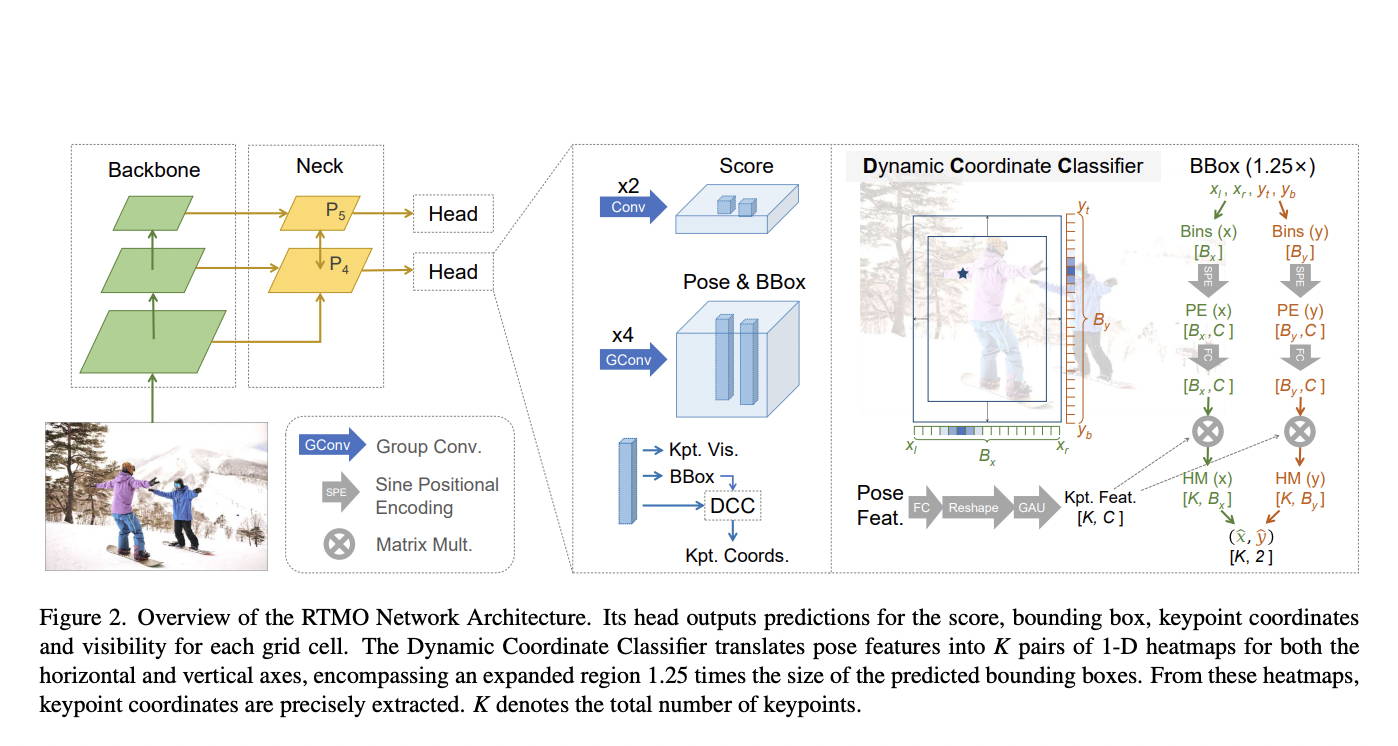
The rapid evolution in AI demands models that can handle large-scale data and deliver accurate, actionable insights. Researchers in this field aim to create systems capable of continuous learning and adaptation, ensuring they remain relevant in dynamic environments.
A significant challenge in developing AI models lies in overcoming the issue of catastrophic forgetting, where models fail to retain previously acquired knowledge when learning new tasks. This challenge becomes more pressing as applications increasingly demand continuous learning capabilities. For instance, models must update their understanding of healthcare, financial analysis, and autonomous systems while retaining prior knowledge to make informed decisions. The primary problem is designing models that can efficiently learn new information without compromising on previously acquired insights.
Existing research includes Elastic Weight Consolidation (EWC), which prevents catastrophic forgetting by penalizing crucial weight changes, and replay-based methods like Experience Replay, which reinforces prior knowledge by replaying past experiences. Modular neural network architectures, like Progressive Neural Networks, add sub-networks for new tasks, while meta-learning approaches, such as Model-Agnostic Meta-Learning (MAML), allow models to adapt to new tasks with minimal data quickly. Each approach has unique trade-offs in complexity, efficiency, and adaptability.
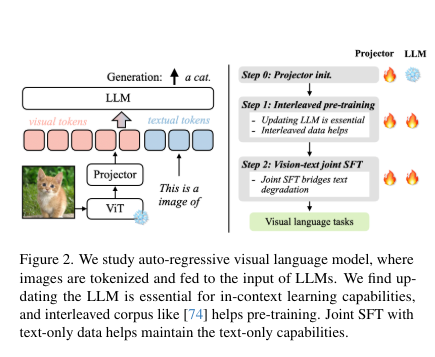
Researchers from NVIDIA and MIT have introduced a novel visual language model (VLM) pre-training framework, VILA, which emphasizes effective embedding alignment and utilizes dynamic neural network architectures. This research differs by leveraging a combination of interleaved corpora and joint supervised fine-tuning (SFT) to enhance visual and textual learning capabilities. The VILA framework is distinct for its emphasis on preserving in-context learning abilities while improving generalization, ensuring that models retain the ability to handle complex tasks efficiently.
To improve visual and textual alignment, the methodology involved pre-training VILA on large-scale datasets, such as Coyo-700m. Researchers used a base LLaVA model to test different pre-training strategies, comparing freezing and updating the large language model (LLM) during training. They introduced Visual Instruction Tuning to fine-tune the models using visual language datasets with prompt-based instruction tuning. The evaluation process included testing the pre-trained models on benchmarks like OKVQA and TextVQA to assess visual question-answering capabilities, specifically measuring VILA’s accuracy and context-learning ability.
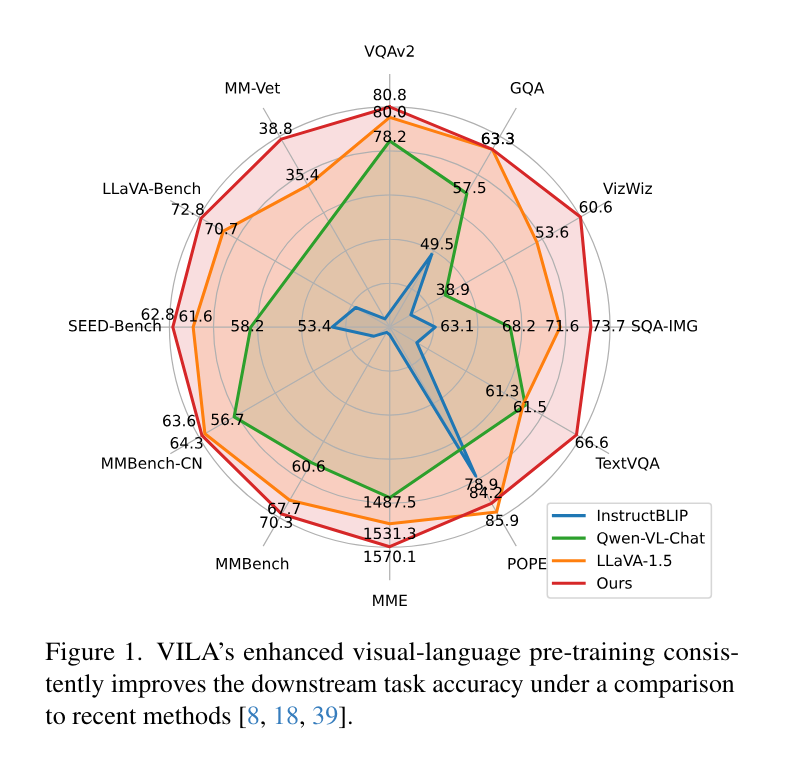
VILA demonstrated significant results in improving the performance of VLMs. It showed significant accuracy gains, achieving an average of 70.7% on OKVQA and 78.2% on TextVQA, outperforming existing benchmarks by noticeable margins. Furthermore, VILA retained up to 90% of previously learned knowledge when learning new tasks. This result indicates a reduction in catastrophic forgetting, showing that VILA could adapt to new visual language tasks while maintaining prior knowledge.
To conclude, the research presented a novel framework for pre-training VLMs, emphasizing embedding alignment and efficient task learning. By employing innovative techniques like Visual Instruction Tuning and leveraging large-scale datasets, VILA demonstrated improved accuracy in visual question-answering tasks. The research highlighted the importance of balancing new learning with prior knowledge retention, reducing catastrophic forgetting. This approach contributes significantly to advancing VLMs, enabling more effective and adaptable AI systems for diverse real-world applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.