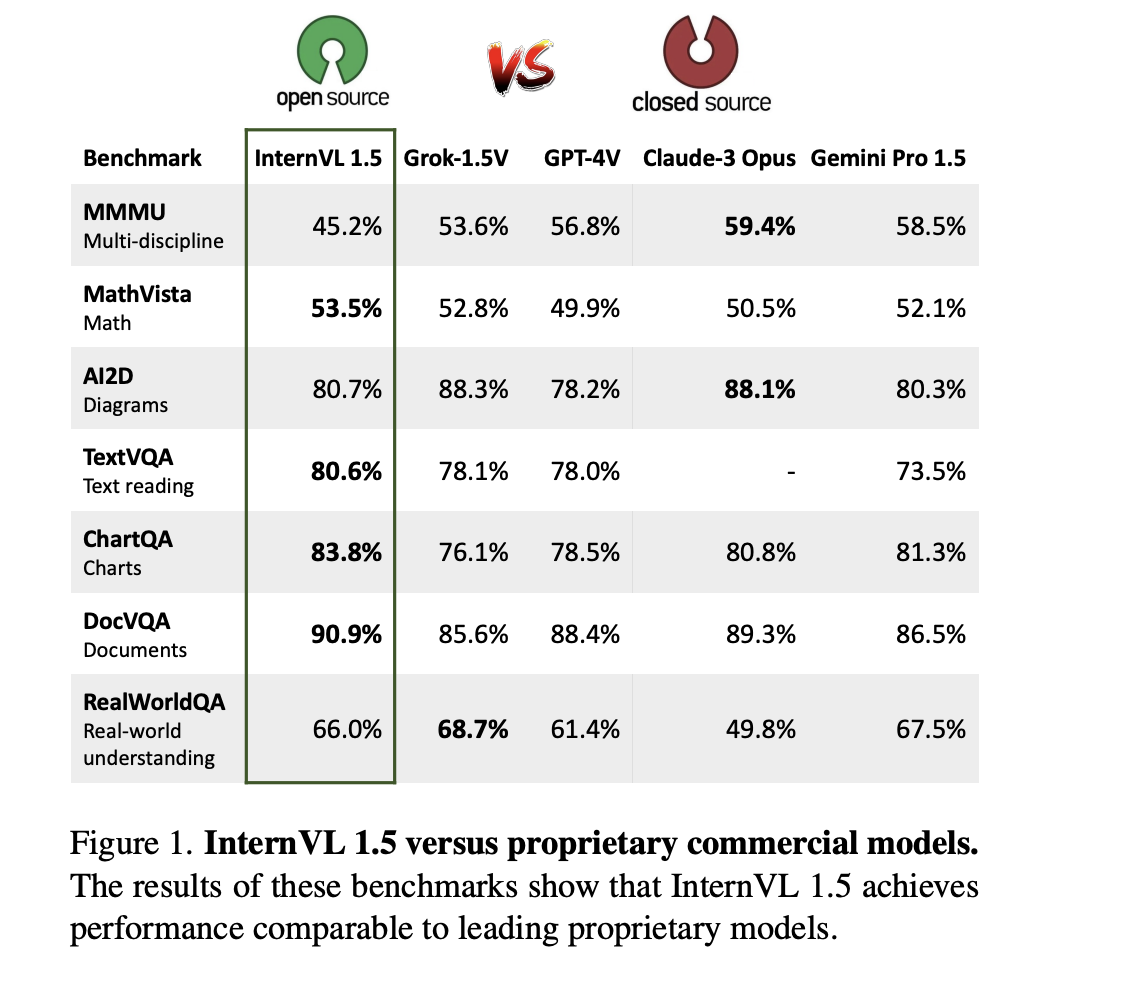
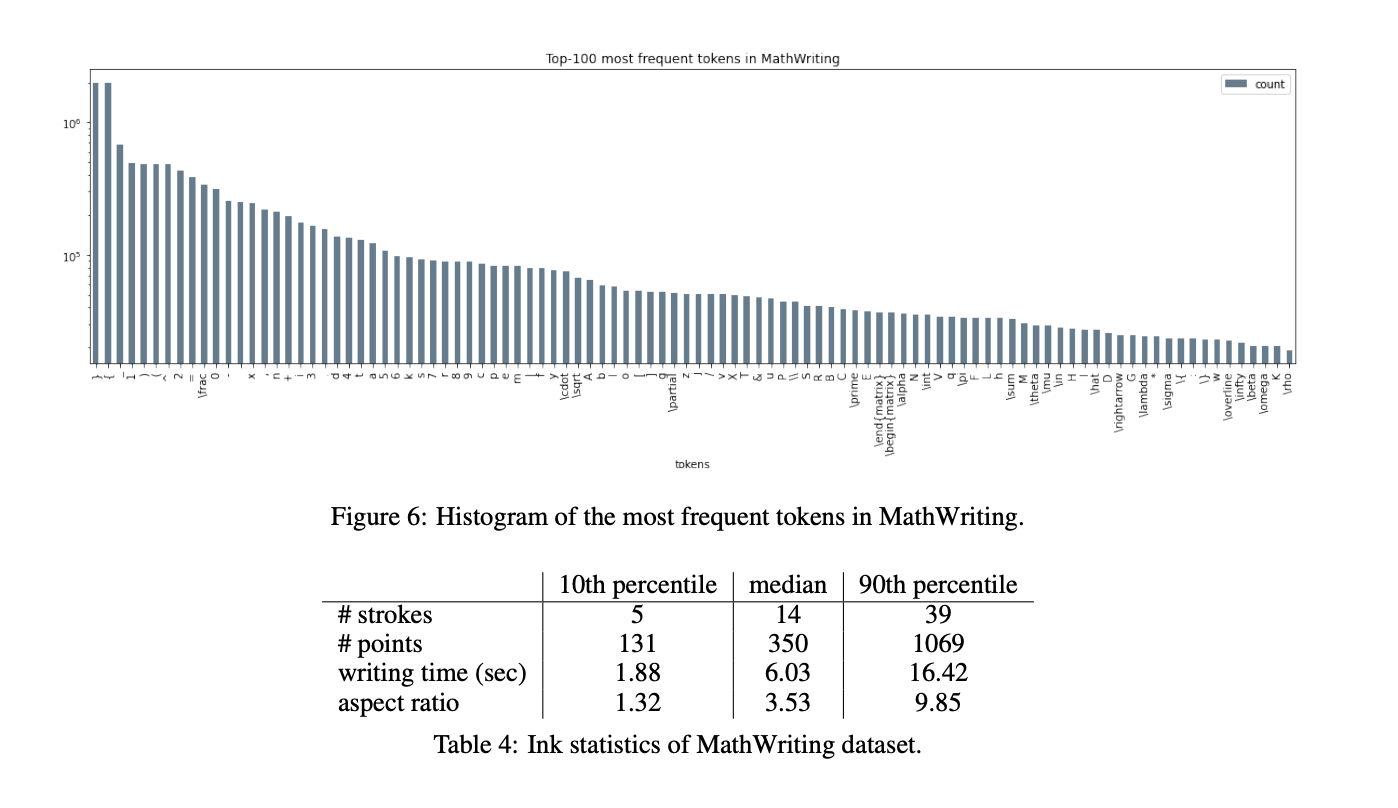
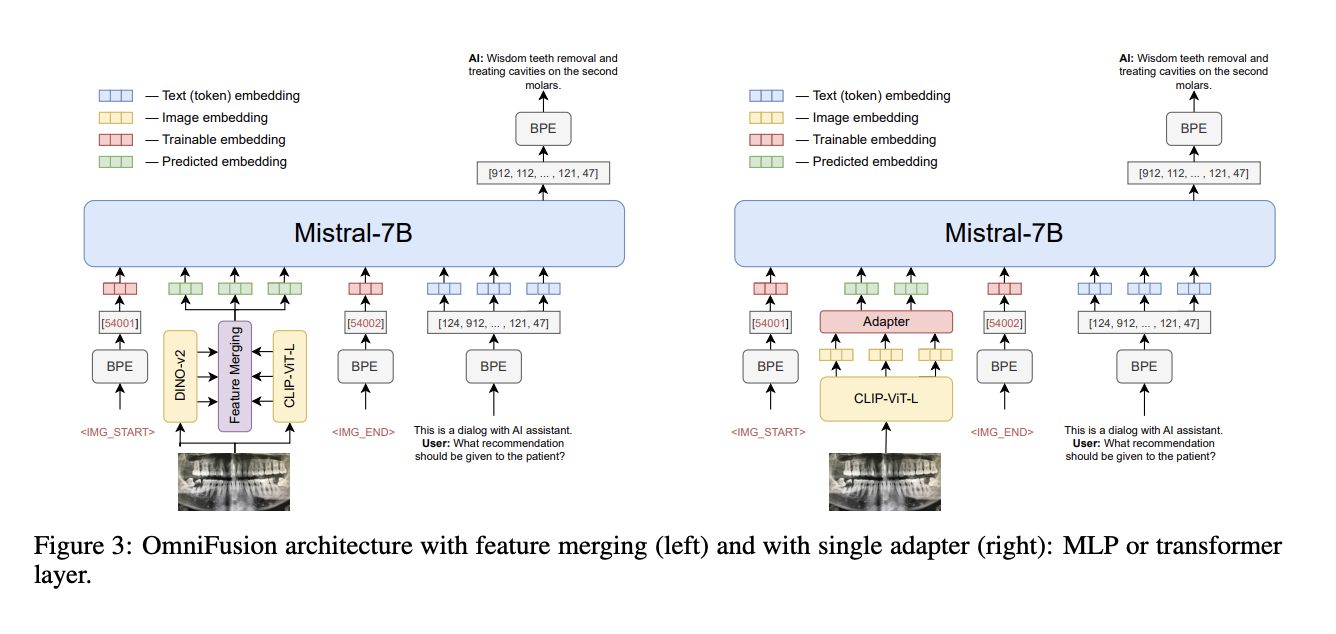
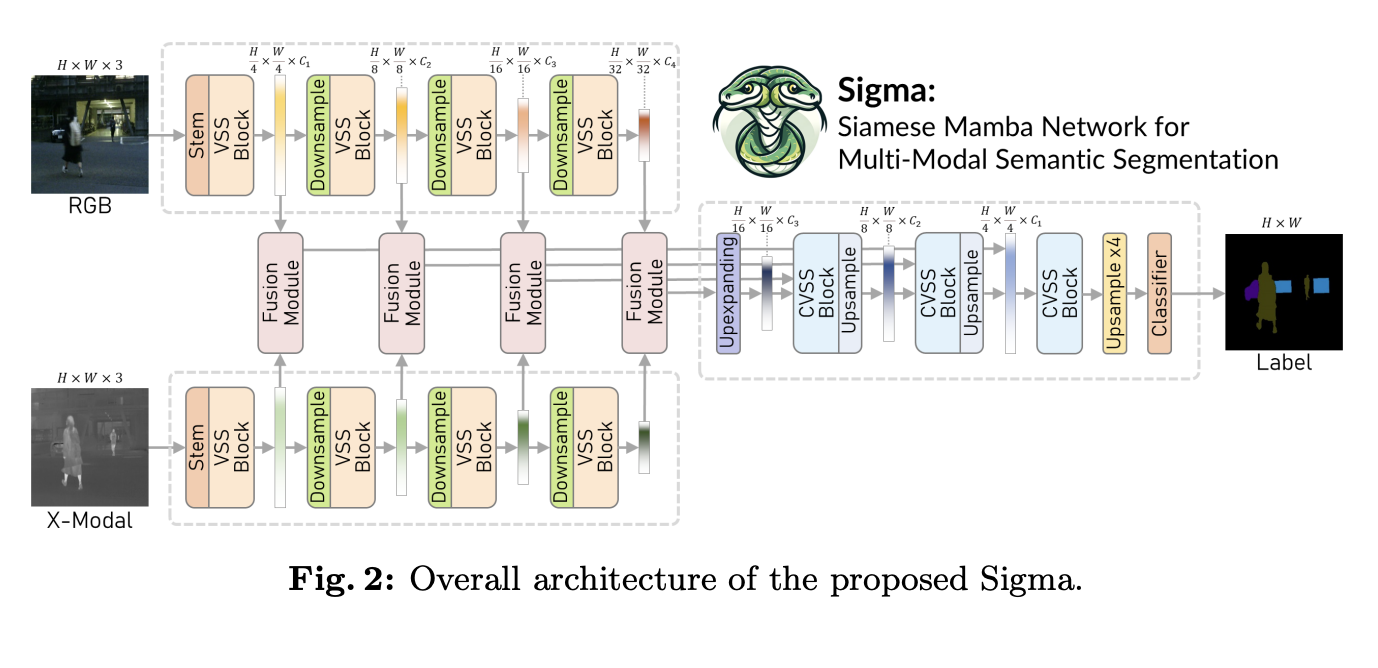
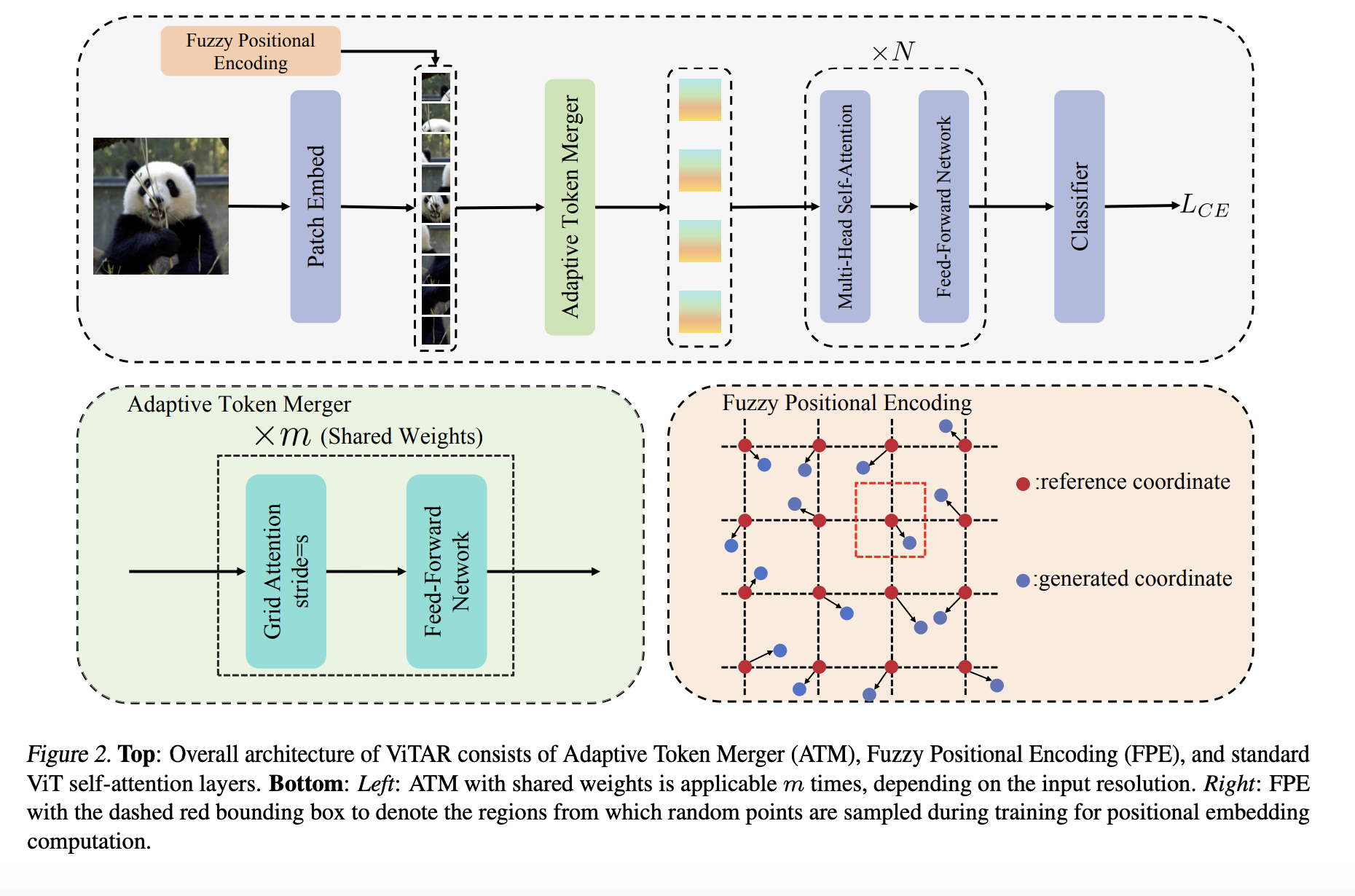
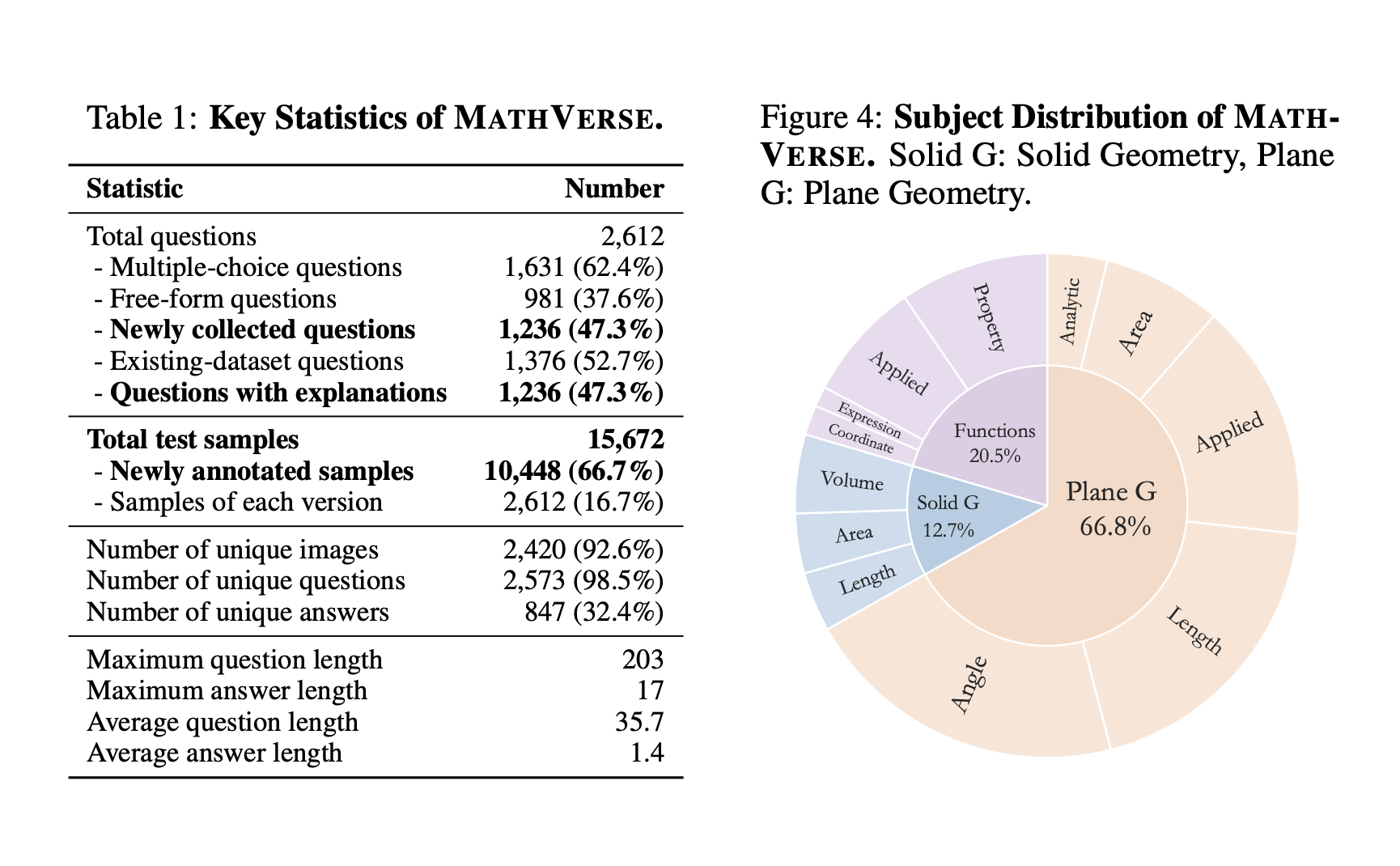
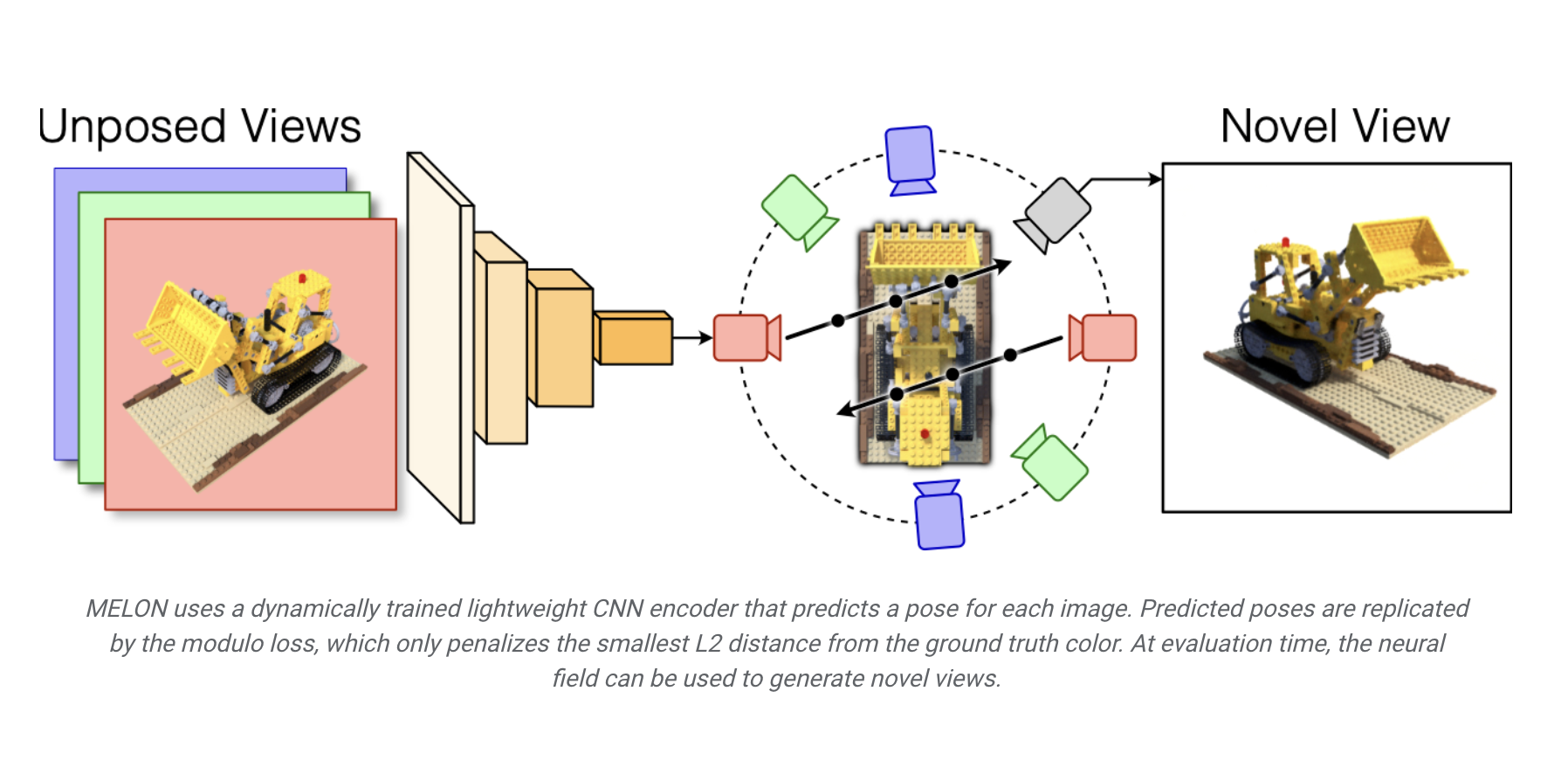
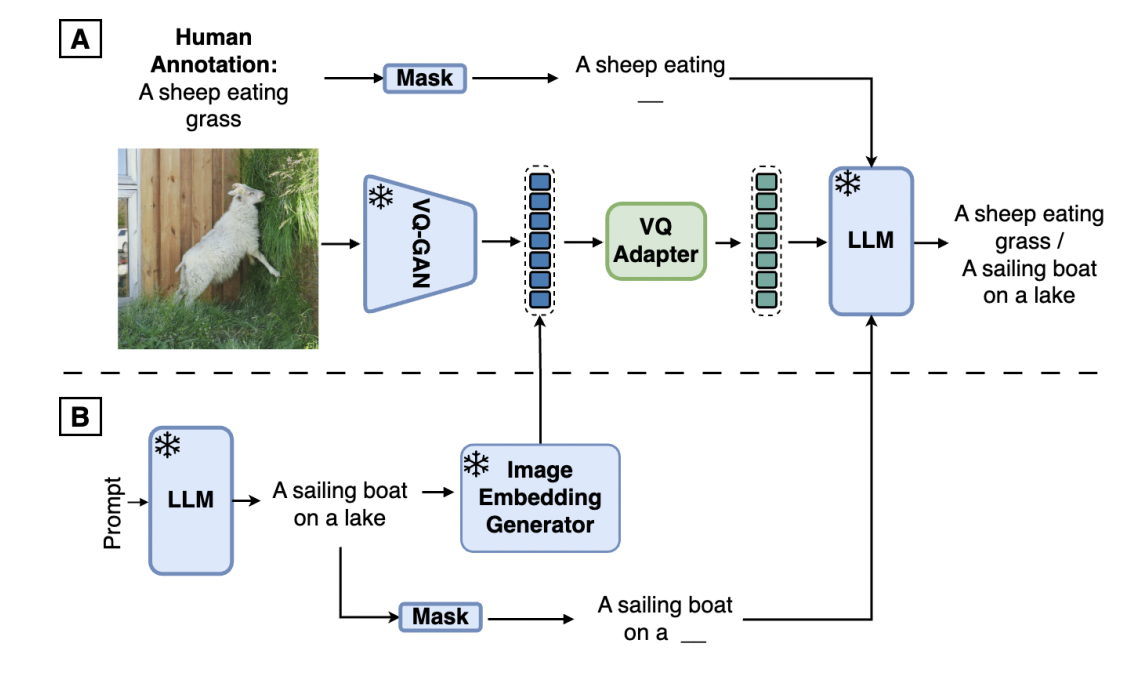
Multimodal large language models (MLLMs) integrate text and visual data processing to enhance how artificial intelligence understands and interacts with the world. This area of research focuses on creating systems that can comprehend and respond to a combination of visual cues and linguistic information, mimicking human-like interactions more closely.
The challenge often lies in the…