The field of language models has seen remarkable progress, driven by transformers and scaling efforts. OpenAI’s GPT series demonstrated the power of increasing parameters and high-quality data. Innovations like Transformer-XL expanded context windows, while models such as Mistral, Falcon, Yi, DeepSeek, DBRX, and Gemini pushed capabilities further.
Visual language models (VLMs) have also advanced rapidly. CLIP pioneered shared vision-language feature spaces through contrastive learning. BLIP and BLIP-2 improved on this by aligning pre-trained encoders with large language models. LLaVA and InstructBLIP showed strong generalization across tasks. Kosmos-2 and PaLI-X scaled pre-training data using pseudo-labeled bounding boxes, linking improved perception to better high-level reasoning.
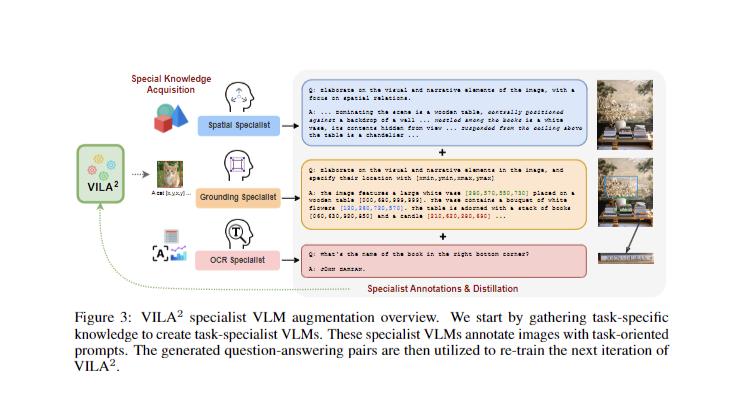
Recent advancements in visual language models (VLMs) have focused on aligning visual encoders with large language models (LLMs) to enhance capabilities across various visual tasks. While progress has been made in training methods and architectures, datasets often remain simplistic. To address this, researchers are exploring VLM-based data augmentation as an alternative to labor-intensive human-created datasets. The paper introduces a novel training regime involving self-augment and specialist-augment steps, iteratively refining pretraining data to generate stronger models.
The research focuses on auto-regressive Visual Language Models (VLMs), employing a three-stage training paradigm: align-pretrain-SFT. The methodology introduces a novel augmentation training regime, starting with self-augmenting VLM training in a bootstrapped loop, followed by specialist augmenting to exploit skills gained during SFT. This approach progressively enhances data quality by improving visual semantics and reducing hallucinations, directly boosting VLM performance. The study introduces the VILA 2 model family, which outperforms existing methods across main benchmarks without additional complexities.
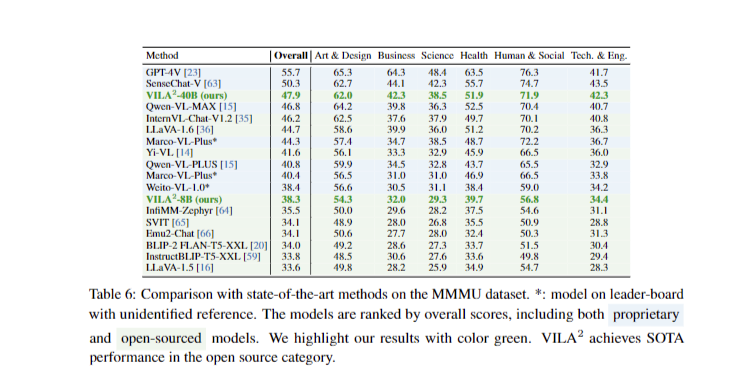
VILA 2 achieves state-of-the-art performance on the MMMU test dataset leaderboard among open-sourced models, using only publicly available datasets. The self-augmentation process gradually removes hallucinations from captions, enhancing quality and accuracy. Through iterative rounds, VILA 2 significantly increases caption length and quality, with improvements observed primarily after round-1. The enriched captions consistently outperform state-of-the-art methods on various visual-language benchmarks, demonstrating the effectiveness of enhanced pre-training data quality.
The specialist-augmented training further enhances VILA 2’s performance by infusing domain-specific expertise into the generalist VLM, improving accuracy across a wide range of tasks. The combination of self-augmented and specialist-augmented training strategies results in significant performance boosts across various benchmarks, pushing VILA’s capabilities to new heights. This methodology of recapturing and training cycles not only improves data quality but also enhances model performance, contributing to consistent accuracy improvements and new state-of-the-art results.
Results show gradual removal of hallucinations and improved caption quality as the self-augmenting process iterates. The combined self-augmented and specialist-augmented training approach leads to enhanced accuracy across various tasks, achieving new state-of-the-art results on the MMMU leaderboard among open-sourced models. This methodology demonstrates the potential of iterative data refinement and model improvement in advancing visual language understanding capabilities.
In conclusion, VILA 2 represents a significant leap forward in visual language models, achieving state-of-the-art performance through innovative self-augmentation and specialist-augmentation techniques. By iteratively refining pretraining data using only publicly available datasets, the model demonstrates superior caption quality, reduced hallucinations, and improved accuracy across various visual-language tasks. The combination of generalist knowledge with domain-specific expertise results in significant performance boosts across benchmarks. VILA 2’s success highlights the potential of data-centric improvements in advancing multi-modal AI systems, paving the way for more sophisticated visual and textual information understanding. This approach not only enhances model performance but also showcases the effectiveness of leveraging existing models to improve data quality, potentially revolutionizing the development of future AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here

Shoaib Nazir is a consulting intern at MarktechPost and has completed his M.Tech dual degree from the Indian Institute of Technology (IIT), Kharagpur. With a strong passion for Data Science, he is particularly interested in the diverse applications of artificial intelligence across various domains. Shoaib is driven by a desire to explore the latest technological advancements and their practical implications in everyday life. His enthusiasm for innovation and real-world problem-solving fuels his continuous learning and contribution to the field of AI