In the rapidly evolving field of household robotics, a significant challenge has emerged in executing personalized organizational tasks, such as arranging groceries in a refrigerator. These tasks require robots to balance user preferences with physical constraints while avoiding collisions and maintaining stability. While Large Language Models (LLMs) enable natural language communication of user preferences, this approach can become cumbersome and time-consuming for users to articulate their requirements precisely. Although Vision-Language Models (VLMs) can learn from user demonstrations, current methodologies face two critical limitations: the ambiguity in inferring unique preferences from limited demonstrations, as multiple preferences could explain the same behavior, and the challenge of translating abstract preferences into physically viable placement locations that respect environmental constraints. These limitations often result in failed executions or potential collisions in new scenarios.
Existing approaches to address these challenges primarily fall into two categories: active preference learning and LLM-based planning systems. Active preference learning methods traditionally rely on comparative queries to understand user preferences, using either teleoperated demonstrations or feature-based comparisons. While some approaches have integrated LLMs to translate feature vectors into natural language questions, they struggle with scaling to complex combinatorial placement preferences. On the planning front, various systems have emerged, including interactive task planners, affordance planners, and code planners, but they often lack robust mechanisms for preference refinement based on user feedback. In addition, while some methods attempt to quantify uncertainty through conformal prediction, they face limitations due to the requirement of extensive calibration datasets, which are often impractical to obtain in household settings. These approaches either fail to effectively handle the ambiguity in preference inference or struggle to incorporate physical constraints in their planning process.
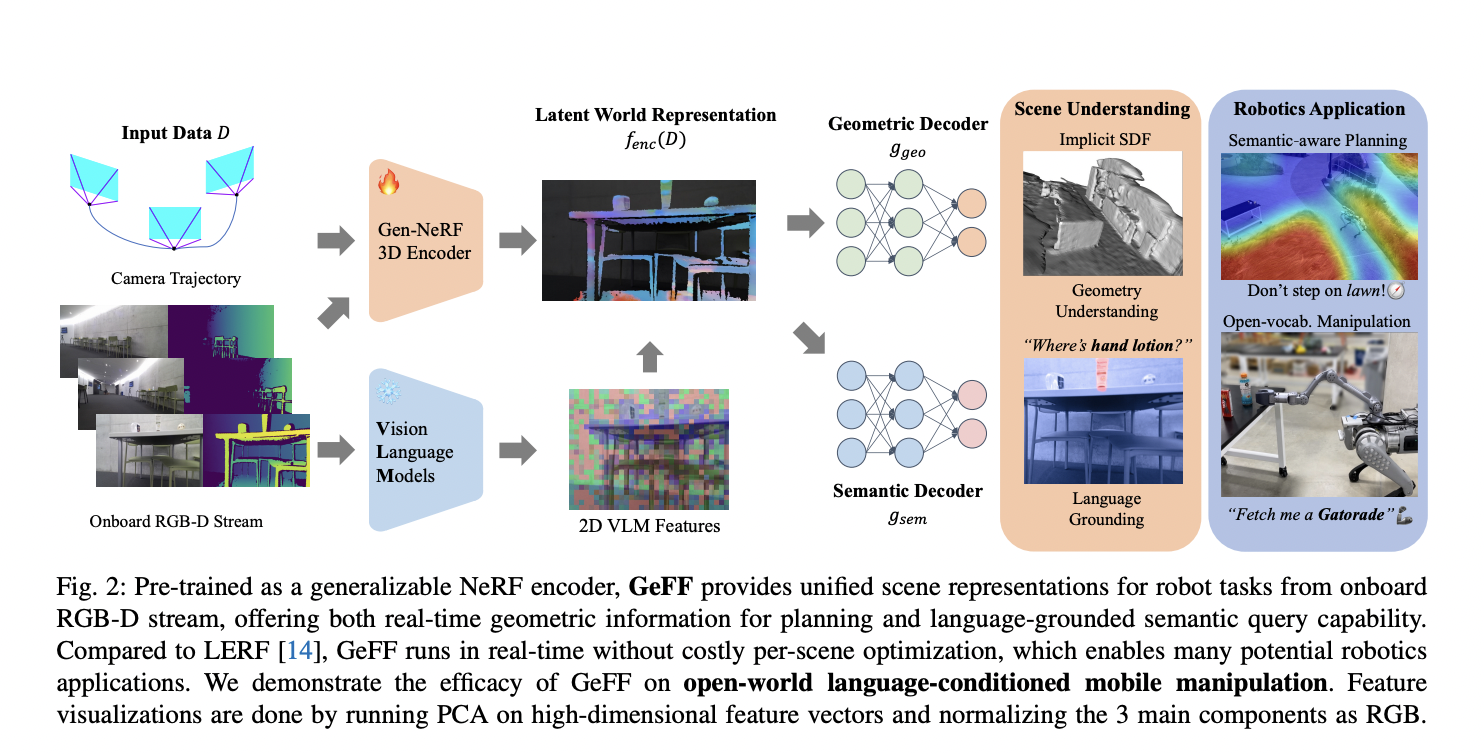
Researchers from Cornell University and Stanford University present APRICOT (Active Preference Learning with Constraint-Aware Task Planner), a comprehensive solution to fill the gap between preference learning and practical robotic execution. The system integrates four key components: a Vision-Language Model that translates visual demonstrations into language-based instructions, a sophisticated LLM-based Bayesian active preference learning module that efficiently identifies user preferences through targeted questioning, a constraint-aware task planner that generates executable plans while respecting both preferences and physical constraints, and a robotic system for real-world implementation. This unique approach addresses previous limitations by combining efficient preference learning with practical execution capabilities, requiring minimal user interaction while maintaining high accuracy. The system’s effectiveness has been extensively validated through benchmark testing across 50 different preferences and real-world robotic implementations in nine distinct scenarios.

APRICOT’s architecture consists of three primary stages working in harmony to achieve personalized task execution. The first stage features an LLM-based Bayesian active preference learning module that processes visual demonstrations through a VLM, generating language-based demonstrations. This module employs three critical components: candidate preference proposal, query determination, and optimal question selection, working together to efficiently refine the preference prior. The second stage implements a sophisticated task planner that operates through three key mechanisms: semantic plan generation using LLMs, geometric plan refinement utilizing world models and beam search optimization, and a reflection-based plan refinement system that incorporates feedback from both reward functions and constraint violations. The final stage handles real-world execution through two crucial components: a perception system utilizing Grounding-DINO for object detection and CLIP for classification and an execution policy that converts high-level commands into sequences of low-level skills through RL-trained policies and path planning algorithms. This integrated system ensures robust performance while maintaining physical constraints and user preferences.

Experimental evaluations demonstrate APRICOT’s superior performance across multiple dimensions. In preference learning accuracy, APRICOT achieved a 58.0% accuracy rate, significantly outperforming baseline methods, including Non-Interactive (35.0%), LLM-Q/A (39.0%), and Cand+LLM-Q/A (43.0%). The system showed remarkable efficiency in user interaction, requiring 71.9% fewer queries compared to LLM-Q/A and 46.25% fewer queries than Cand+LLM-Q/A. In constrained environments, APRICOT maintained impressive performance with 96.0% feasible plans and 89.0% preference satisfaction rates in challenging scenarios. The system’s adaptive capabilities were particularly noteworthy, as demonstrated by its ability to maintain performance even in increasingly constrained spaces and successfully adjust plans in response to environmental changes. These results highlight APRICOT’s effectiveness in balancing preference satisfaction with physical constraints while minimizing user interaction.


APRICOT represents a significant advancement in personalized robotic task execution, successfully integrating preference learning with constraint-aware planning. The system demonstrates effective performance in real-world organizational tasks through its three-stage approach, combining minimal user interaction with robust execution capabilities. However, a notable limitation exists in the active preference learning component, which assumes that the ground-truth preference must be among the generated candidates, potentially limiting its applicability in certain scenarios where user preferences are more nuanced or complex.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.