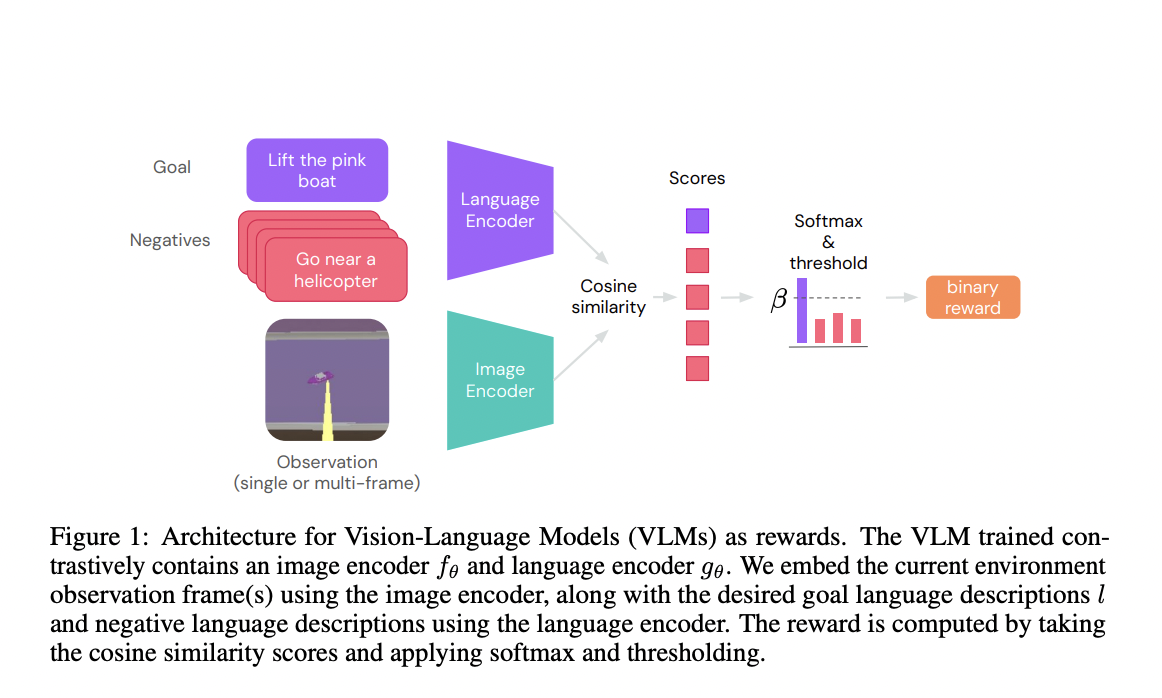
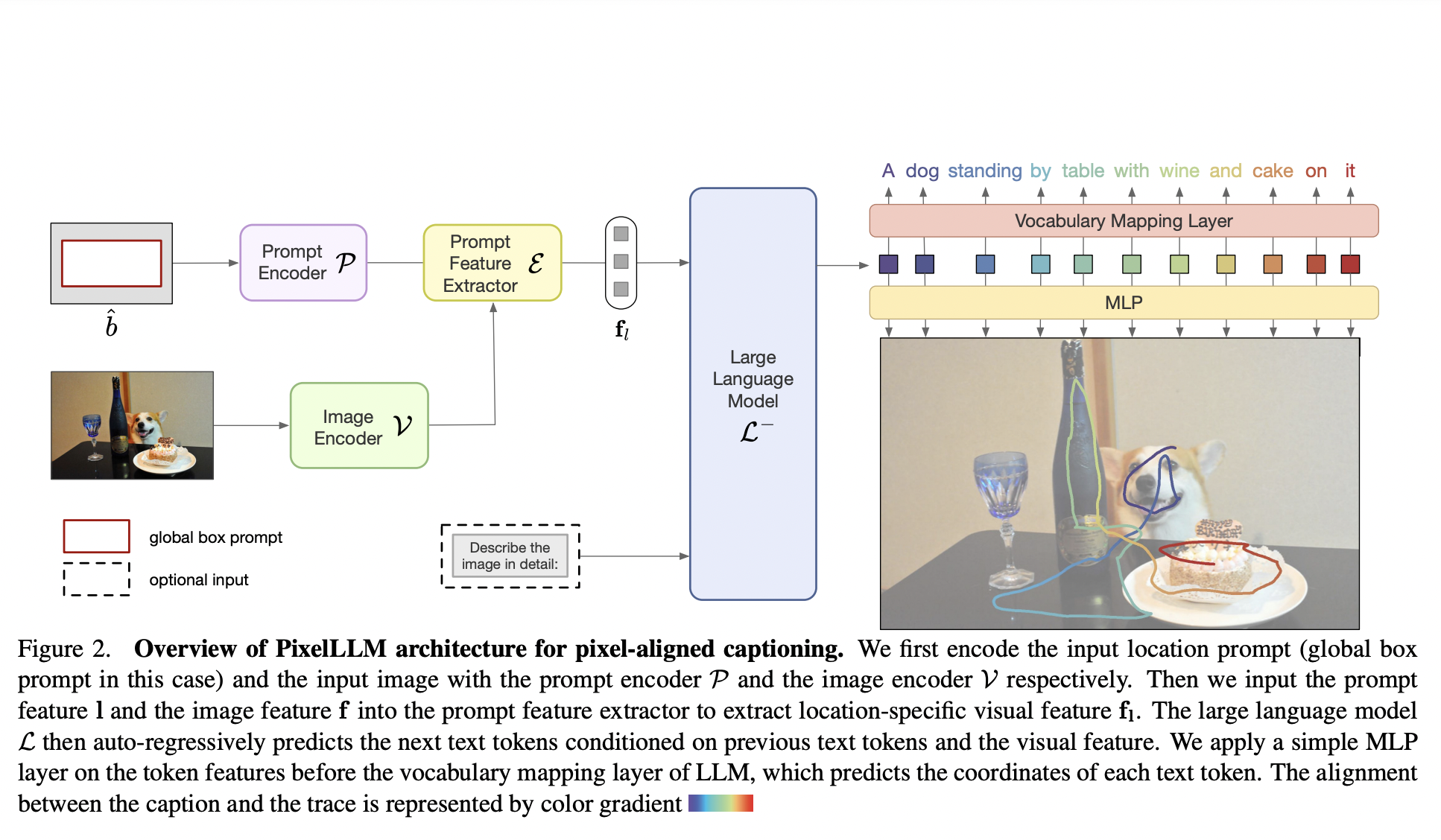
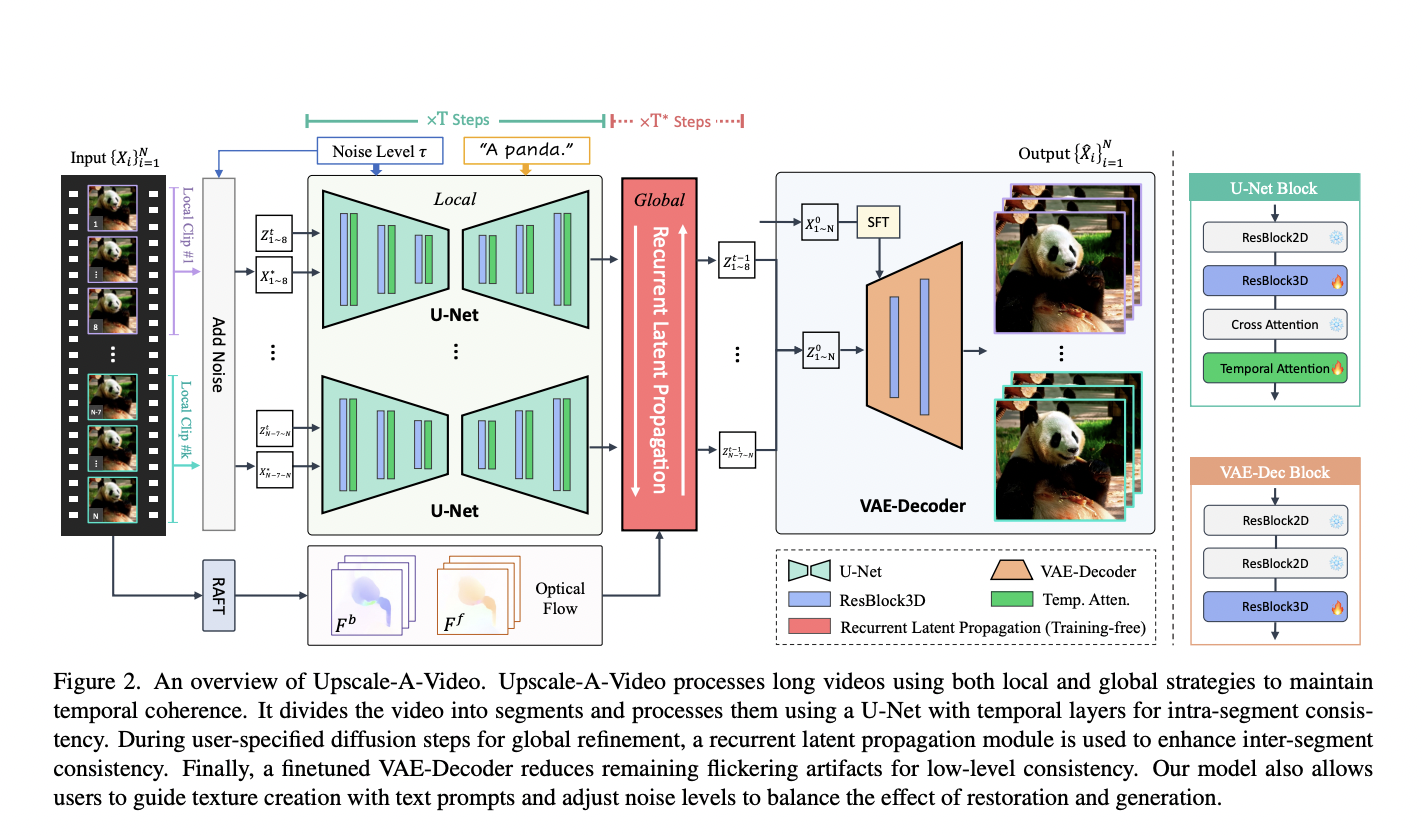
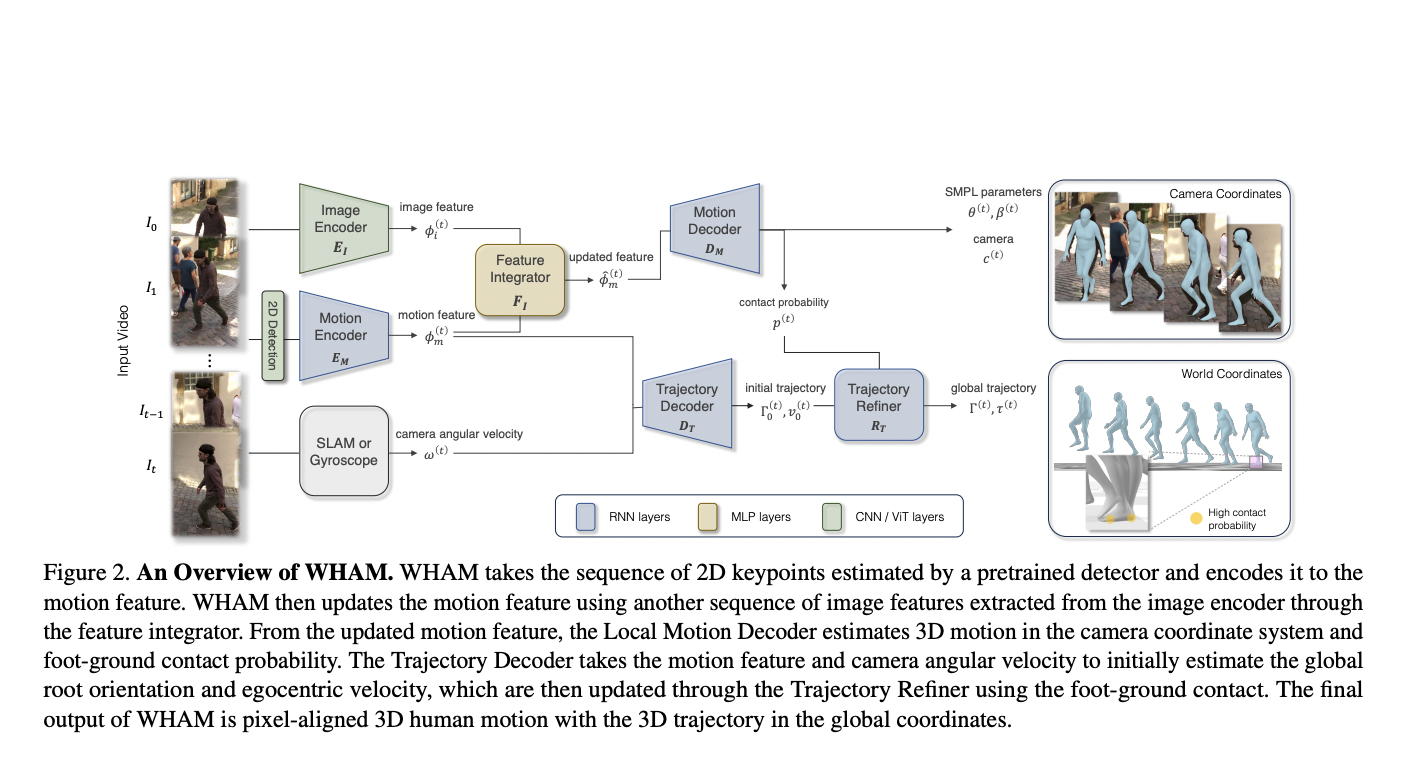
Reinforcement learning (RL) agents epitomize artificial intelligence by embodying adaptive prowess, navigating intricate knowledge landscapes through iterative trial and error, and dynamically assimilating environmental insights to autonomously evolve and optimize their decision-making capabilities. Developing generalist RL agents that can perform diverse tasks in complex environments is a challenging task that requires numerous reward functions. However,…