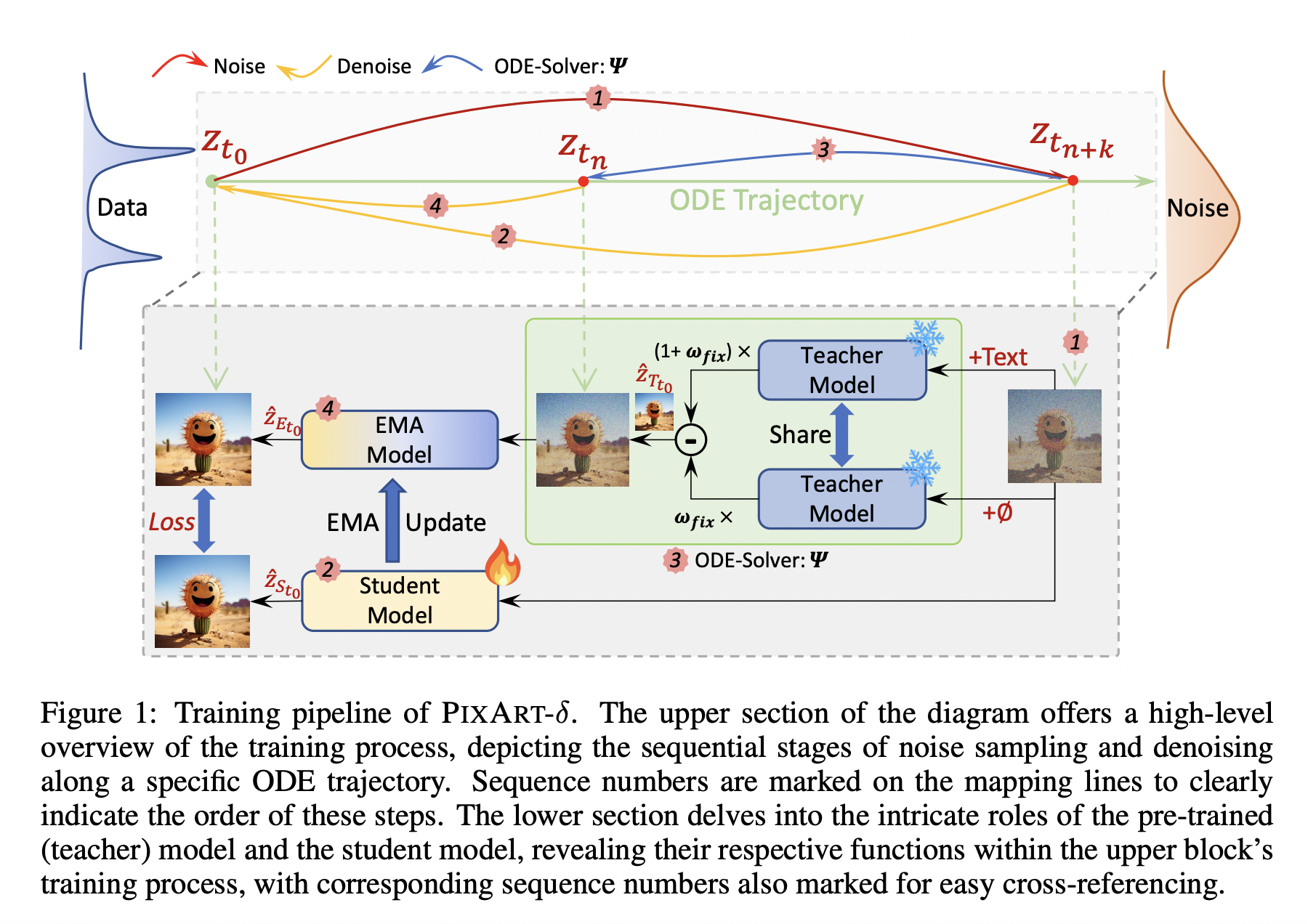
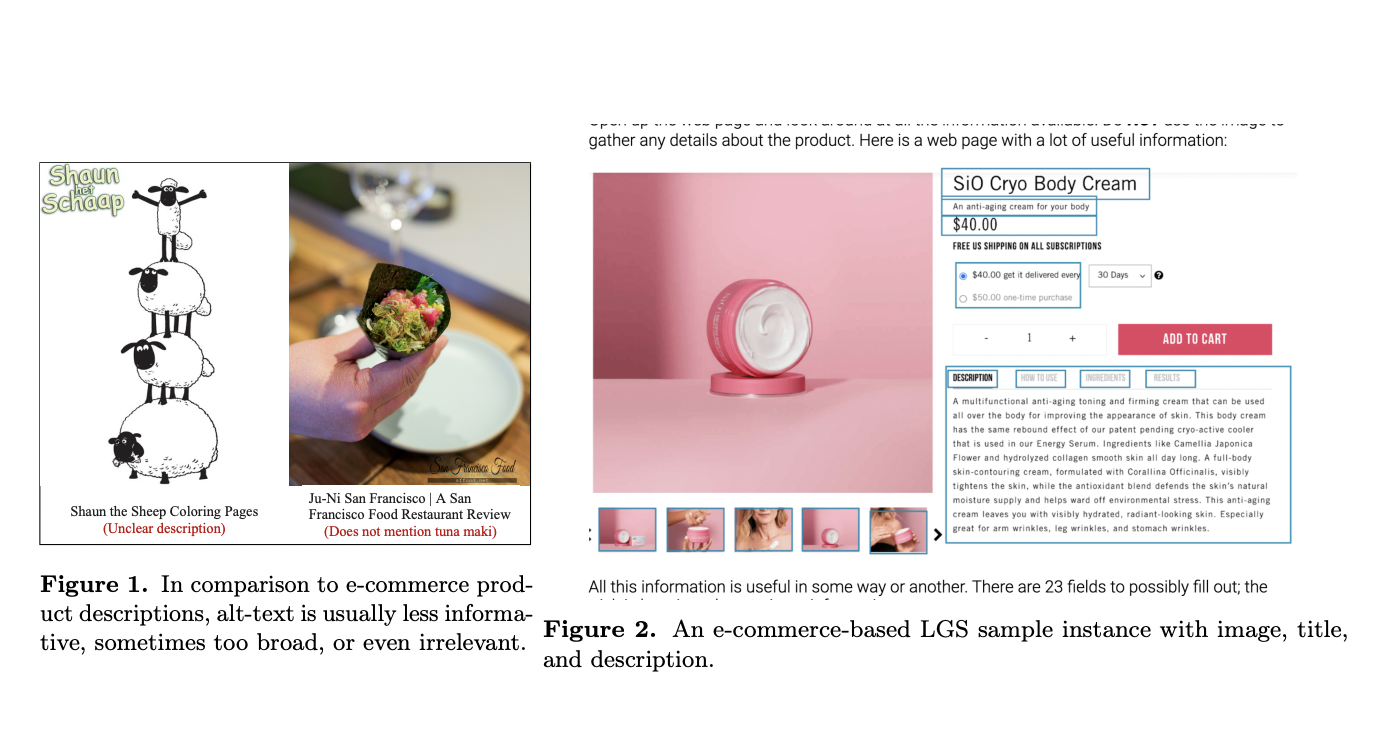
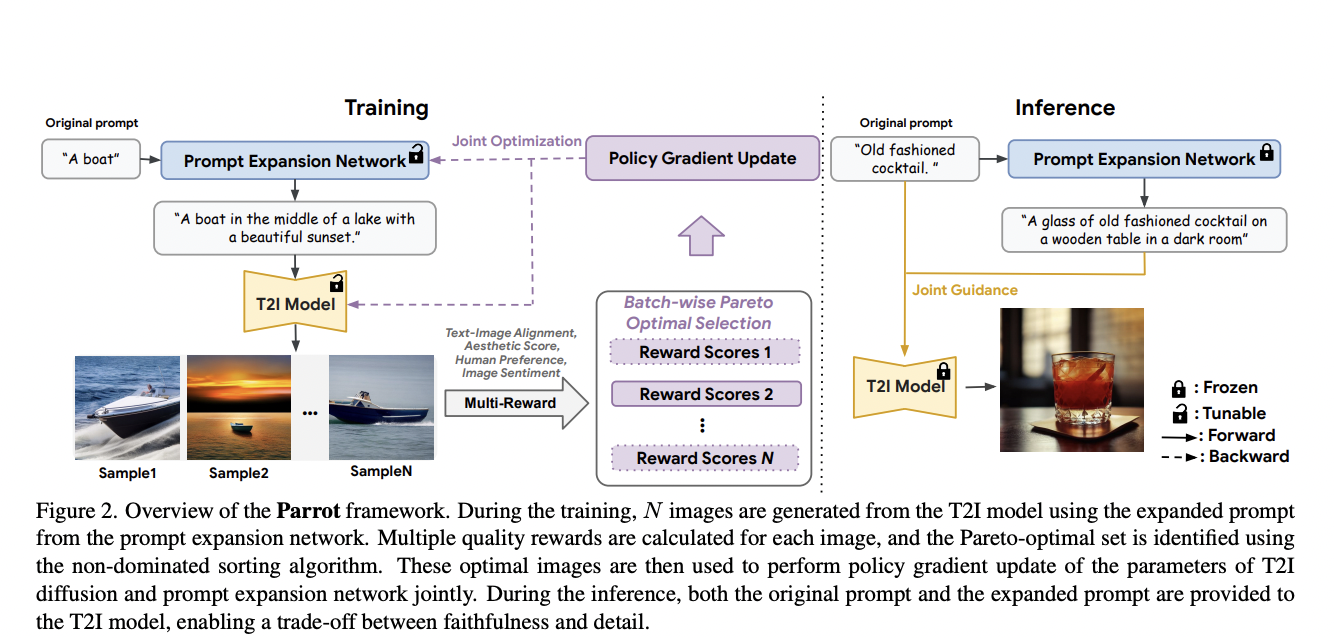
A crucial area of interest is generating images from text, particularly focusing on preserving human identity accurately. This task demands high detail and fidelity, especially when dealing with human faces involving complex and nuanced semantics. While existing models adeptly handle general styles and objects, they often need to improve when producing images that maintain the…