Transformers were first introduced and quickly rose to prominence as the primary architecture in natural language processing. More lately, they have gained immense popularity in computer vision as well. Dosovitskiy et al. demonstrated how to create effective image classifiers that beat CNN-based architectures at high model and data scales by dividing pictures into sequences of patches, linearly embedding those patches, and then feeding the resultant sequence of features to a transformer encoder. For many discriminative vision tasks, such as segmentation, detection, and classification, this approach is currently the norm. However, as generative transformers decoders consume and anticipate discrete tokens from some predefined, finite vocabulary, mapping an image to a sequence of (unquantized) feature vectors is not appropriate for transformer-based picture production.
A structure like this naturally fits natural language, and decoder-only models allow for effective training via instructor forcing and strong sequential generative modeling. Recent efforts have used a two-stage technique to map pictures to a sequence of discrete tokens using a Vector-Quantized Variational Autoencoder (VQ-VAE), and then learn a transformer decoder to model the latent discrete-token distribution. This approach aims to harness these capabilities for images. By simply concatenating the vocabularies of the various modalities, including text and images, such VQ-VAE-based image tokenization also allows for interleaved multimodal generative models. Although this two-step method worked well for creating images and multimodal content, there are a few problems with it.
How much data may be kept in the latent coding sequence and how much visual modeling is handled by the VQ-VAE decoder depends on the vocabulary size in VQ-VAE. A short vocabulary can facilitate latent modeling, but it also reduces the informativeness of the latent code, making it difficult to regulate the fine details in picture formation and affecting the quality of applications that use the tokens for dense prediction or low-level discriminative tasks. Increasing the vocabulary size can help address this problem, but doing so may result in poor vocabulary use, forcing high-fidelity VQ-VAE setups to rely on a variety of sophisticated methods like entropy losses or codebook-splitting. Moreover, huge vocabularies result in enormous embedding matrices that take up a lot of memory, which might be problematic in multimodal scenarios when vocabularies from different modalities are mixed. The research team suggests changing decoder-only transformers to do away with the requirement for discrete tokens and, thus, fixed, limited vocabularies in order to avoid these problems.
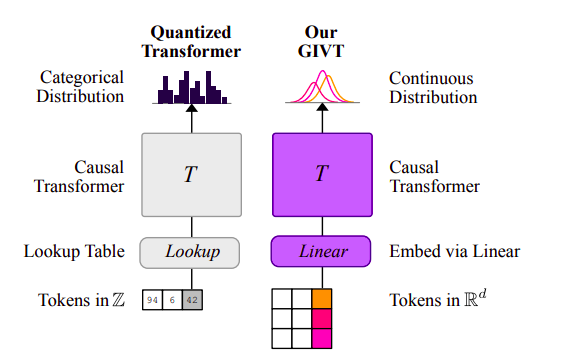
In particular, the research team from Google DeepMind and Google Research suggest a generative transformer decoder that functions with real-valued vector sequences. The research team refers to this as a Generative Unlimited-Vocabulary Transformer (GIVT) since real-valued vectors may be thought of as an unlimited vocabulary. As seen in Fig. 1, the research team altered the transformer decoder design just slightly (two modifications total). 1) At the input, the research team linearly embeds a sequence of real-valued vectors instead of looking up a finite vocabulary of embeddings using a series of discrete tokens; 2) at the output, the research team predicts the parameters of a continuous distribution over real-valued vectors instead of predicting the parameters of a categorical distribution over a finite vocabulary (via logits). The research team trained this model using teacher forcing and a causal attention mask, just like typical transformer decoders. Alternatively, the research team investigated rapid progressive masked-bidirectional modeling, similar to MaskGIT.
The series of RGB pixels created by flattening a high-resolution image is an example of a sequence that can be difficult to model directly, even though GIVT can theoretically be applied to any sequence of feature vectors. It can also be excessively lengthy or follow a complicated distribution. Therefore, the research team first trains a lower-dimensional latent space using a Gaussian-prior VAE, and then model it with GIVT, which is akin to the two-stage technique with VQ-VAEs and similar to the two-stage approach of latent-diffusion models. The research team also transferred a number of inference strategies (such as temperature sampling and classifier-free guiding) from the sequence-modeling literature.
Remarkably, depending only on real-valued tokens, this produces a model that is either superior or equivalent to VQ-based techniques. The following succinctly describes their principal contributions:
1. Using UViM, the research team demonstrates that GIVT achieves similar or better performance than the typical discrete-token transformer decoder on dense prediction tasks, including semantic segmentation and depth estimation, as well as picture synthesis.
2. The research team derived and proved the efficacy of variations of traditional sampling methods for the continuous case, including temperature sampling, beam search, and classifier-free guiding (CFG).
3. Using KL-term weighting, the research team examines the connection between the level of VAE latent-space regularization and the characteristics of GIVT that emerge. The research team stresses that the sophisticated training methods of the VQ-VAE literature, such as auxiliary losses on the latent representation, codebook reinitialization, or specialized optimization algorithms, are not used in the VAE and GIVT training; rather, they rely simply on normal deep-learning toolbox approaches.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.