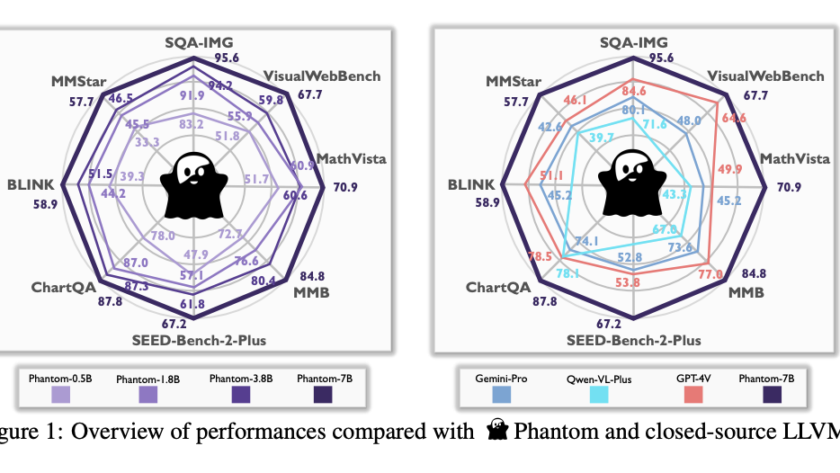
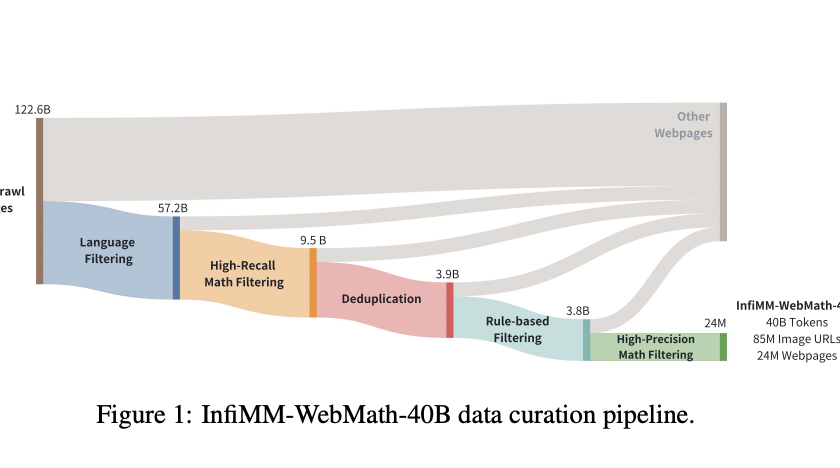
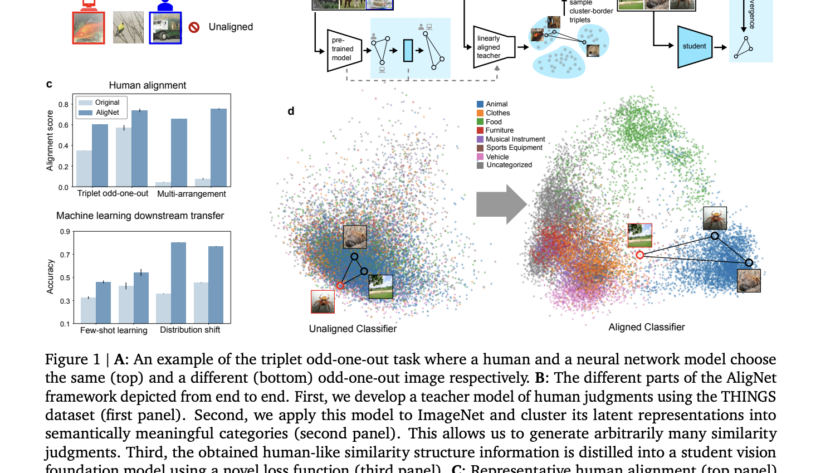
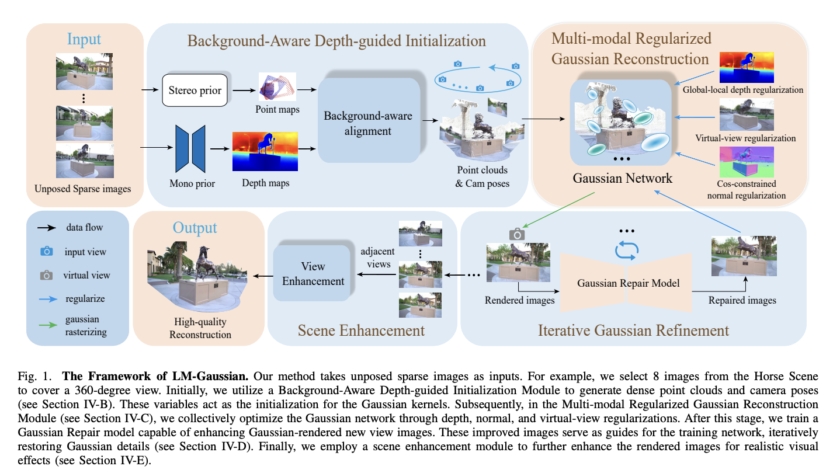
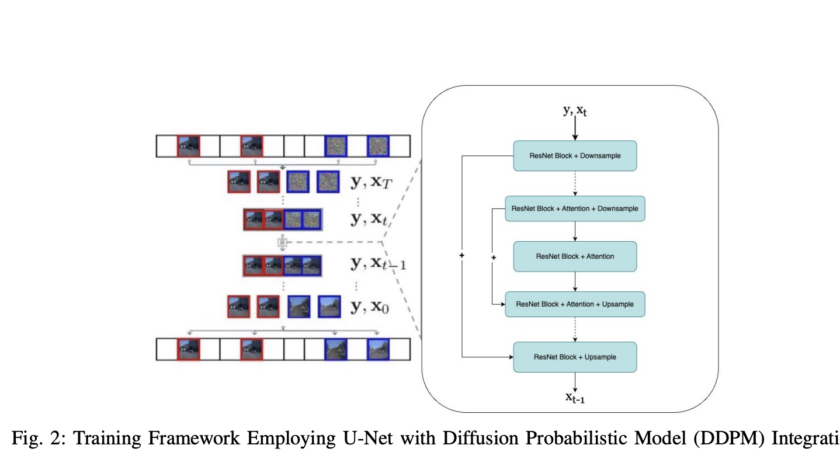
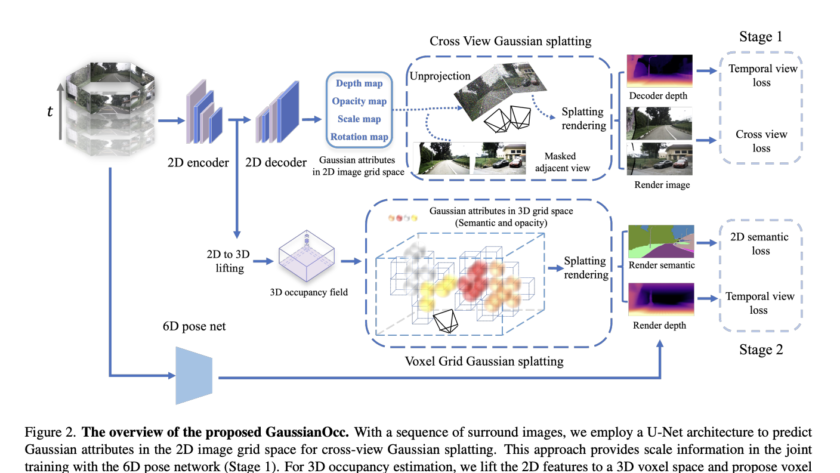
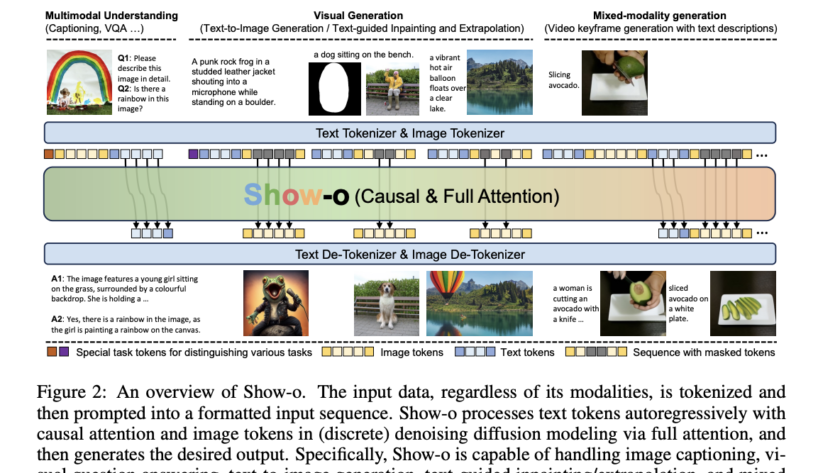
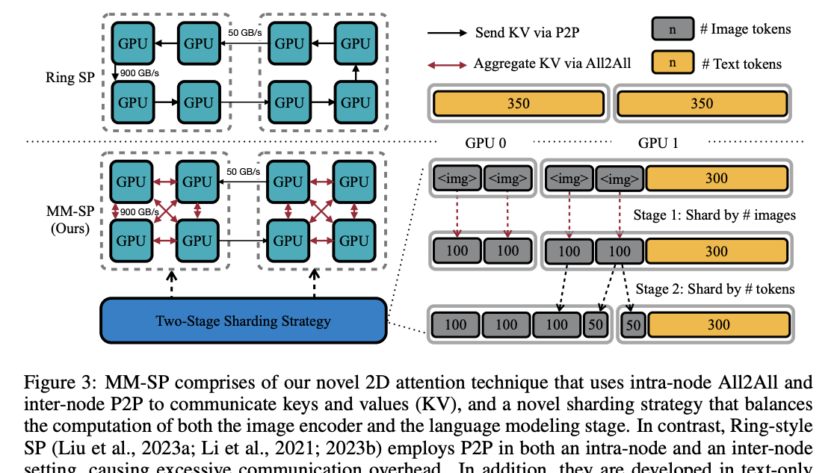
Large language and vision models (LLVMs) face a critical challenge in balancing performance improvements with computational efficiency. As models grow in size, reaching up to 80B parameters, they deliver impressive results but require massive hardware resources for training and inference. This issue becomes even more pressing for real-time applications, such as augmented reality (AR), where…