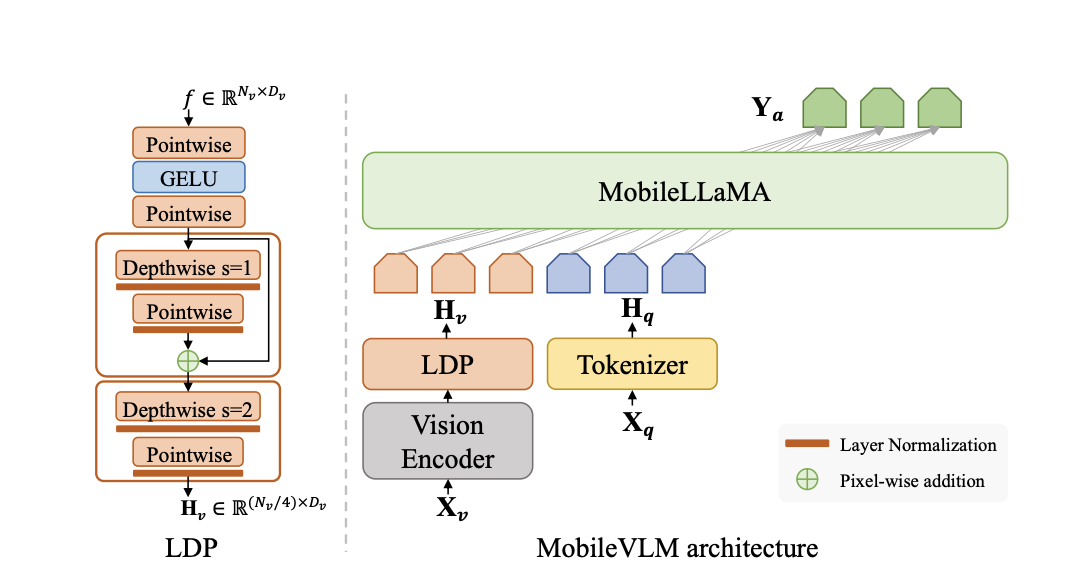
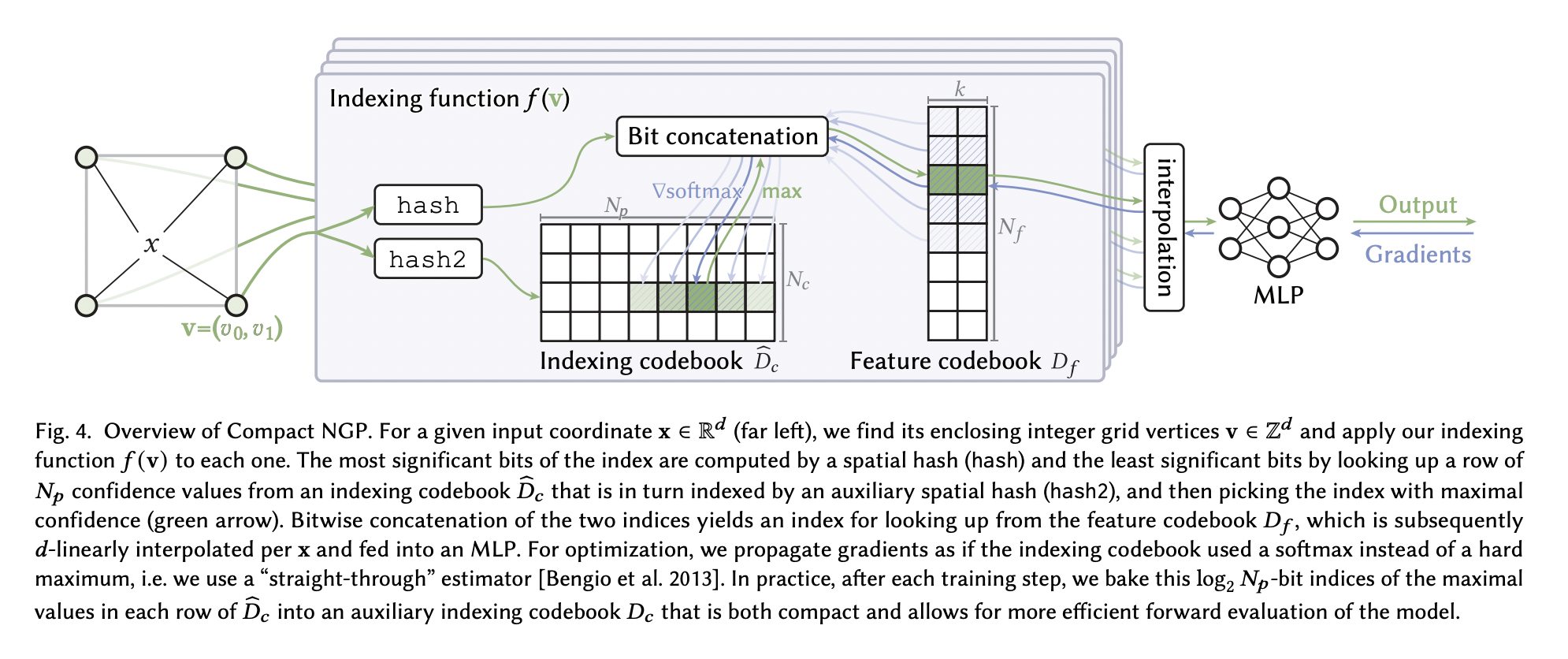
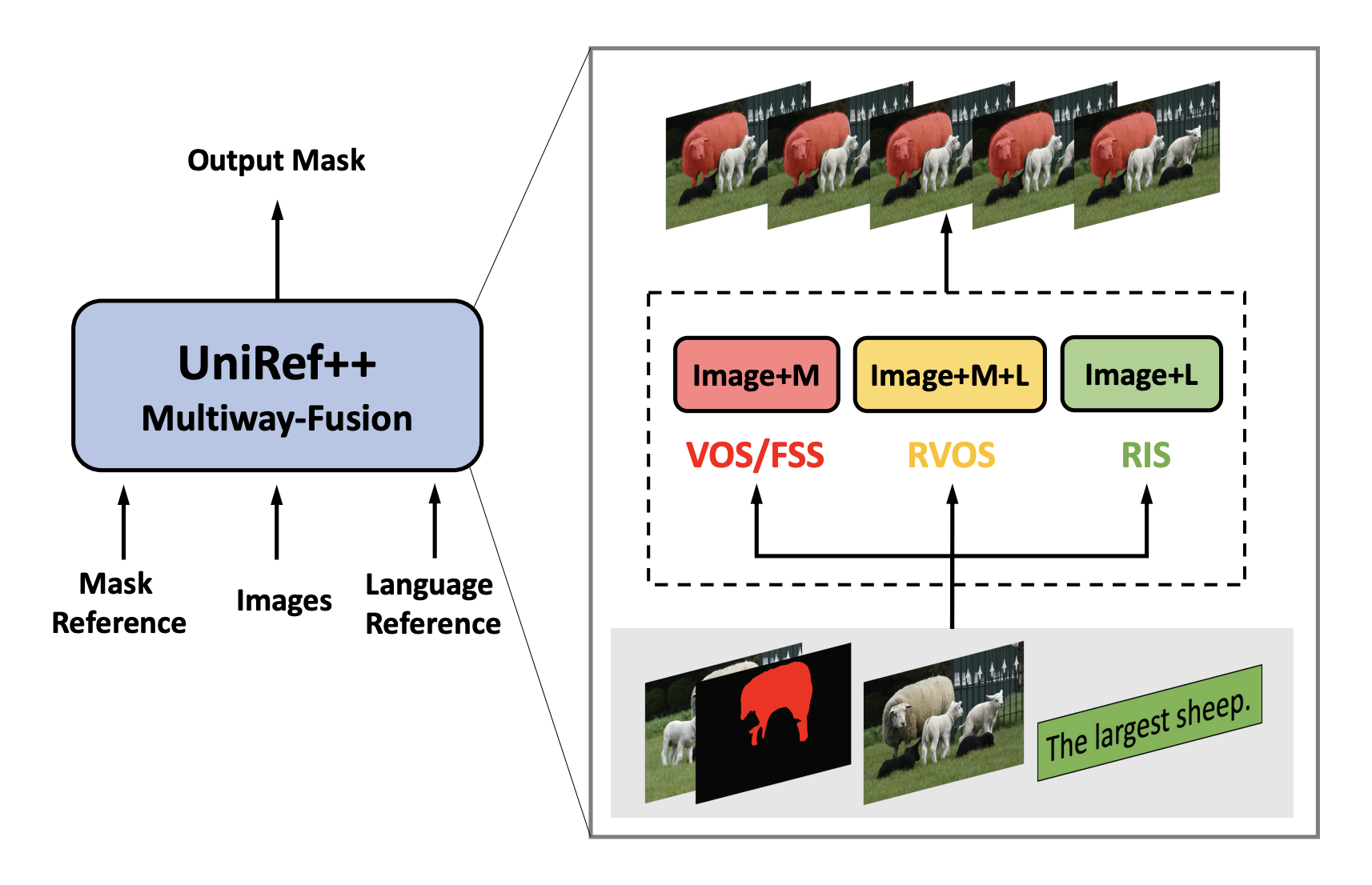
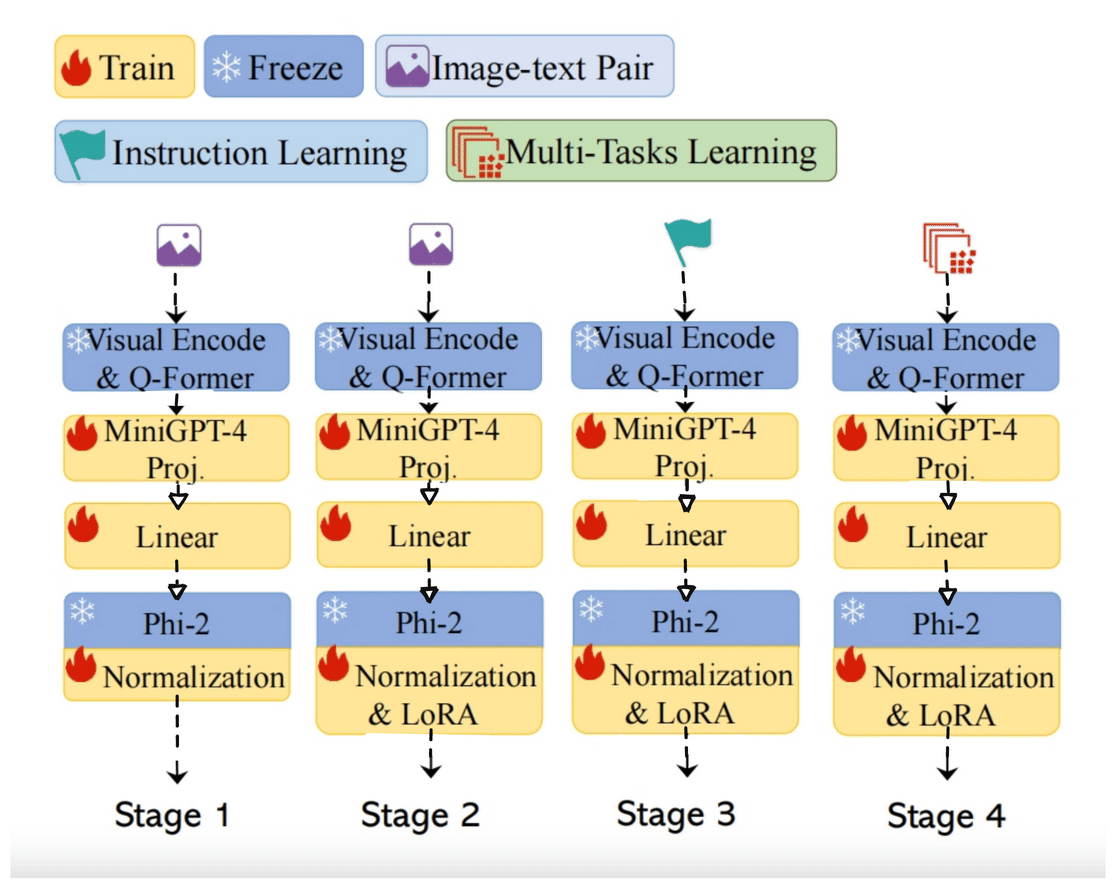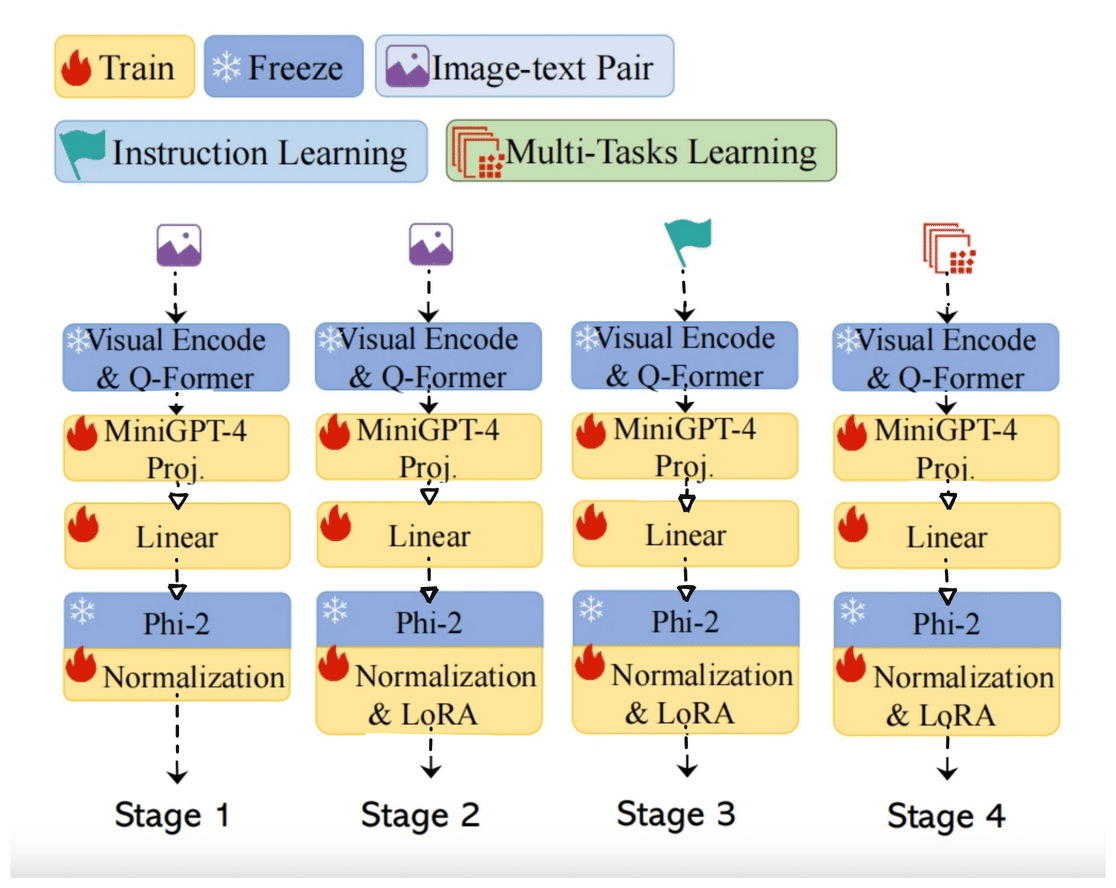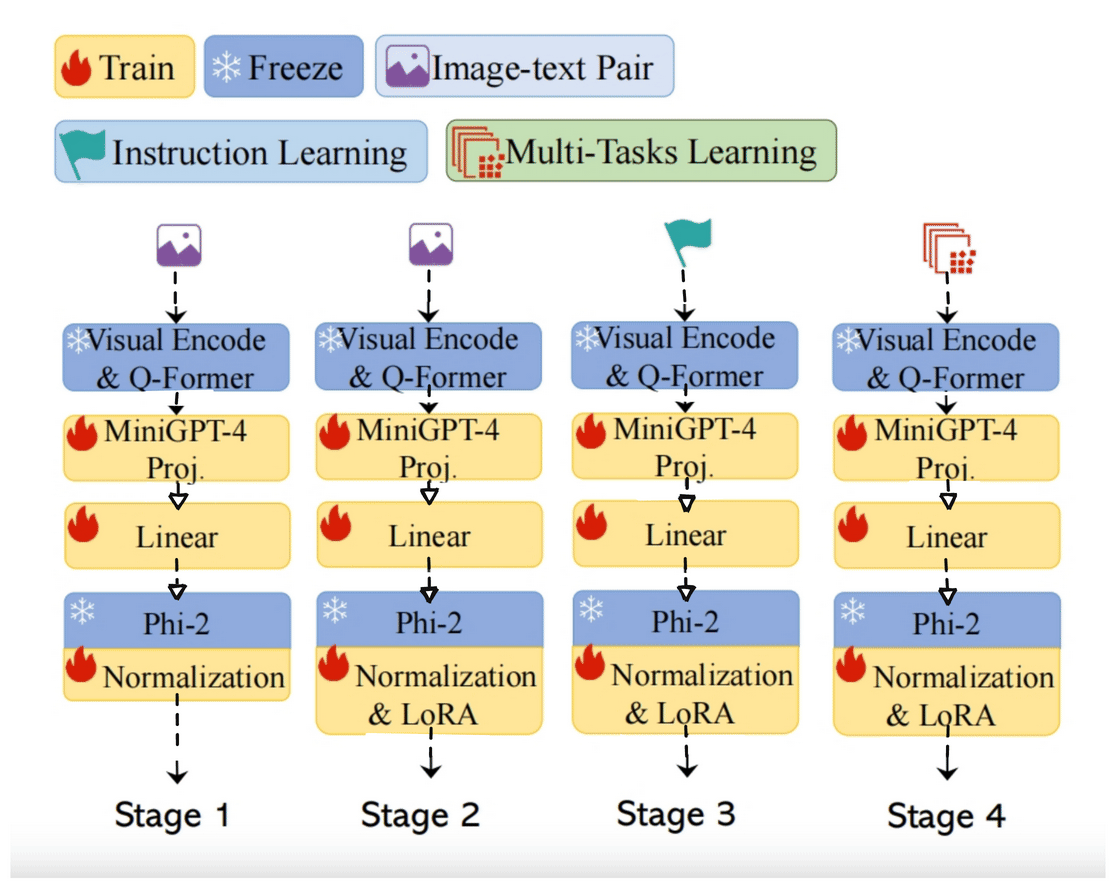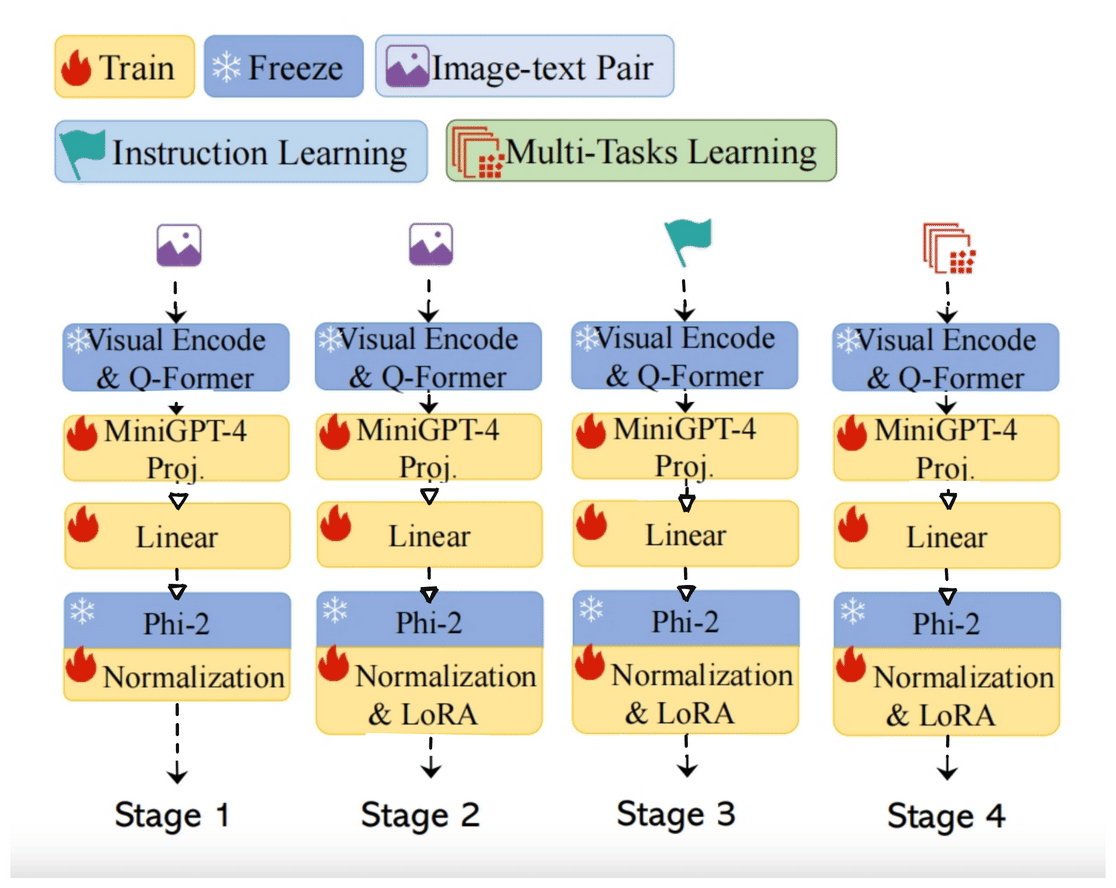
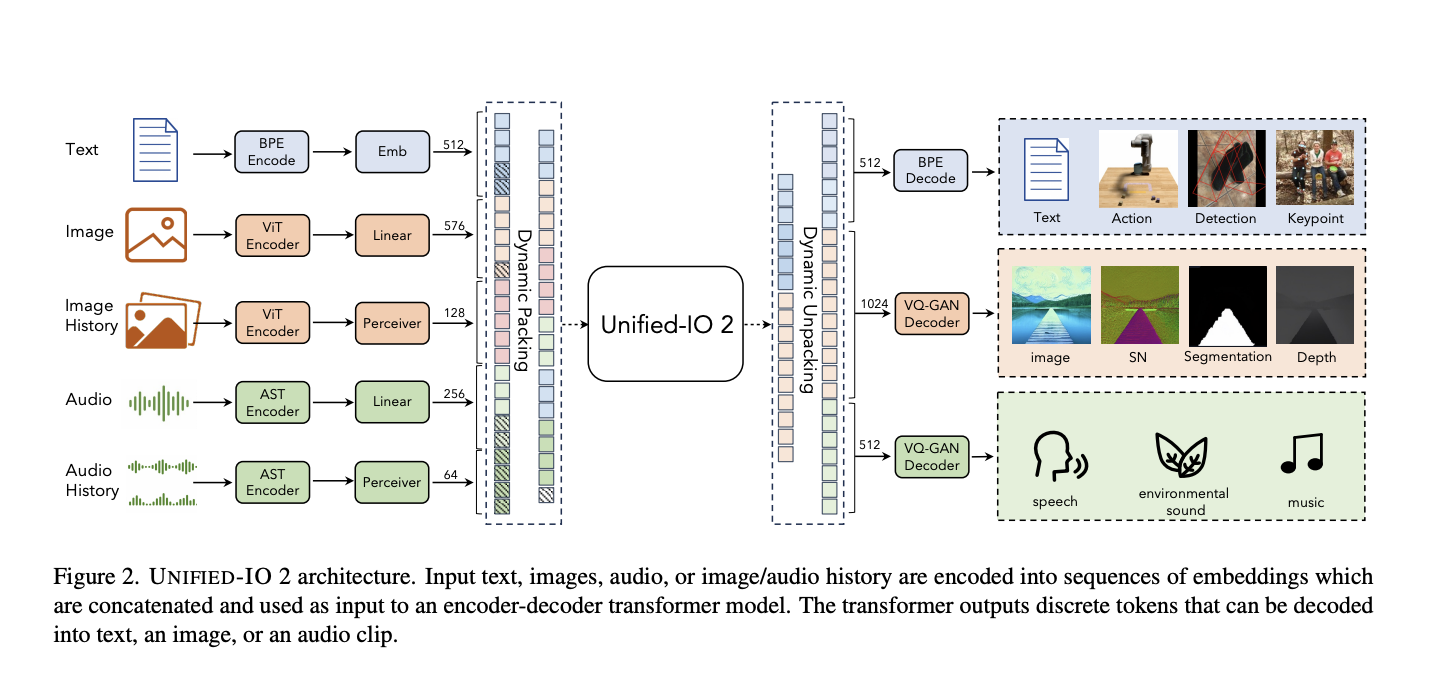
Raw and frequently unlabeled data can be retrieved and organized using representation learning. The ability of the model to develop a good representation depends on the quantity, quality, and diversity of the data. In doing so, the model mirrors the data’s inherent collective intelligence. The output is directly proportional to the input. Unsurprisingly, the most…