
Screenshot by Editor
It’s been an interesting 12 months. A lot has happened with large language models (LLMs) being at the forefront of everything tech-related. You have LLMs such as ChatGPT, Gemini, and more.
These LLMs are currently run in the cloud, meaning they run somewhere else on someone else’s computer. For something to be run elsewhere, you can imagine how expensive it is. Because if it was so cheap, why not run it locally on your own computer?
But that’s all changed now. You can now run different LLMs with LM Studio.
LM studio is a tool that you can use to experiment with local and open-source LLMs. You can run these LLMs on your laptop, entirely off. There are two ways that you can discover, download and run these LLMs locally:
- Through the in-app Chat UI
- OpenAI compatible local server
All you have to do is download any model file that is compatible from the HuggingFace repository, and boom done!
So how do I get started?
LM Studio Requirements
Before you can get kickstarted and start delving into discovering all the LLMs locally, you will need these minimum hardware/software requirements:
- M1/M2/M3 Mac
- Windows PC with a processor that supports AVX2. (Linux is available in beta)
- 16GB+ of RAM is recommended
- For PCs, 6GB+ of VRAM is recommended
- NVIDIA/AMD GPUs supported
If you have these, you’re ready to go!
So what are the steps?
Your first step is to download LM Studio for Mac, Windows, or Linux, which you can do here. The download is roughly 400MB, therefore depending on your internet connection, it may take a whole.
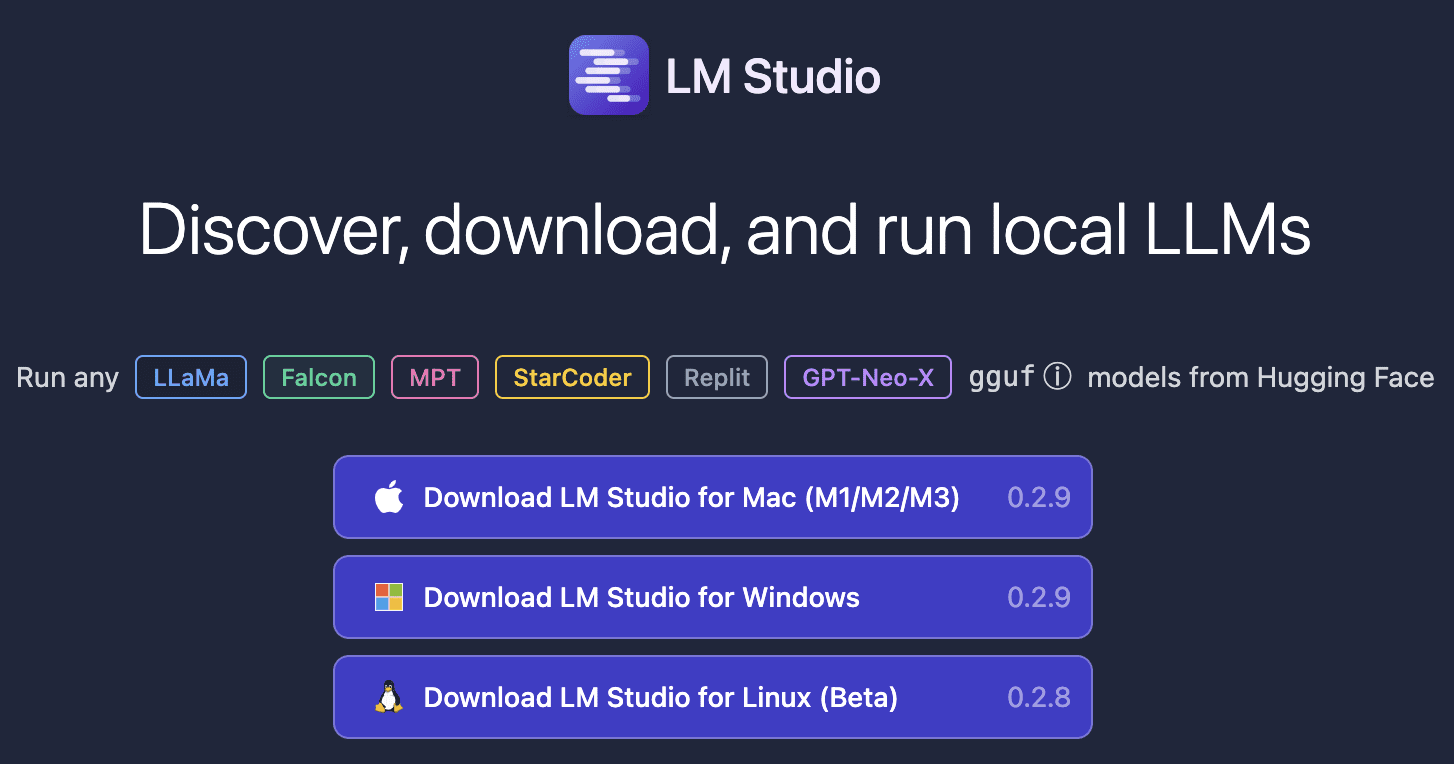
Your next step is to choose a model to download. Once LM Studio has been launched, click on the magnifying glass to skim through the options of models available. Again, take into consideration that these models with be large, therefore it may take a while to download.
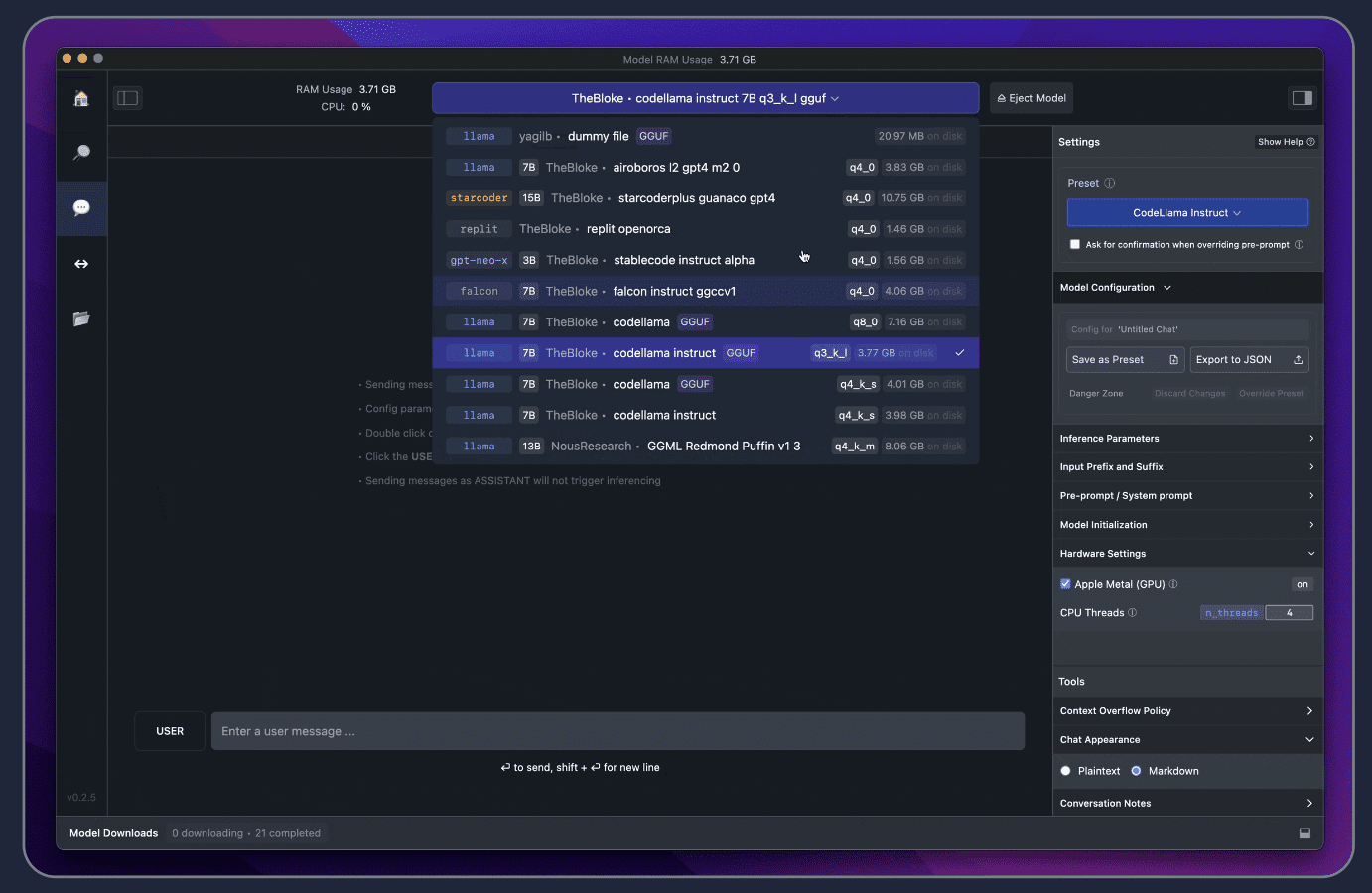
Once the model has been downloaded, click the Speech Bubble on the left and select your model for it to load.
Ready to chit-chat!
There you have it, that quick and simple to set up an LLM locally. If you would like to speed up the response time, you can do so by enabling the GPU acceleration on the right-hand side.
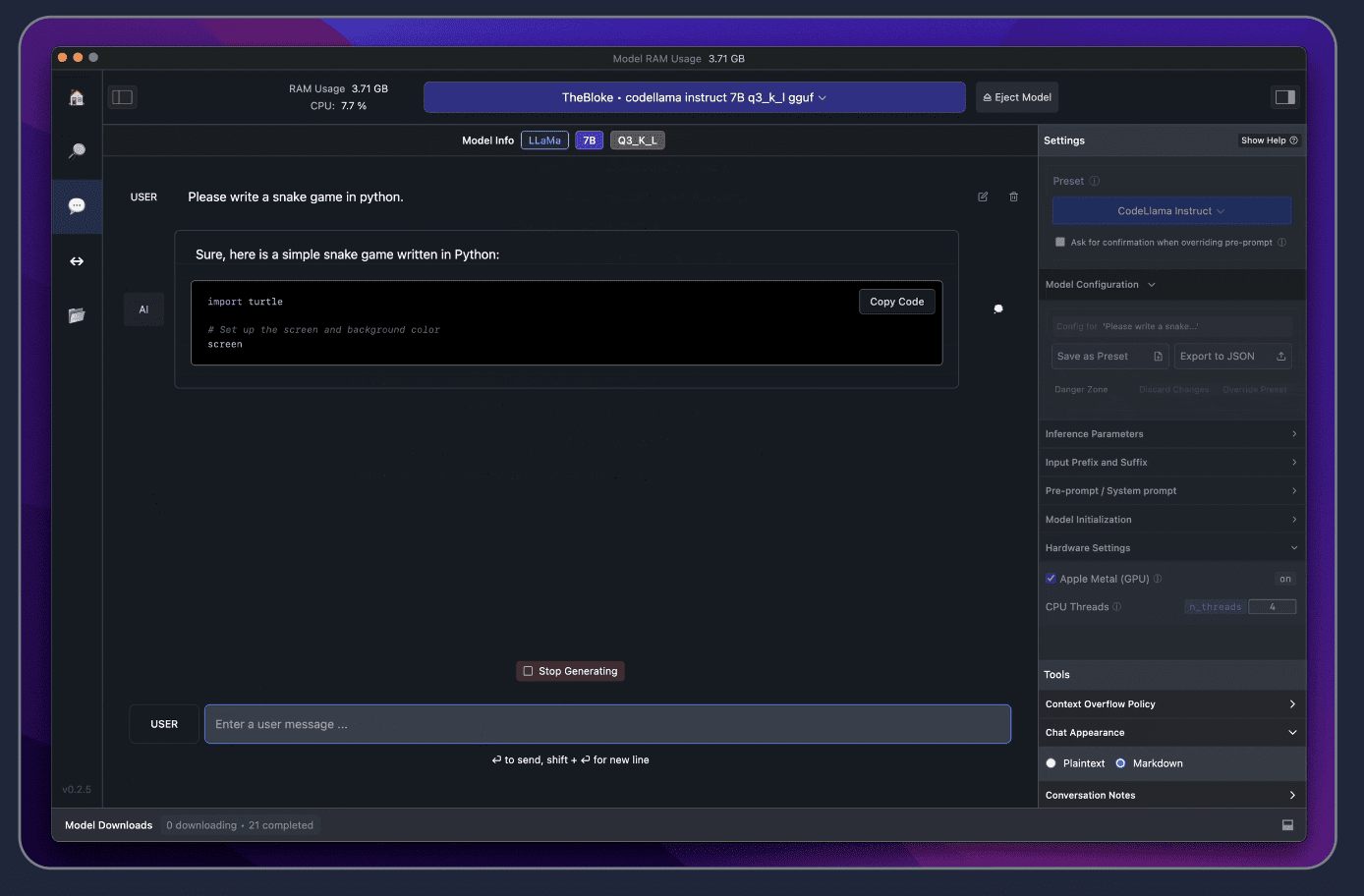
Do you see how quick that was? Fast right.
If you are worried about the collection of data, it is good to know that the main reason for being able to use an LLM locally is privacy. Therefore, LM Studio has been designed exactly for that!
Have a go and let us know what you think in the comments!
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.

