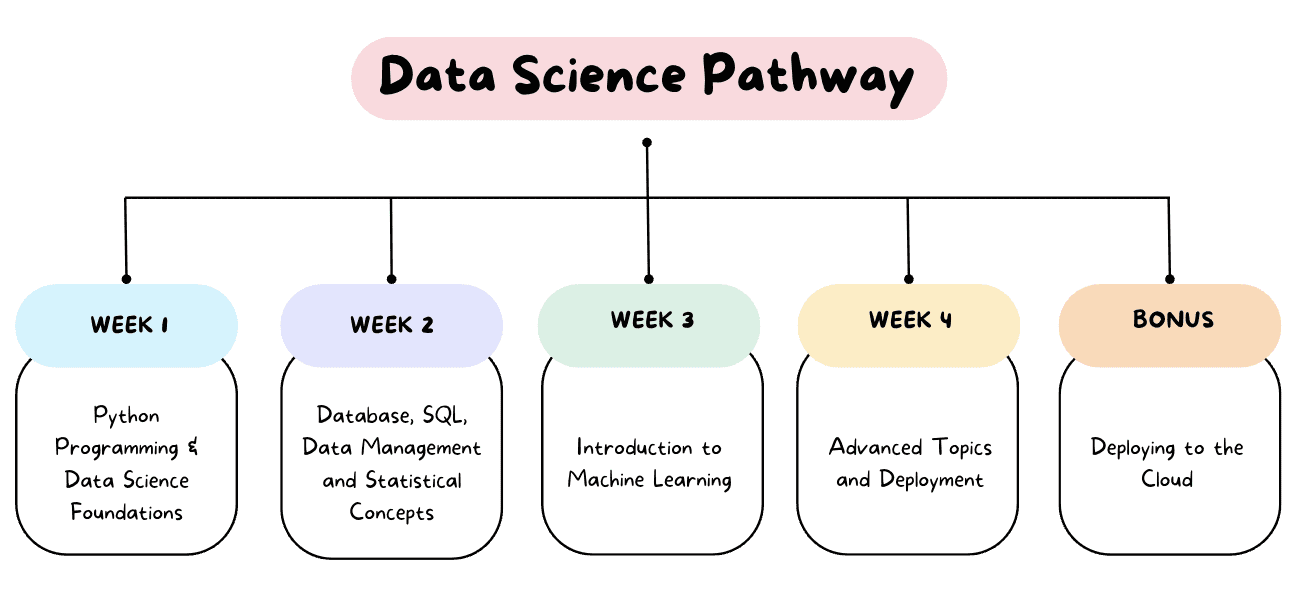
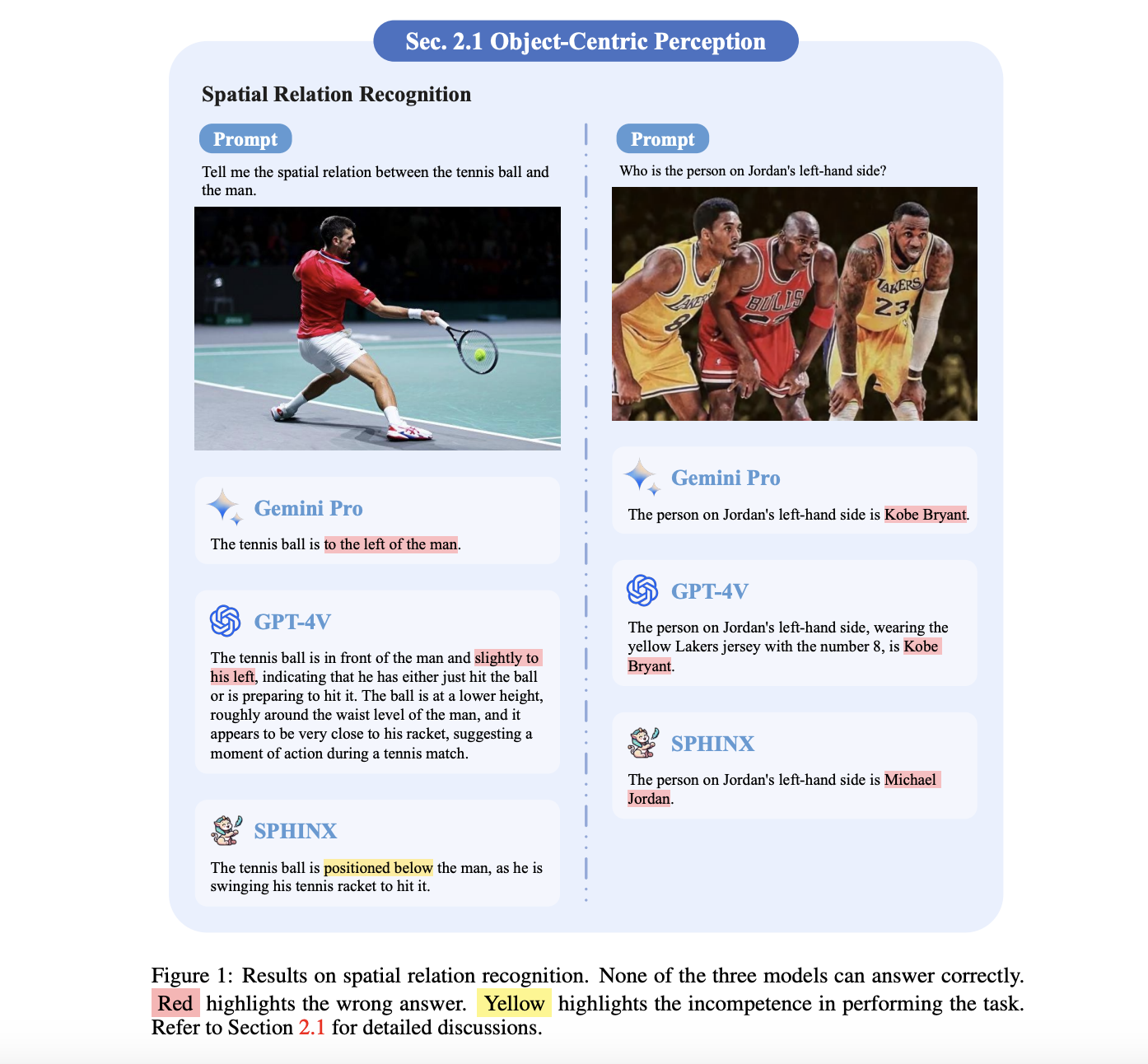
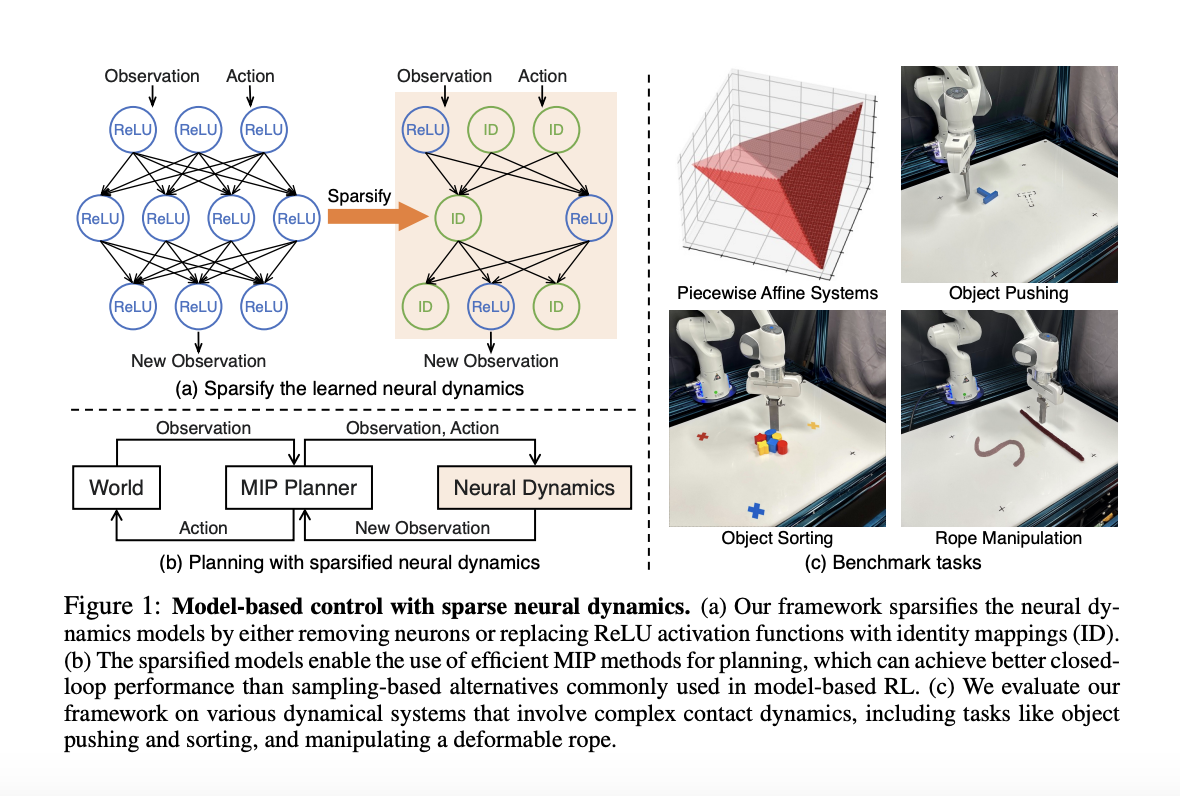
Data is one of your business’s most valuable commodities, but presents a unique series of challenges. Far too often, we collect and store far more data than we can realistically use or effectively manage. This is usually called stovepiping and describes when a data silo operates independently of the whole ecosystem or is otherwise segregated. …