Gain intuition behind acceleration training techniques in neural networks D eep learning made a gigantic step in the world of artificial intelligence. At the current moment, neural networks outperform other…
In virtual reality and 3D modeling, constructing dynamic, high-fidelity digital human representations from limited data sources, such as single-view videos, presents a significant challenge. This task demands an intricate balance…
How to ensure we benefit society with the most impactful technology being developed today As chief operating officer of one of the world’s leading artificial intelligence labs, I spend a…
Everyone’s job requires certain goods or services to be successful. Teachers need school supplies, mechanics need car parts, and restaurant managers need to get proper uniforms for their teams. Securing…
Remember the time when a single misplaced receipt could derail the entire expense reporting process in a company? Well, those days are long gone. In today's lightning-fast business world, the…
Many industries are excited to apply artificial intelligence (AI) to an increasingly broad assortment of use cases. One emerging possibility involves using such technology to analyze colors.
Keeping the…
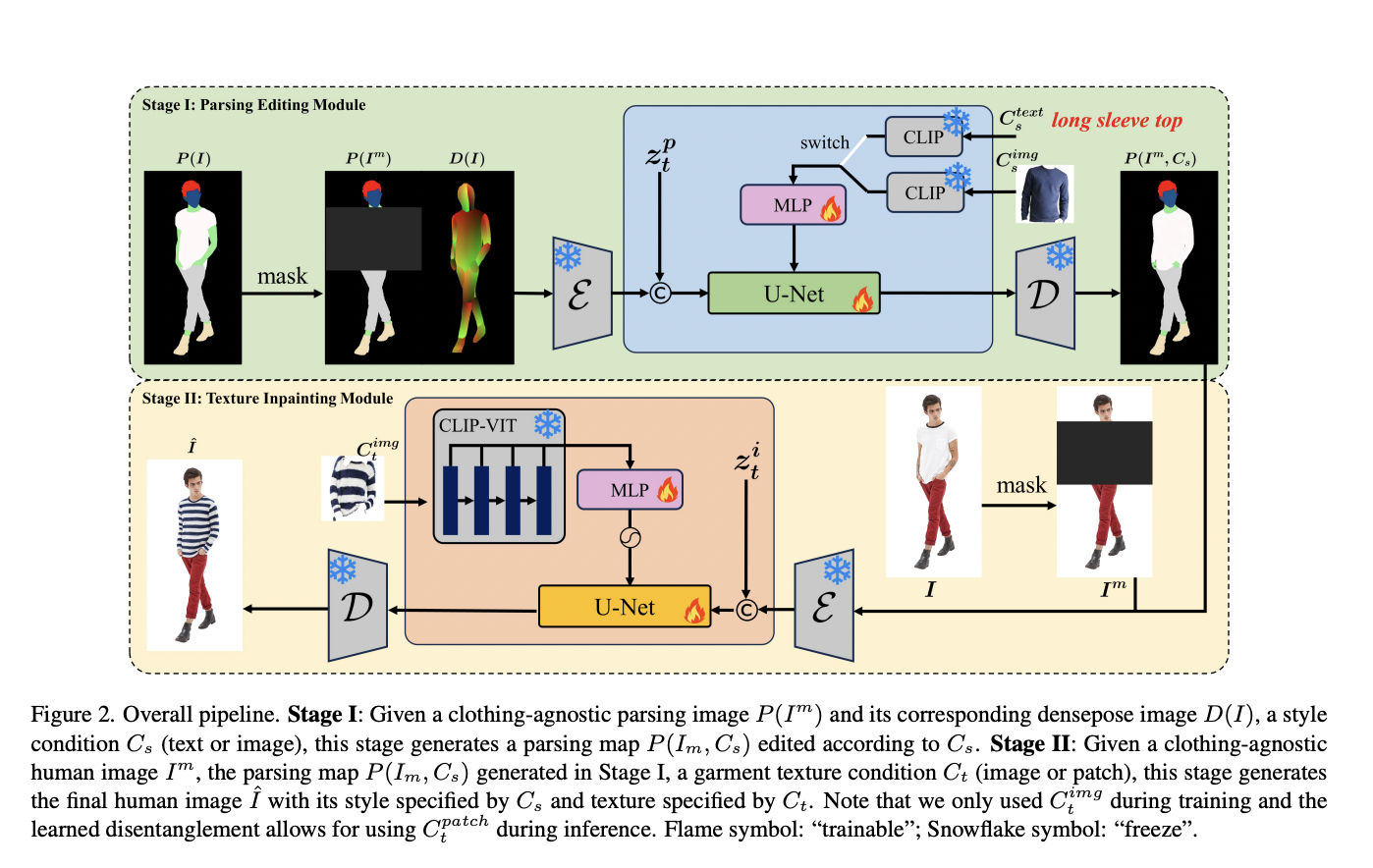
The online shopping experience has been revolutionized by Virtual Try-On (VTON) technology, offering a glimpse into the future of e-commerce. This technology, pivotal in bridging the gap between virtual and…
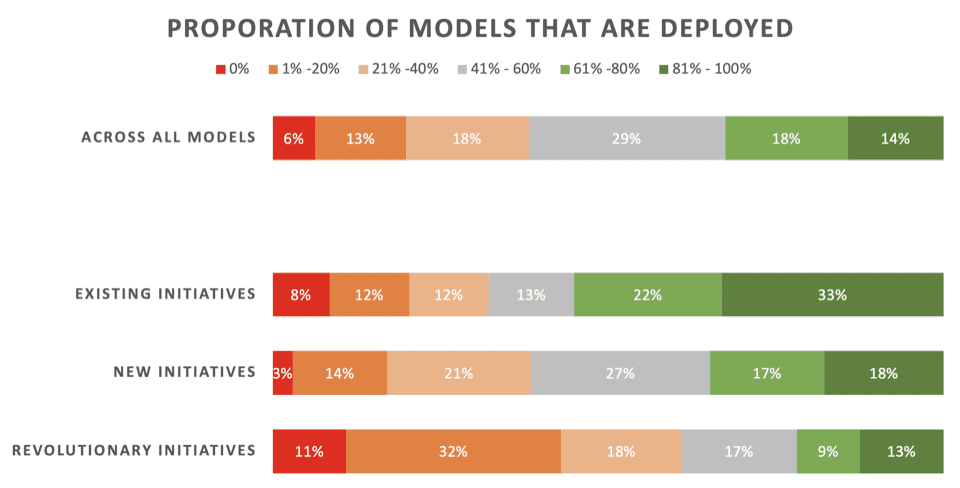
How often do machine learning projects reach successful deployment? Not often enough. There's plenty of industry research showing that ML projects commonly fail to deliver returns, but precious few have…
Now that the novelty of artificial intelligence has worn off, people are focusing on its responsible use. Ethical algorithms have become a chief concern for many businesses and regulatory agencies.…