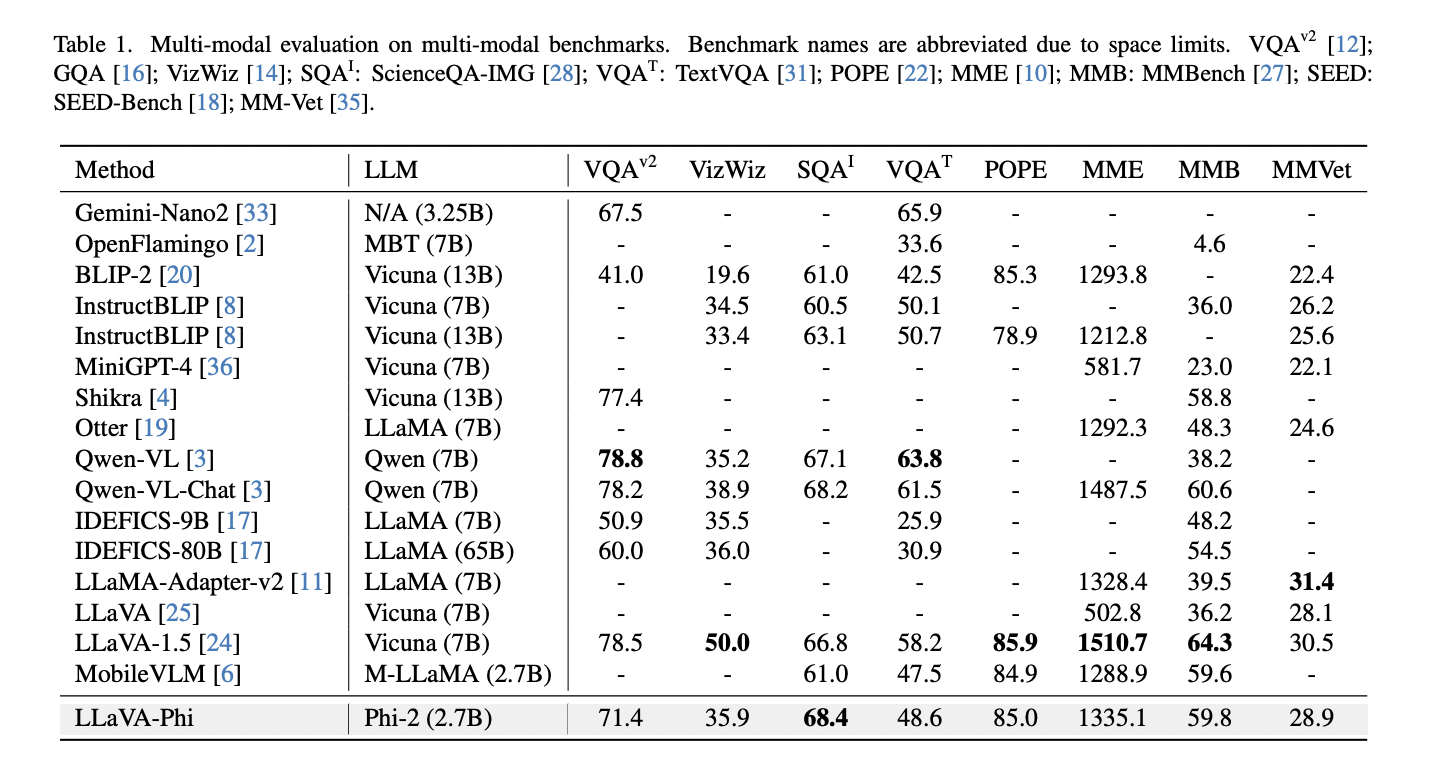
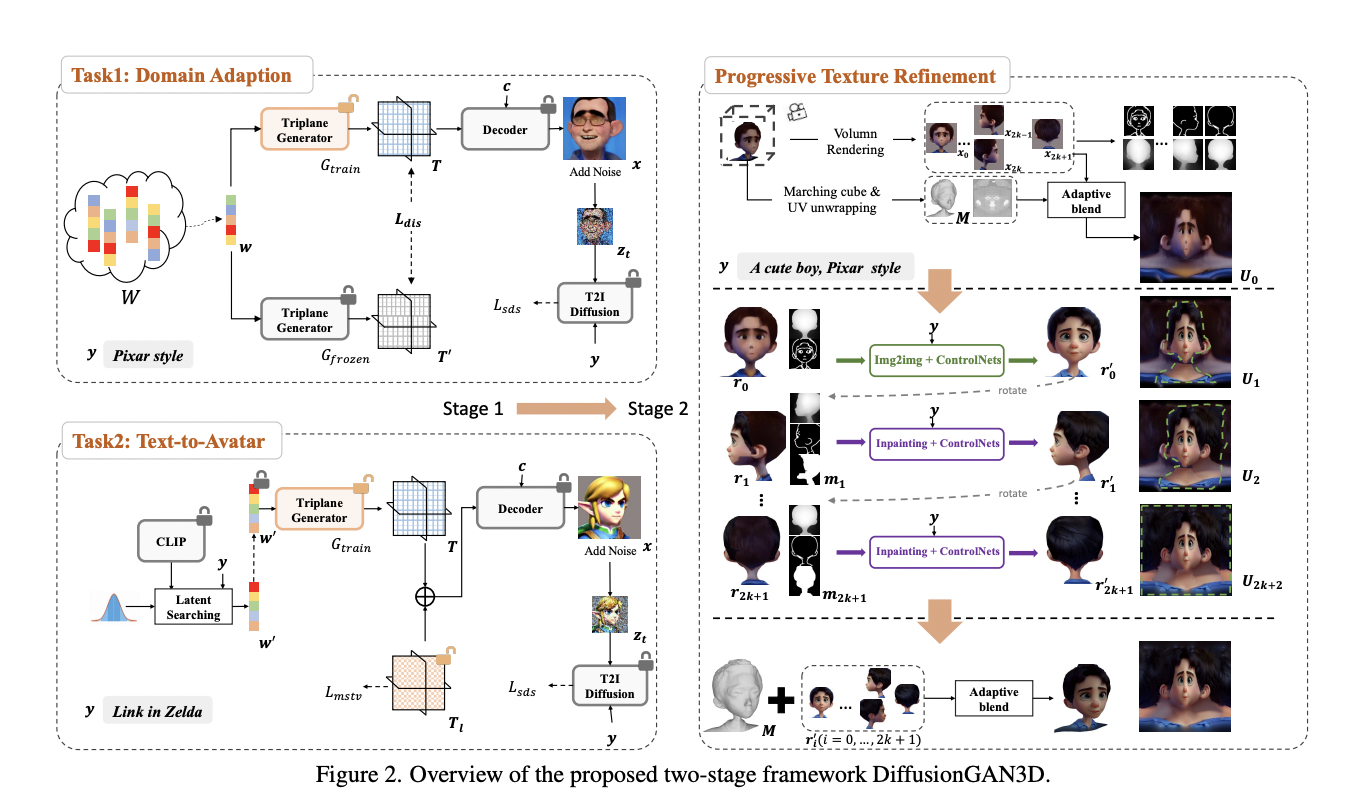
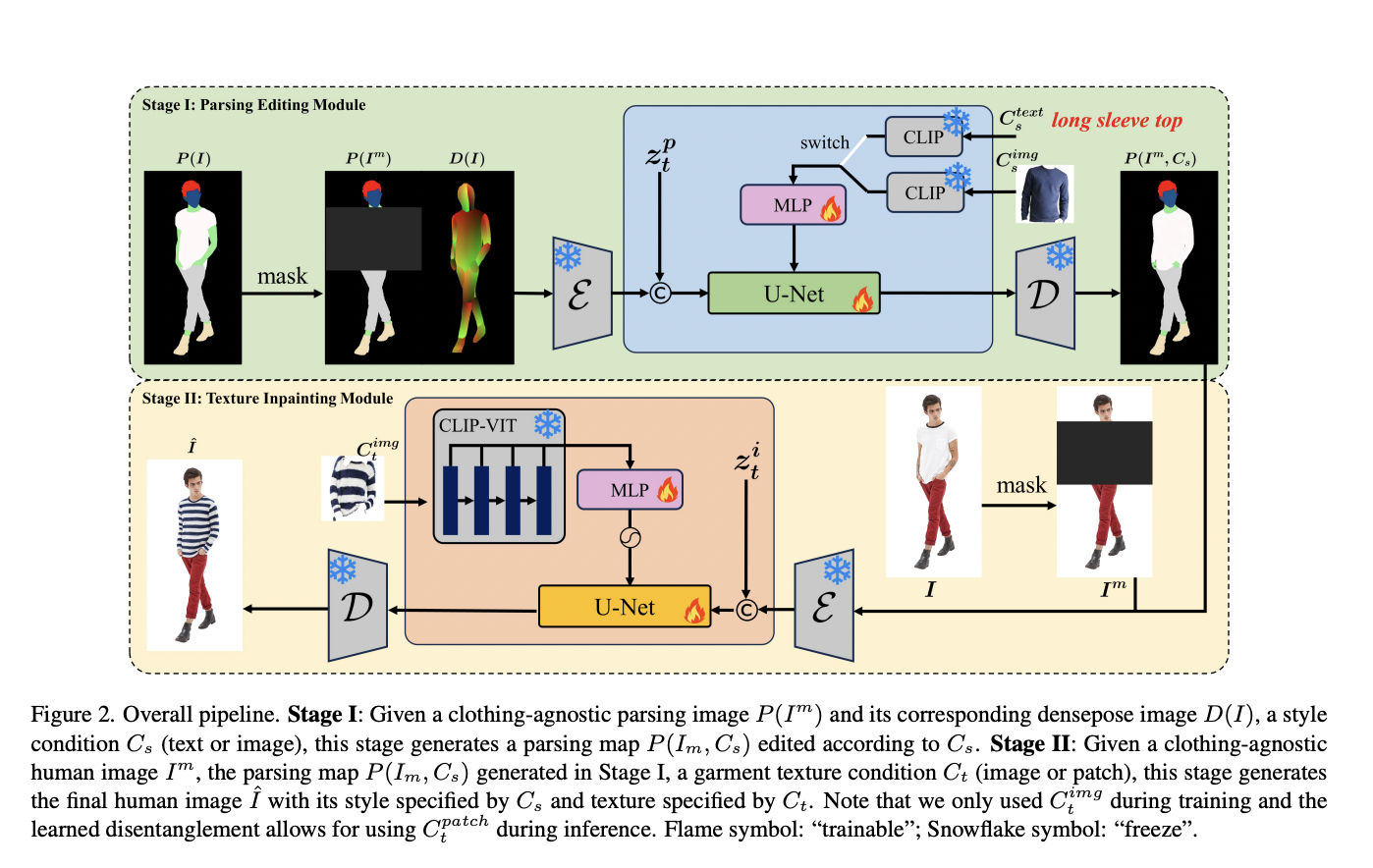
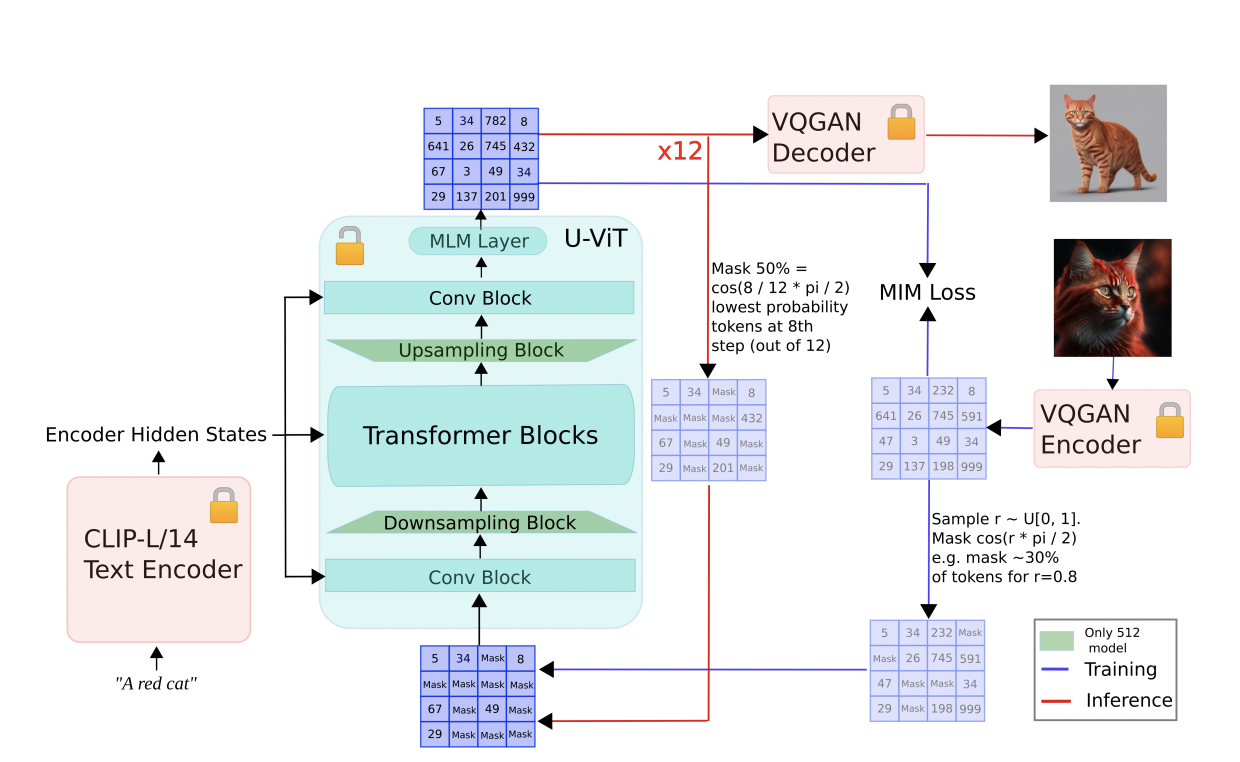
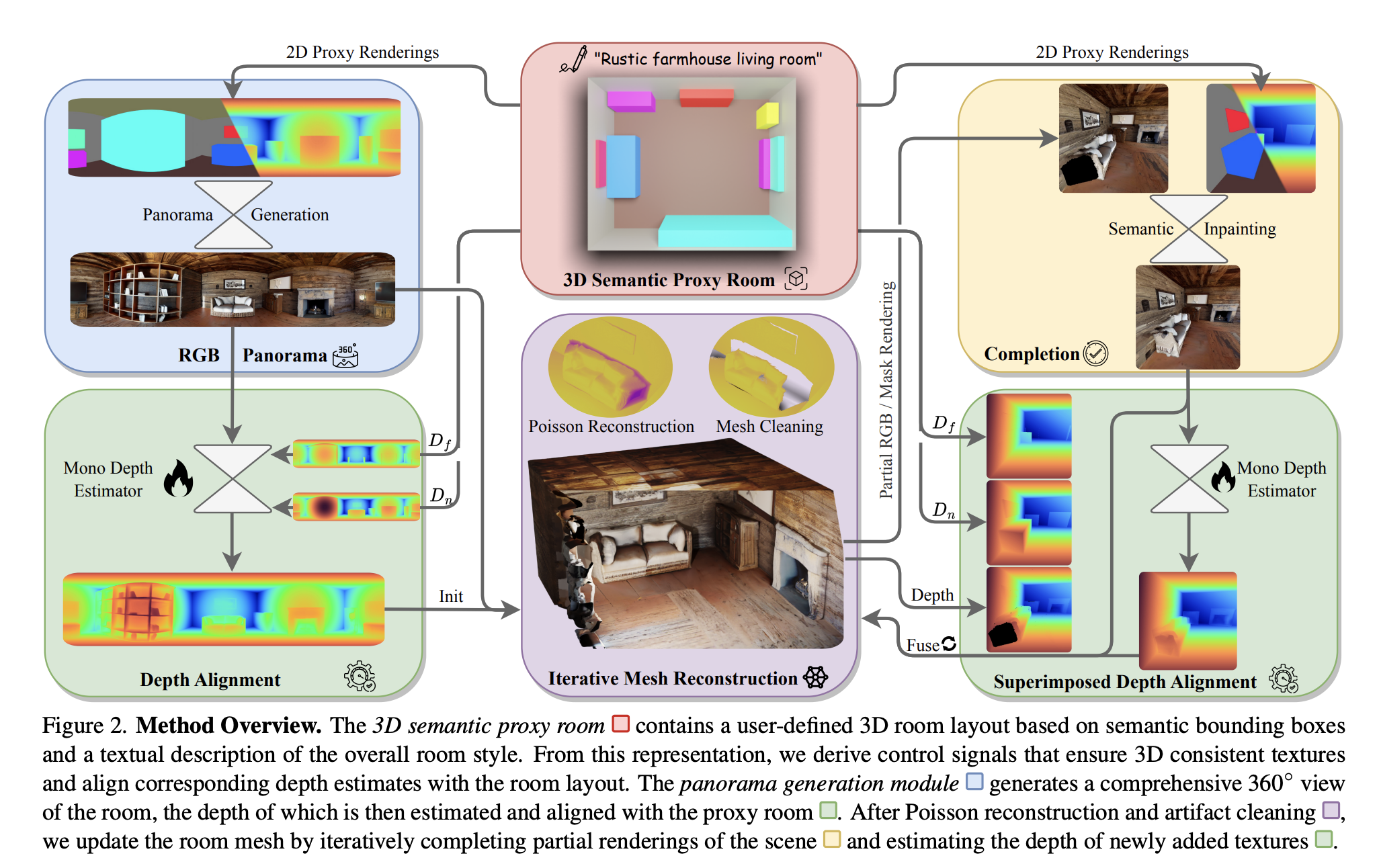
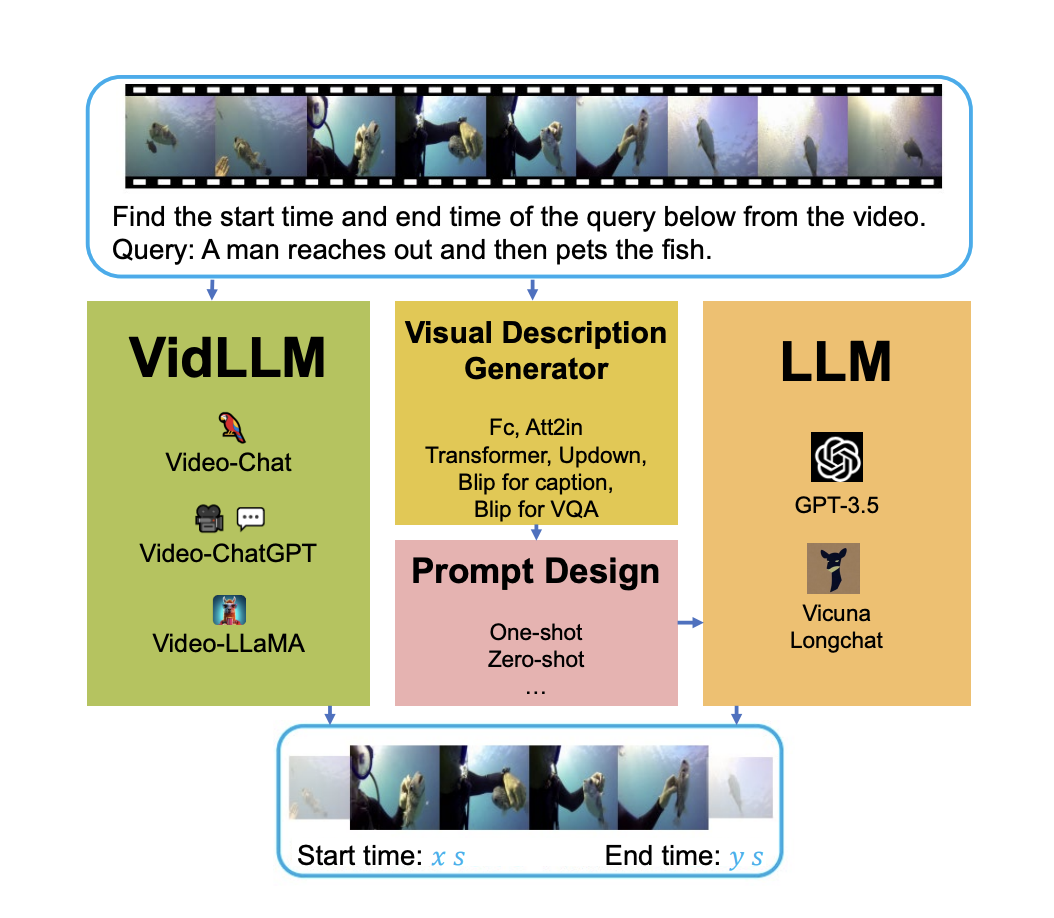
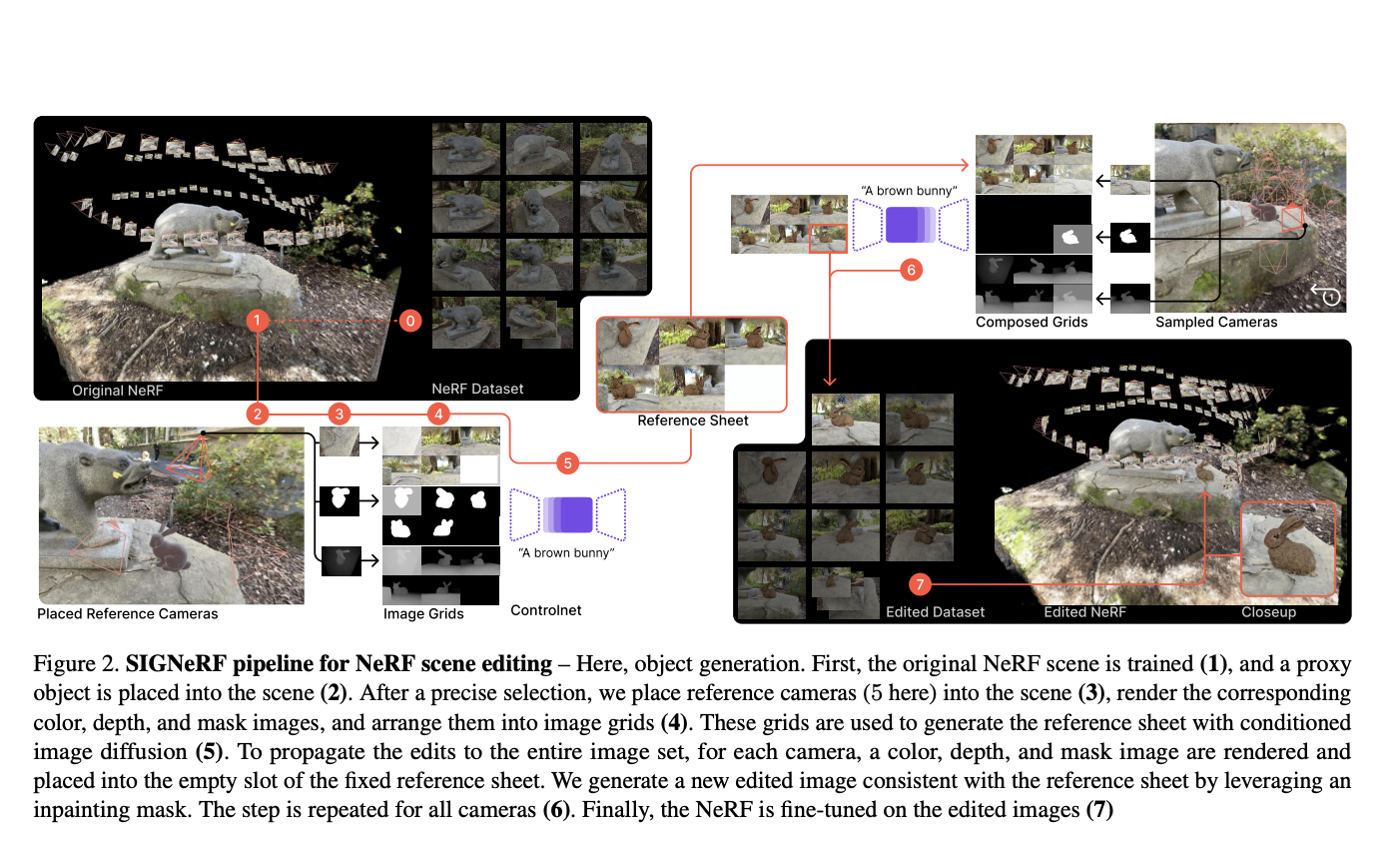
In recent research, a team of researchers has examined CLIP (Contrastive Language-Image Pretraining), which is a famous neural network that effectively acquires visual concepts using natural language supervision. CLIP, which predicts the most relevant text snippet given an image, has helped advance vision-language modeling tasks. Though CLIP’s effectiveness has established itself as a fundamental model…