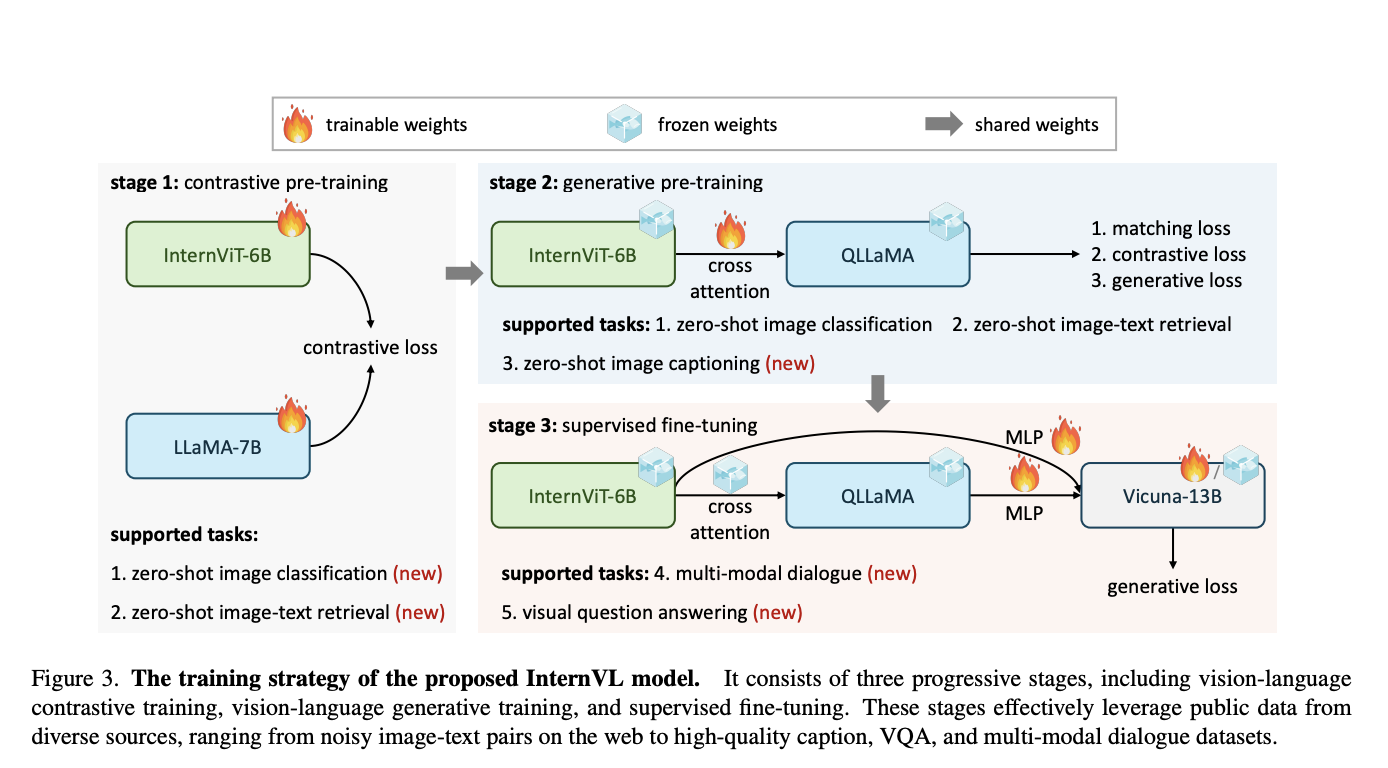
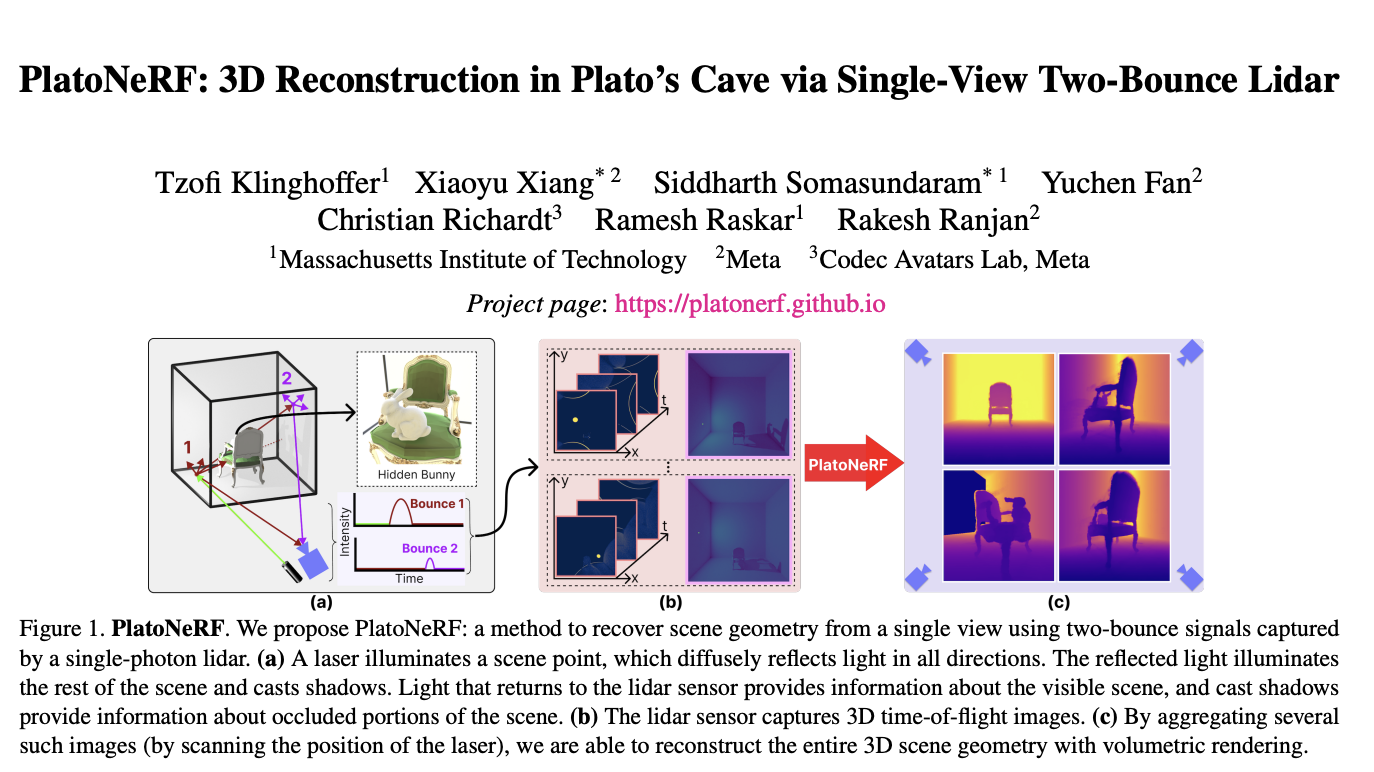
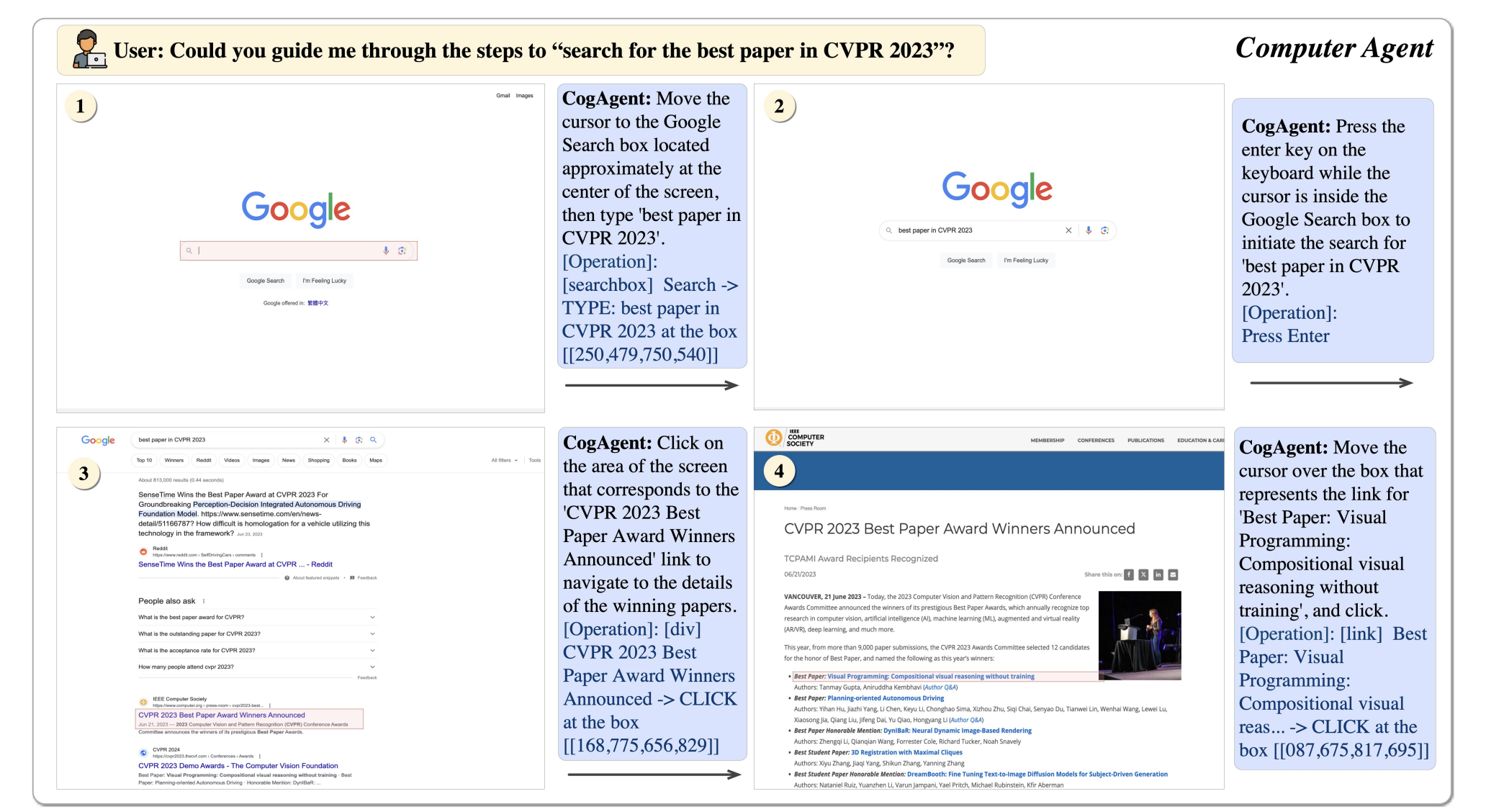
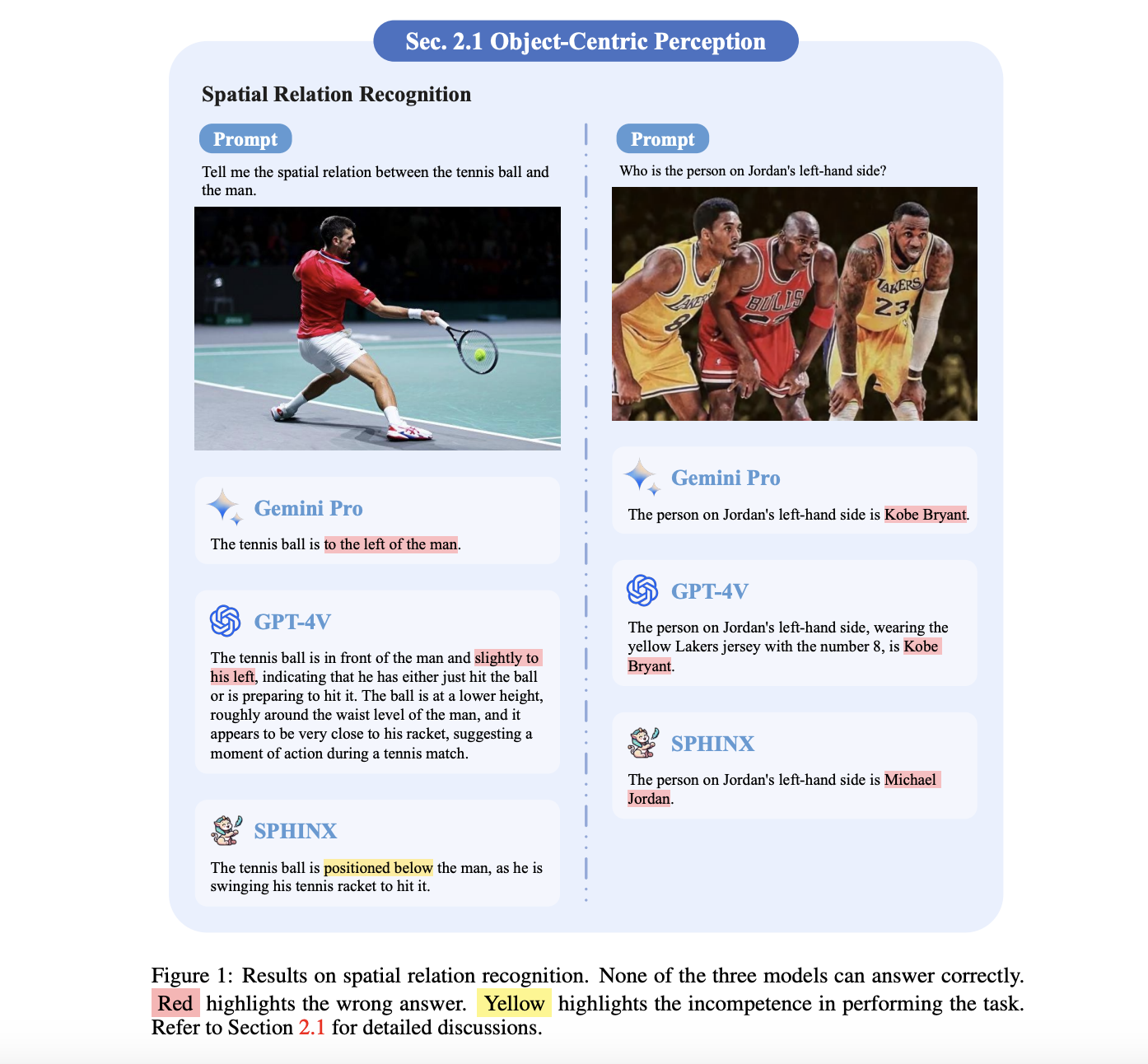
The seamless integration of vision and language has been a focal point of recent advancements in AI. The field has seen significant progress with the advent of LLMs. Yet, developing vision and vision-language foundation models essential for multimodal AGI systems still need to catch up. This gap has led to the creation of a groundbreaking…