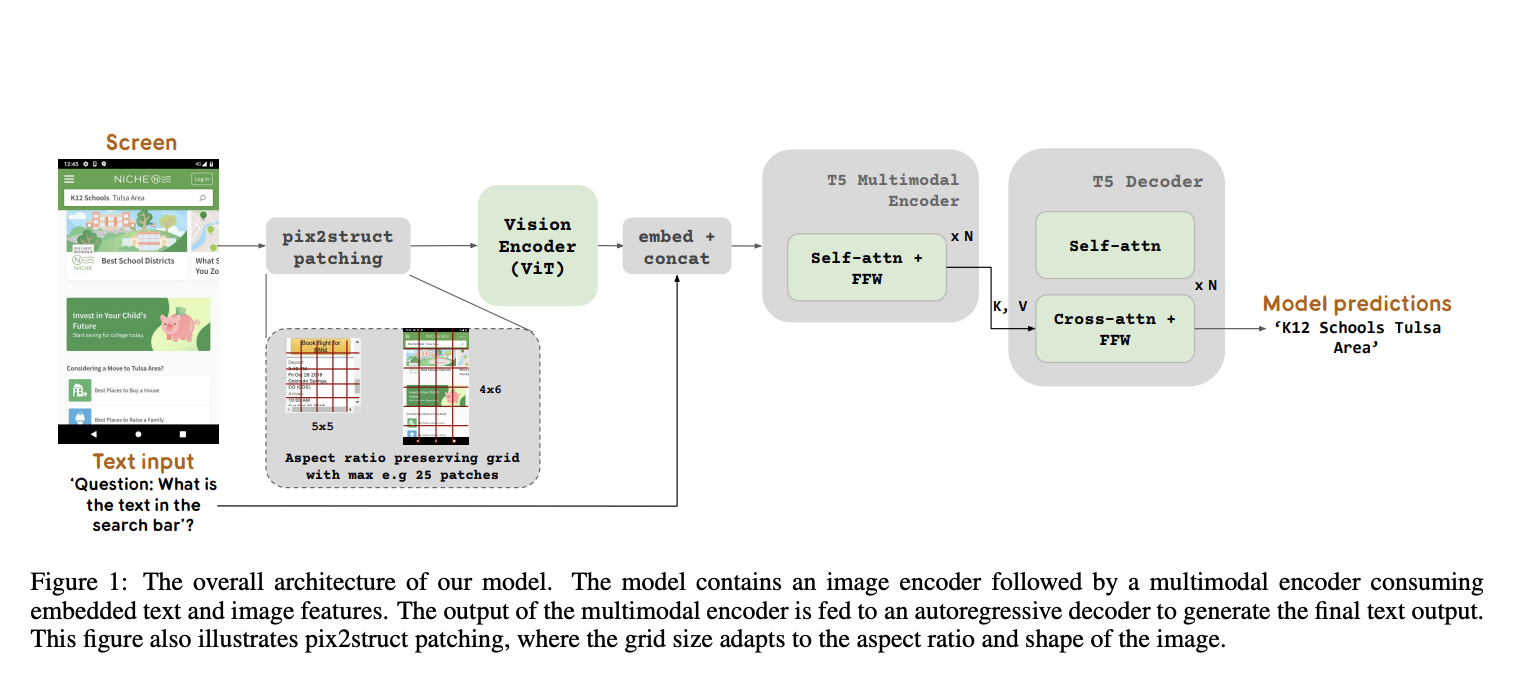
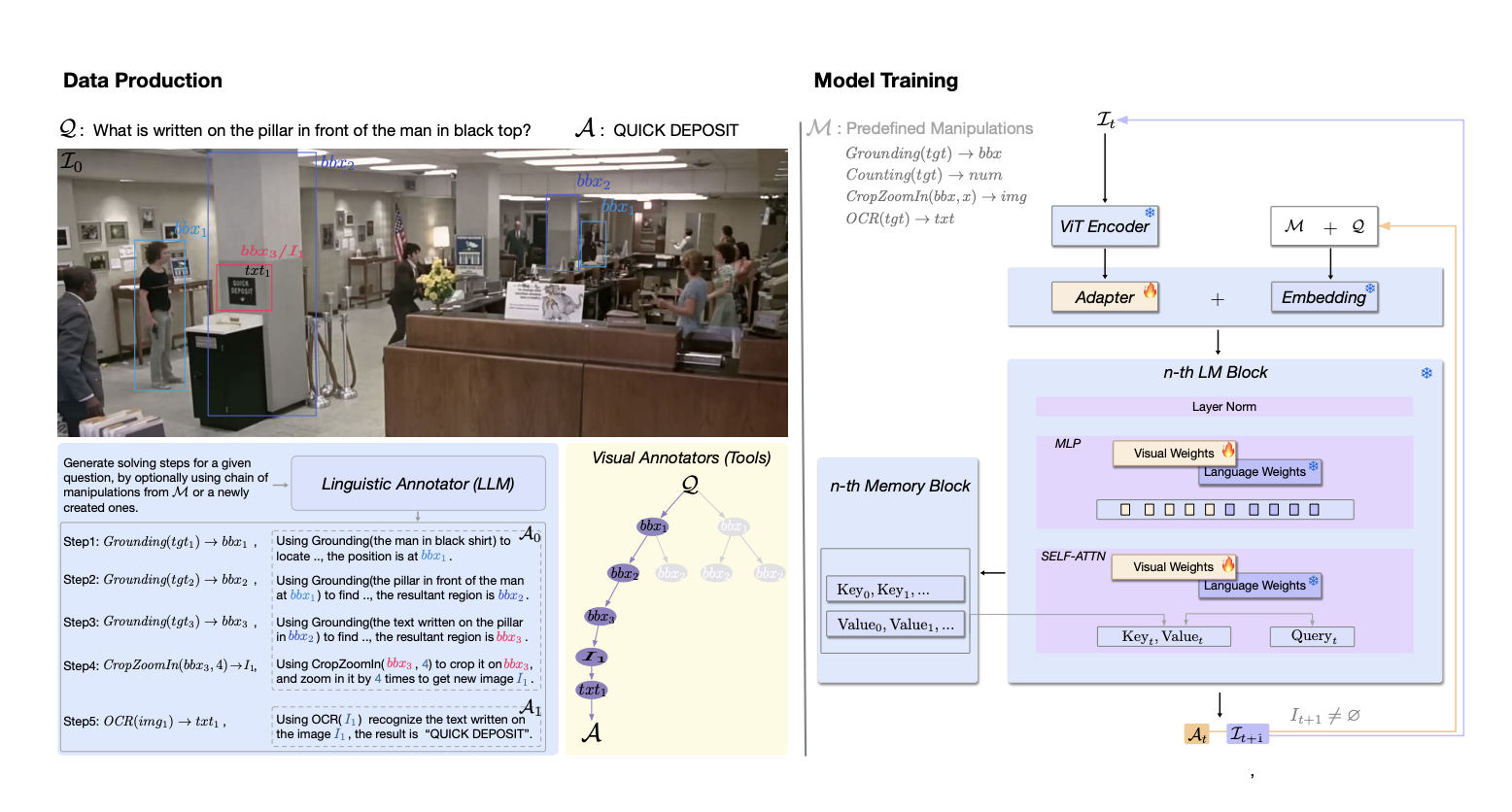
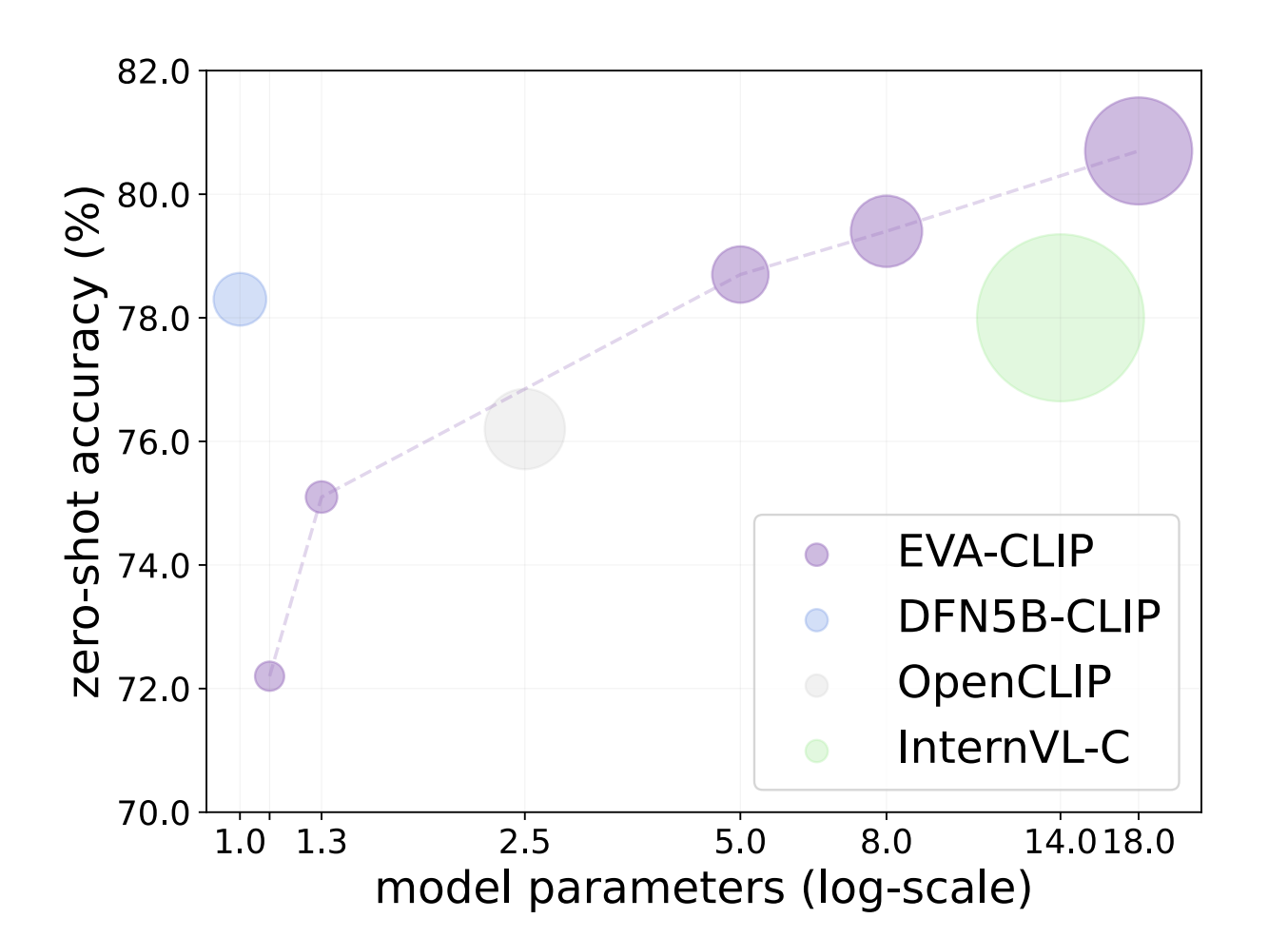
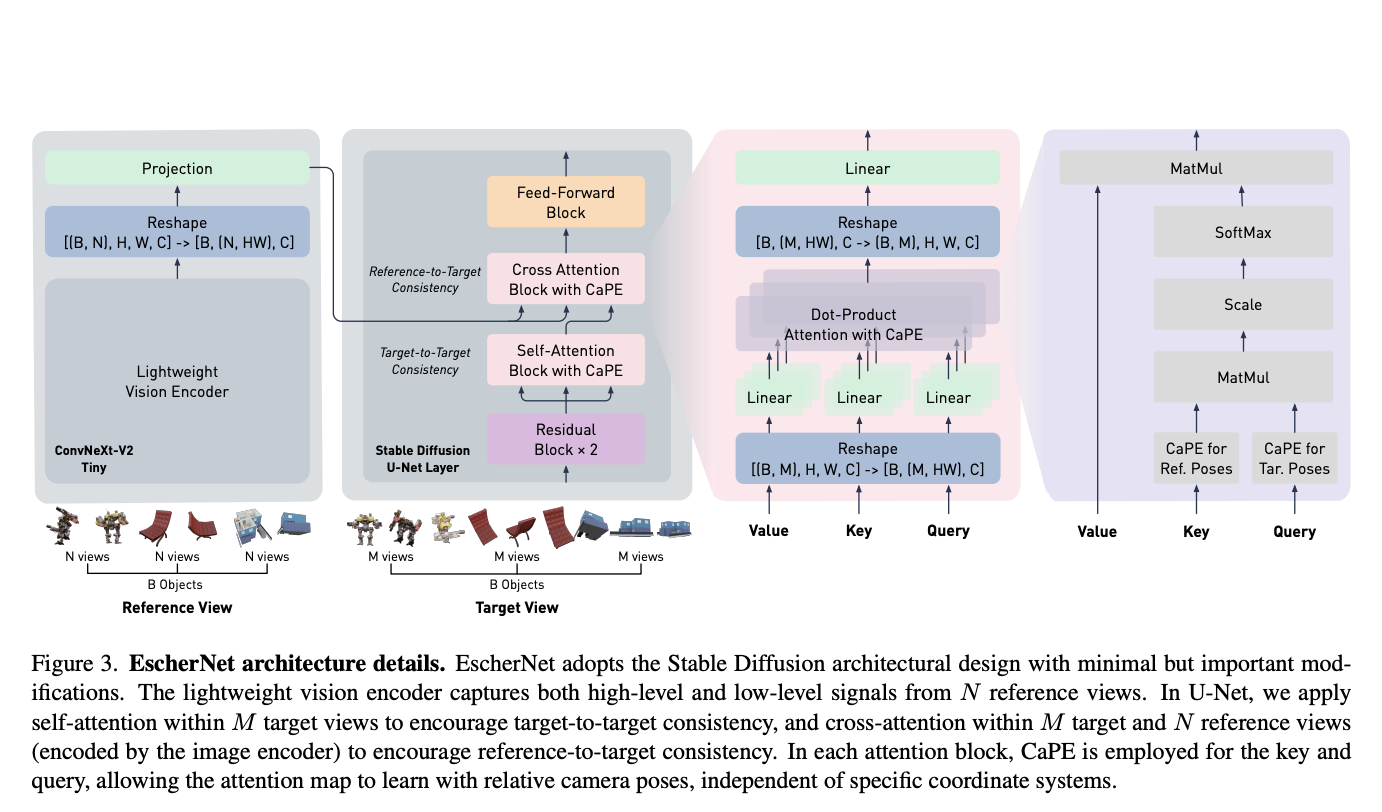
The landscape of image segmentation has been profoundly transformed by the introduction of the Segment Anything Model (SAM), a paradigm known for its remarkable zero-shot segmentation capability. SAM’s deployment across a wide array of applications, from augmented reality to data annotation, underscores its utility. However, SAM’s computational intensity, particularly its image encoder’s demand of 2973…