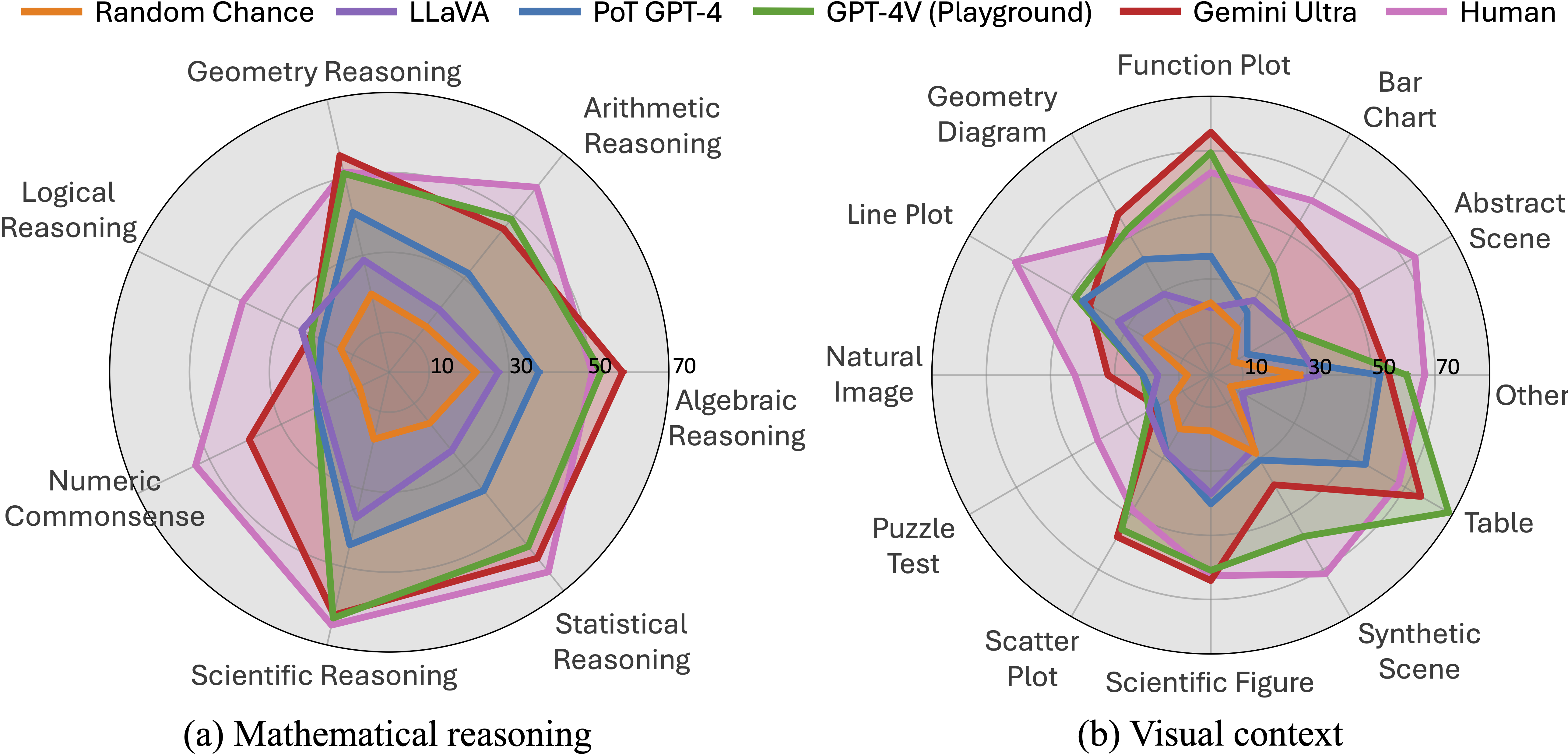
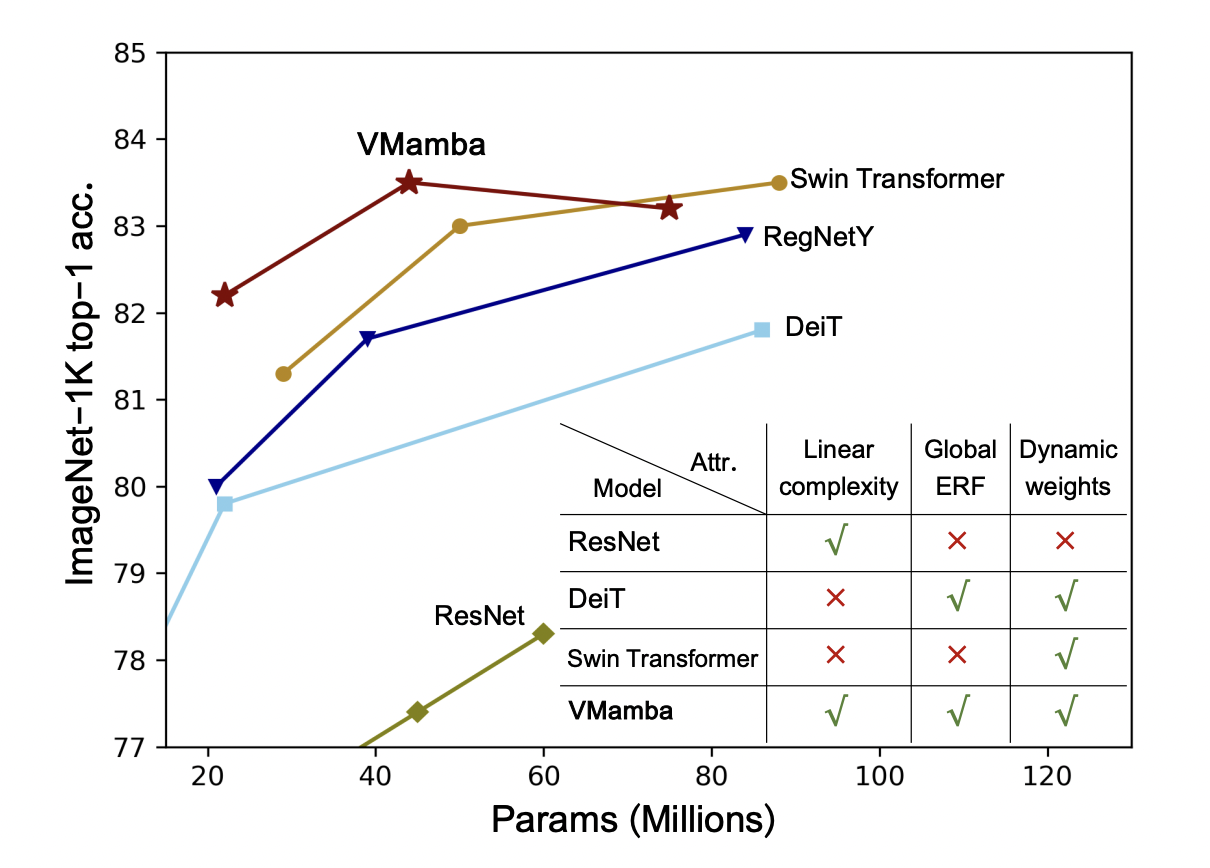
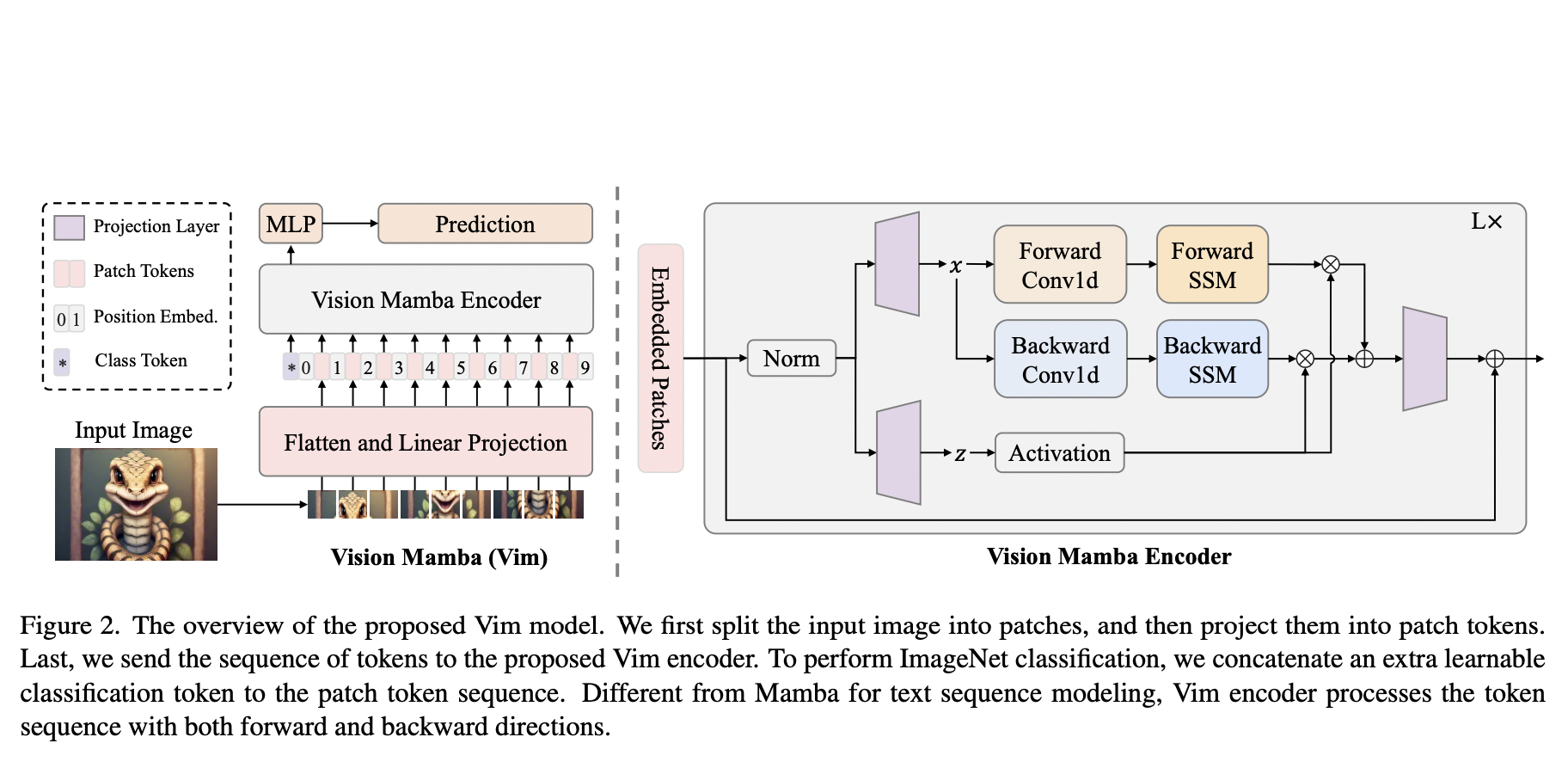
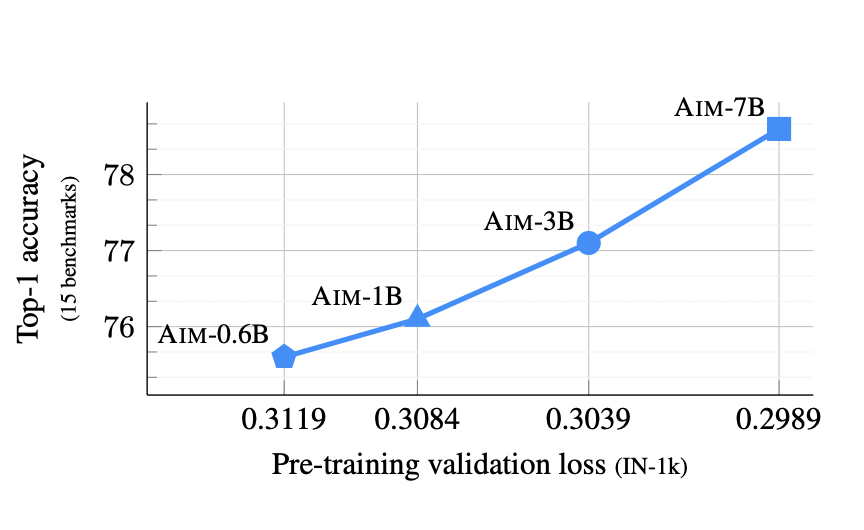
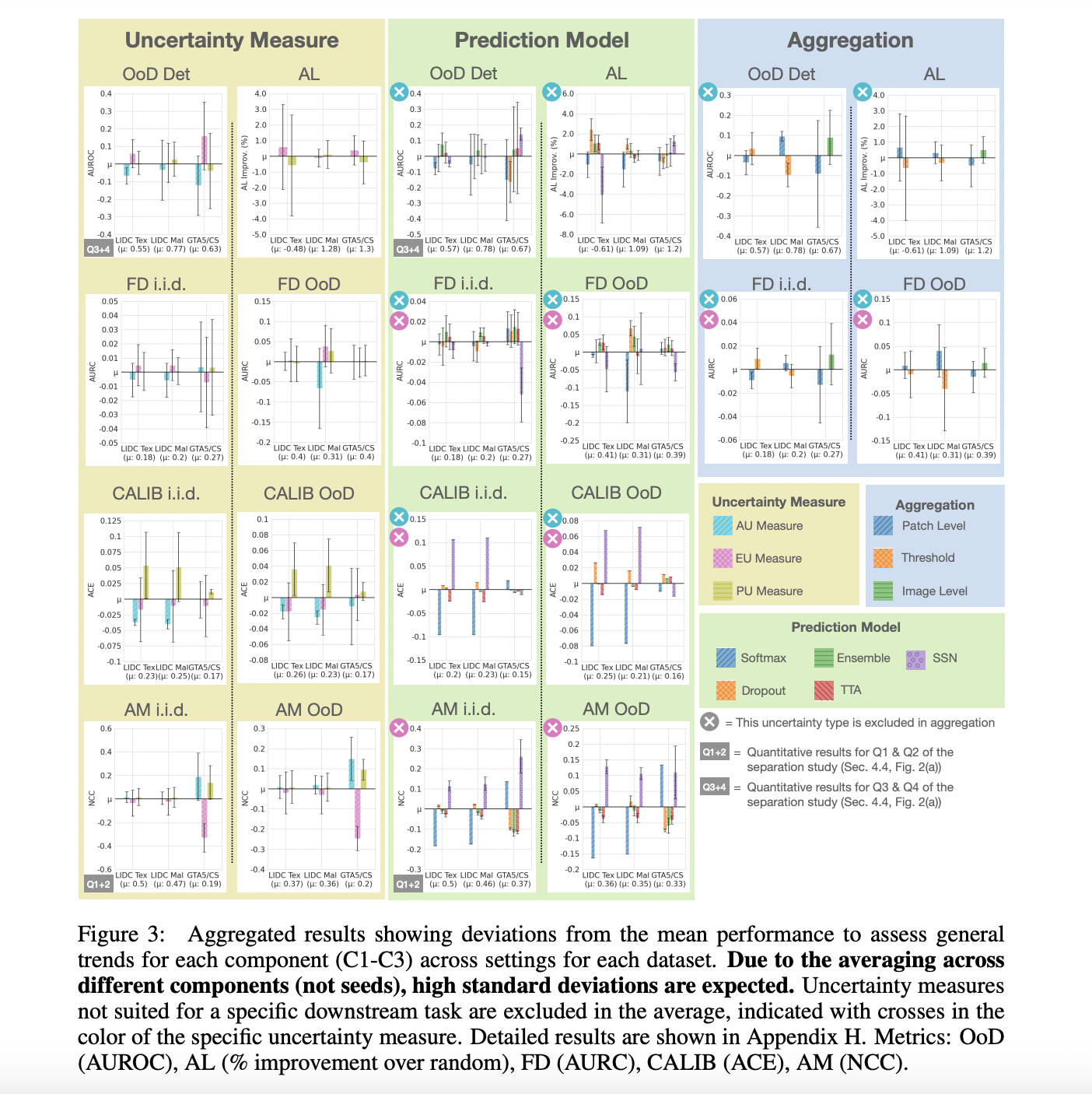
Mathematical reasoning, part of our advanced thinking, reveals the complexities of human intelligence. It involves logical thinking and specialized knowledge, not just in words but also in pictures, crucial for understanding abilities. This has practical uses in AI. However, current AI datasets often focus narrowly, missing a full exploration of combining visual language understanding with…