
Picture this – you’re drowning in a sea of PDFs, spreadsheets, and scanned documents, searching for that one piece of data trapped somewhere in a complex table. From financial reports and research papers, to resumes and invoices, these documents can contain complex tables with a wealth of structured data that needs to be quickly and accurately extracted. Traditionally, extracting this structured information has been a complex task in data processing. However, with the rise of the Large Language Model (LLM), we now have another tool with the potential to unlock intricate tabular data.
Tables are ubiquitous, holding a large volume of information packed in a dense format. The accuracy of a good table parser can pave the way to automation of a lot of workflows in a business.
This comprehensive guide will take you through the evolution of table extraction techniques, from traditional methods to the cutting-edge use of LLMs. Here’s what you’ll learn:
- An overview of table extraction and it’s innate challenges
- Traditional table extraction methods and their limitations
- How LLMs are being applied to improve table extraction accuracy
- Practical insights into implementing LLM-based table extraction, including code examples
- A deep dive into Nanonets’ approach to table extraction using LLMs
- The pros and cons of using LLMs for table extraction
- Future trends and potential developments in this rapidly evolving field
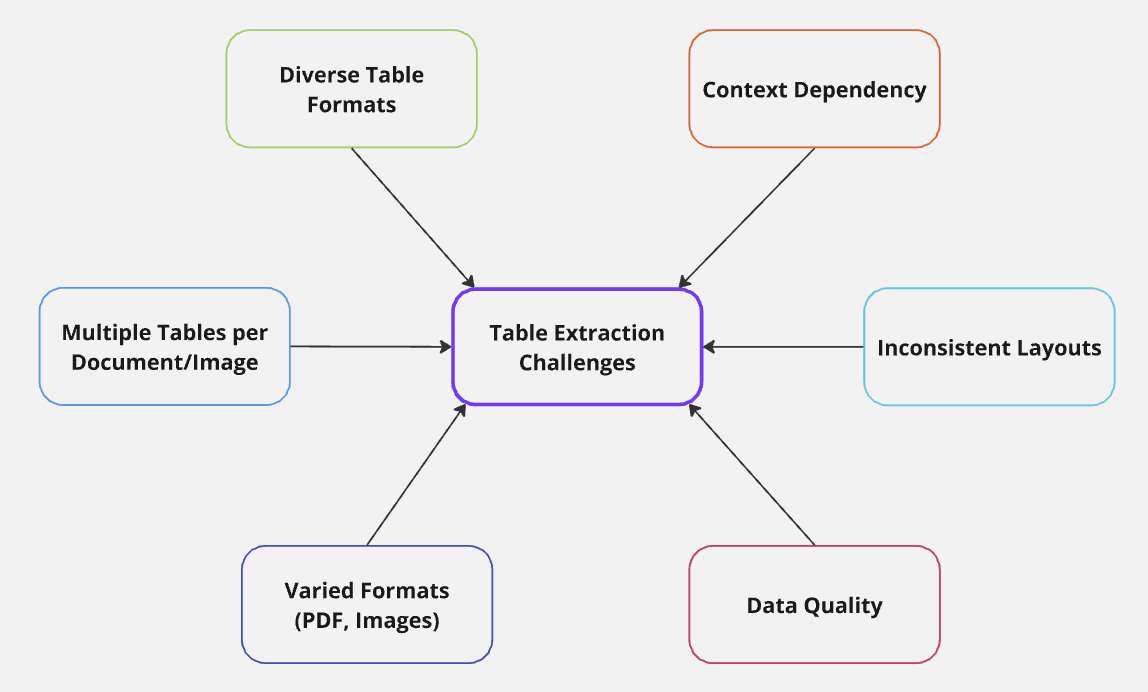
Table extraction refers to the process of identifying, and extracting structured data from tables embedded within documents. The primary goal of table extraction is to convert the data within embedded tables into a structured format (e.g., CSV, Excel, Markdown, JSON) that accurately reflects the table’s rows, columns, and cell contents. This structured data can then be easily analyzed, manipulated, and integrated into various data processing workflows.
Table extraction has wide-ranging applications across various industries, here are a few examples of use-cases where converting unstructured tabular data into actionable insights is key:
- Financial Analysis: Table extraction is used to process financial reports, balance sheets, and income statements. This enables quick compilation of financial metrics for analysis, forecasting, and regulatory reporting.
- Scientific Research: Researchers use table extraction to collate experimental results from multiple published papers.
- Business Intelligence: Companies extract tabular data from sales reports, market research, and competitor analysis documents. This allows for trend analysis, performance tracking, and informed decision-making.
- Healthcare: Table extraction helps in processing patient data, lab results, and clinical trial outcomes from medical documents.
- Legal Document Processing: Law firms and legal departments use table extraction to analyze contract terms, patent claims, and case law statistics.
- Government and Public Policy: Table extraction is applied to census data, budget reports, and election results. This supports demographic analysis, policy planning, and public administration.
Tables are very versatile and are usable in so many domains. This flexibility also brings its own set of challenges which are discussed below.
- Diverse Formats: Tables come in various formats, from simple grids to complex nested structures.
- Context Dependency: Understanding a table often requires comprehending the surrounding text and document structure.
- Data Quality: Dealing with imperfect inputs, such as low-resolution scans, poorly formatted documents, or non-textual elements.
- Varied Formats: Your extraction pipeline should be able to handle multiple input file formats.
- Multiple Tables per Document/Image: Some documents will require multiple images to be extracted individually.
- Inconsistent Layouts: Tables in real-world documents rarely adhere to a standard format, making rule-based extraction challenging:
- Complex Cell Structures: Cells often span multiple rows or columns, creating irregular grids.
- Varied Content: Cells may contain diverse elements, from simple text to nested tables, paragraphs, or lists.
- Hierarchical Information: Multi-level headers and subheaders create complex data relationships.
- Context-Dependent Interpretation: Cell meanings may rely on surrounding cells or external references.
- Inconsistent Formatting: Varying fonts, colors, and border styles convey additional meaning.
- Mixed Data Types: Tables can combine text, numbers, and graphics within a single structure.
These factors create unique layouts that resist standardized parsing, necessitating more flexible, context-aware extraction methods.
Traditional methods, including rule-based systems, and machine learning approaches, have made strides in addressing these challenges. However, they can fall short when faced with the sheer variety and complexity of real-world tables.
Large Language Models (LLMs) represent a significant advancement in artificial intelligence, particularly in natural language processing. These transformer based deep neural networks, trained on vast amounts of data, can perform a wide range of natural language processing (NLP) tasks, such as translation, summarization, and sentiment analysis. Recent developments have expanded LLMs beyond text, enabling them to process diverse data types including images, audio, and video, thus achieving multimodal capabilities that mimic human-like perception.
In table extraction, LLMs are being leveraged to process complex tabular data. Unlike traditional methods that often struggle with varied table formats in unstructured and semi-structured documents like PDFs, LLMs leverage their innate contextual understanding and pattern recognition abilities to navigate intricate table structures more effectively. Their multimodal capabilities allow for comprehensive interpretation of both textual and visual elements within documents, enabling them to more accurately extract and organize information. The question is, are LLMs actually a reliable method for consistently and accurately extracting tables from documents? Before we answer this question, let’s understand how table information was extracted using older methods.
Table extraction relied primarily on three main approaches:
- rule-based systems,
- traditional machine learning methods, and
- computer vision methods
Each of these approaches has its own strengths and limitations, which have shaped the evolution of table extraction techniques.
Rule-based Approaches:
Rule-based approaches were among the earliest methods used for table detection and extraction. These systems rely on extracting text from OCR with bounding boxes for each word followed by a predefined sets of rules and heuristics to identify and extract tabular data from documents.
How Rule-based Systems Work
- Layout Analysis: These systems typically start by analyzing the document layout, looking for visual cues that indicate the presence of a table, such as grid lines or aligned text.
- Pattern Recognition: They use predefined patterns to identify table structures, such as regular spacing between columns or consistent data formats within cells.
- Cell Extraction: Once a table is identified, rule-based systems determine the boundaries of each cell based on the detected layout, such as grid lines or consistent spacing, and then capture the data within those boundaries.
This approach can work well for documents with highly consistent and predictable formats, but will begin to struggle with more complex or irregular tables.
Advantages of Rule-based Approaches
- Interpretability: The rules are often straightforward and easy for humans to understand and modify.
- Precision: For well-defined table formats, rule-based systems can achieve high accuracy.
Limitations of Rule-based Approaches
- Lack of Flexibility: Rule-based systems struggle to generalize extraction on tables that deviate from expected formats or lack clear visual cues. This can limit the system’s applicability across different domains.
- Complexity in Rule Creation: As table formats become more diverse, the number of rules required grows exponentially, making the system difficult to maintain.
- Difficulty with Unstructured Data: These systems often fail when dealing with tables embedded in unstructured text or with inconsistent formatting.
Machine Learning Approaches
As the limitations of rule-based systems became apparent, researchers turned to machine learning techniques to improve table extraction capabilities. A typical machine learning workflow would also rely on OCR followed by ML models on top of words and word-locations.
Common Machine Learning Techniques for Table Extraction
- Support Vector Machines (SVM): Used for classifying table regions and individual cells based on features like text alignment, spacing, and formatting.
- Random Forests: Employed for feature-based table detection and structure recognition, leveraging decision trees to identify diverse table layouts and elements.
- Conditional Random Fields (CRF): Applied to model the sequential nature of table rows and columns. CRFs are particularly effective in capturing dependencies between adjacent cells.
- Neural Networks: Early applications of neural networks for table structure recognition and cell classification. More recent approaches include deep learning models like Convolutional Neural Networks (CNNs) for image-based table detection and Recurrent Neural Networks (RNNs) for understanding relationships between cells in a table, we will cover these in depth in the next section.
Advantages of Machine Learning Approaches
- Improved Flexibility: ML models can learn to recognize a wider variety of table formats compared to rule-based systems.
- Adaptability: With proper training data, ML models can be adapted to new domains more easily than rewriting rules.
Challenges in Machine Learning Approaches
- Data Dependency: The performance of ML models heavily depends on the quality and quantity of training data, which can be expensive and time-consuming to collect and label.
- Feature Engineering: Traditional ML approaches often require careful feature engineering, which can be complex for diverse table formats.
- Scalability Issues: As the variety of table formats increases, the models may require frequent retraining and updating to maintain accuracy.
- Contextual Understanding: Many traditional ML models struggle with understanding the context surrounding tables, which is often crucial for correct interpretation.
Deep Learning Approaches
With the rise of computer vision over the last decade there have been several deep learning architectures that try to solve table extraction. Typically, these models are some variation of object-detection models where the objects that being detected are “tables”, “columns”, “rows”, “cells” and “merged cells”.
Some of the well known architectures in this domain are
- Table Transformers – A variation of DETR that has been trained exclusively for Table detection and recognition. This known for its simplicity and reliability on a lot of variety of images.
- MuTabNet – One of the top performers on PubTabNet dataset, this model has 3 components, CNN backbone, HTML decoder and a Cell decoder. Dedicating specialized models for specific tasks is one of it’s reasons for such performance
- TableMaster is one more transformer based model that uses four different tasks in synergy to solve table extraction. Structure Recognition, Line Detection, Box Assignment and Matching Pipeline.
Irrespective of the model, all these architectures are responsible for creating the bounding boxes and rely on OCR for placing the text in the right boxes. On top of being extremely compute intensive and time consuming, all the drawbacks of traditional machine learning models still apply here with the only added advantage of not having to do any feature engineering.
While rule-based, traditional machine learning and deep-learning approaches have made significant contributions to table extraction, they often fall short when faced with the enormous variety and complexity of real-world documents. These limitations have paved the way for more advanced techniques, including the application of Large Language Models, which we will explore in the next section.
Traditional table extraction approaches work well in many circumstances, but there is no doubt of the impact of LLMs on the space. As discussed above, while LLMs were originally designed for natural language processing tasks, they have demonstrated strong capabilities in understanding and processing tabular data. This section introduces key LLMs and explores how they’re advancing the state of the art (SOTA) in table extraction.
Some of the most prominent LLMs include:
- GPT (Generative Pre-trained Transformer): Developed by OpenAI, GPT models (such as GPT-4 and GPT-4o) are known for their ability to generate coherent and contextually relevant text. They can understand and process a wide range of language tasks, including table interpretation.
- BERT (Bidirectional Encoder Representations from Transformers): Created by Google, BERT excels at understanding the context of words in text. Its bidirectional training allows it to grasp the full context of a word by looking at the words that come before and after it.
- T5 (Text-to-Text Transfer Transformer): Developed by Google, T5 treats every NLP task as a “text-to-text” problem, which allows it to be applied to a wide range of tasks.
- LLaMA (Large Language Model Meta AI): Created by Meta AI, LLaMA is designed to be more efficient and accessible (open source) than some other larger models. It has shown strong performance across various tasks and has spawned numerous fine-tuned variants.
- Gemini: Developed by Google, Gemini is a multimodal AI model capable of processing and understanding text, images, video, and audio. Its ability to work across different data types makes it particularly interesting for complex table extraction tasks.
- Claude: Created by Anthropic, Claude is known for its strong language understanding and generation capabilities. It has been designed with a focus on safety and ethical considerations, which can be particularly valuable when handling sensitive data in tables.
These LLMs represent the cutting edge of AI language technology, each bringing unique strengths to the table extraction task. Their advanced capabilities in understanding context, processing multiple data types, and generating human-like responses are pushing the boundaries of what’s possible in automated table extraction.
LLM Capabilities in Understanding and Processing Tabular Data
LLMs have shown impressive capabilities in handling tabular data, offering several advantages over traditional methods:
- Contextual Understanding: LLMs can understand the context in which a table appears, including the surrounding text. This allows for more accurate interpretation of table contents and structure.
- Flexible Structure Recognition: These models can recognize and adapt to various table structures including complex, unpredictable, and non-standard layouts with more flexibility than rule-based systems. Think of merged cells or nested tables. Keep in mind that while they are more fit for complex tables than traditional methods, LLMs are not a silver bullet and still have inherent challenges that will be discussed later in this paper.
- Natural Language Interaction: LLMs can answer questions about table contents in natural language, making data extraction more intuitive and user-friendly.
- Data Imputation: In cases where table data is incomplete or unclear, LLMs can sometimes infer missing information based on context and general knowledge. This however will need to be carefully monitored as there is risk of hallucination (we will discuss this in depth later on!)
- Multimodal Understanding: Advanced LLMs can process both text and image inputs, allowing them to extract tables from various document formats, including scanned images. Vision Language Models (VLMs) can be used to identify and extract tables and figures from documents.
- Adaptability: LLMs can be fine-tuned on specific domains or table types, allowing them to specialize in particular areas without losing their general capabilities.
Despite their advanced capabilities, LLMs face several challenges in table extraction. Despite their ability to extract more complex and unpredictable tables than traditional OCR methods, LLMs face several limitations.
- Repeatability: One key challenge in using LLMs for table extraction is the lack of repeatability in their outputs. Unlike rule-based systems or traditional OCR methods, LLMs may produce slightly different results even when processing the same input multiple times. This variability can hinder consistency in applications requiring precise, reproducible table extraction.
- Black Box: LLMs operate as black-box systems, meaning that their decision-making process is not easily interpretable. This lack of transparency complicates error analysis, as users cannot trace how or why the model reached a particular output. In table extraction, this opacity can be problematic, especially when dealing with sensitive data where accountability and understanding of the model’s behavior are essential.
- Fine Tuning: In some cases, fine-tuning may be required to perform effective table extraction. Fine-tuning is a resource intensive task that requires substantial amounts of labeled examples, computational power, and expertise.
- Domain Specificity: In general, LLMs are versatile, but they can struggle with domain-specific tables that contain industry jargon or highly specialized content. In these cases, there is likely a need to fine-tune the model to gain a better contextual understanding of the domain at hand.
- Hallucination: A critical concern unique to LLMs is the risk of hallucination — the generation of plausible but incorrect data. In table extraction, this could manifest as inventing table cells, misinterpreting column relationships, or fabricating data to fill perceived gaps. Such hallucinations can be particularly problematic as they may not be immediately obvious, are presented to the user confidently, and could lead to significant errors in downstream data analysis. You will see some examples of the LLM taking creative control in the examples in the following section while creating column names.
- Scalability: LLMs face challenges in scalability when handling large datasets. As the volume of data grows, so do the computational demands, which can lead to slower processing and performance bottlenecks.
- Cost: Deploying LLMs for table extraction can be expensive. The costs of cloud infrastructure, GPUs, and energy consumption can add up quickly, making LLMs a costly option compared to more traditional methods.
- Privacy: Using LLMs for table extraction often involves processing sensitive data, which can raise privacy concerns. Many LLMs rely on cloud-based platforms, making it challenging to ensure compliance with data protection regulations and safeguard sensitive information from potential security risks. As with any AI technology, handling potentially sensitive information appropriately, ensuring data privacy and addressing ethical considerations, including bias mitigation, are paramount.
Given the advantages as well as drawbacks, community has figured out the following ways, LLMs can be used in a variety of ways to extract tabular data from documents:
- Use OCR techniques to extract documents into machine readable formats, then present to LLM.
- In case of VLMs, we can additionally pass an image of the document directly
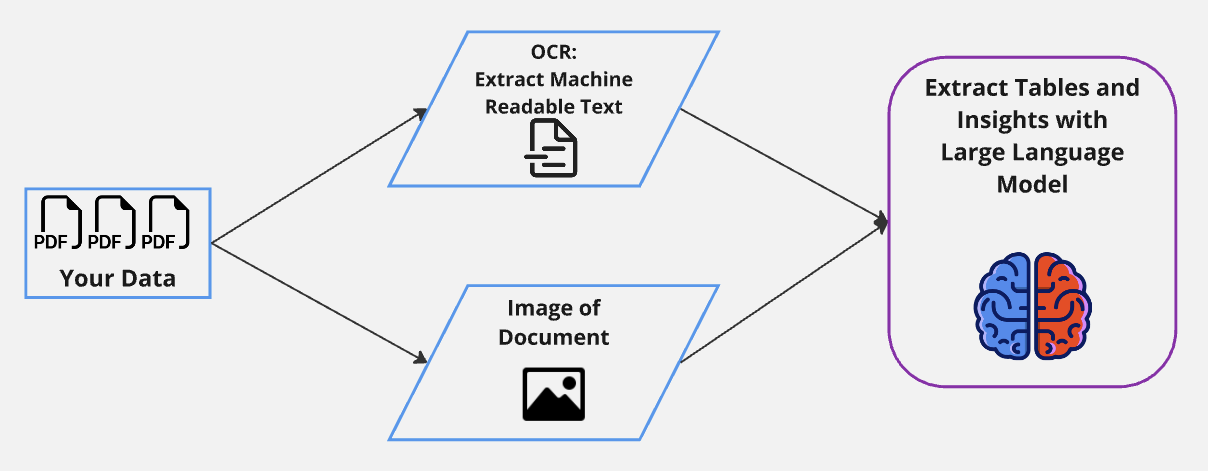
LLMs vs Traditional Techniques
When it comes to document processing, choosing between traditional techniques and OCR based LLMs depends on the specific requirements of the task. Let’s look at several aspects to evaluate when making a decision:
In practice, systems employ the approach of using OCR for initial text extraction and LLMs for deeper analysis and interpretation to achieve optimal results in document processing tasks.
Evaluating the performance of LLMs in table extraction is a complex task due to the variety of table formats, document types, and extraction requirements. Here’s an overview of common benchmarking approaches and metrics:
Common Benchmarking Datasets
- SciTSR (Scientific Table Structure Recognition Dataset): Contains tables from scientific papers, challenging due to their complex structures.
- TableBank: A large-scale dataset with tables from scientific papers and financial reports.
- PubTabNet: A large dataset of tables from scientific publications, useful for both structure recognition and content extraction.
- ICDAR (International Conference on Document Analysis and Recognition) datasets: Various competition datasets focusing on document analysis, including table extraction.
- Vision Document Retrieval (ViDoRe): Benchmark: Focused on document retrieval performance evaluation on visually rich documents holding tables, images, and figures.
Key Performance Metrics
Evaluating the performance of table extraction is a complex task, as performance not only involves extracting the values held within a table, but also the structure of the table. Elements that can be evaluated include cell content, as well as structural elements like cell topology (layout), and location.
- Precision: The proportion of correctly extracted table elements out of all extracted elements.
- Recall: The proportion of correctly extracted table elements out of all actual table elements in the document.
- F1 Score: The harmonic mean of precision and recall, providing a balanced measure of performance.
- TEDS (Tree Edit Distance based Similarity): A metric specifically designed to evaluate the accuracy of table extraction tasks. It measures the similarity between the extracted table’s structure and the ground truth table by calculating the minimum number of operations (insertions, deletions, or substitutions) required to transform one tree representation of a table into another.
- GriTS (Grid Table Similarity): GriTS is a table structure recognition (TSR) evaluation framework for measuring the correctness of extracted table topology, content, and location. It uses metrics like precision and recall, and calculates partial correctness by scoring the similarity between predicted and actual table structures, instead of requiring an exact match.
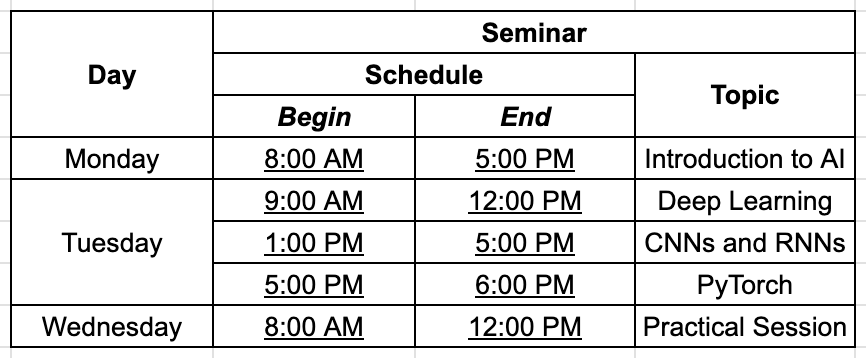
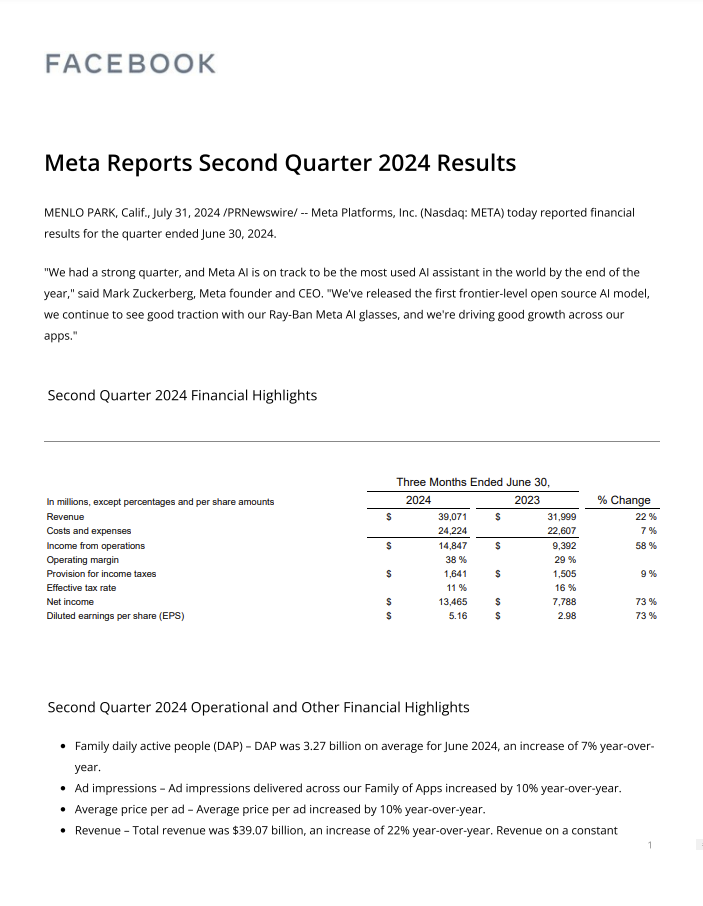
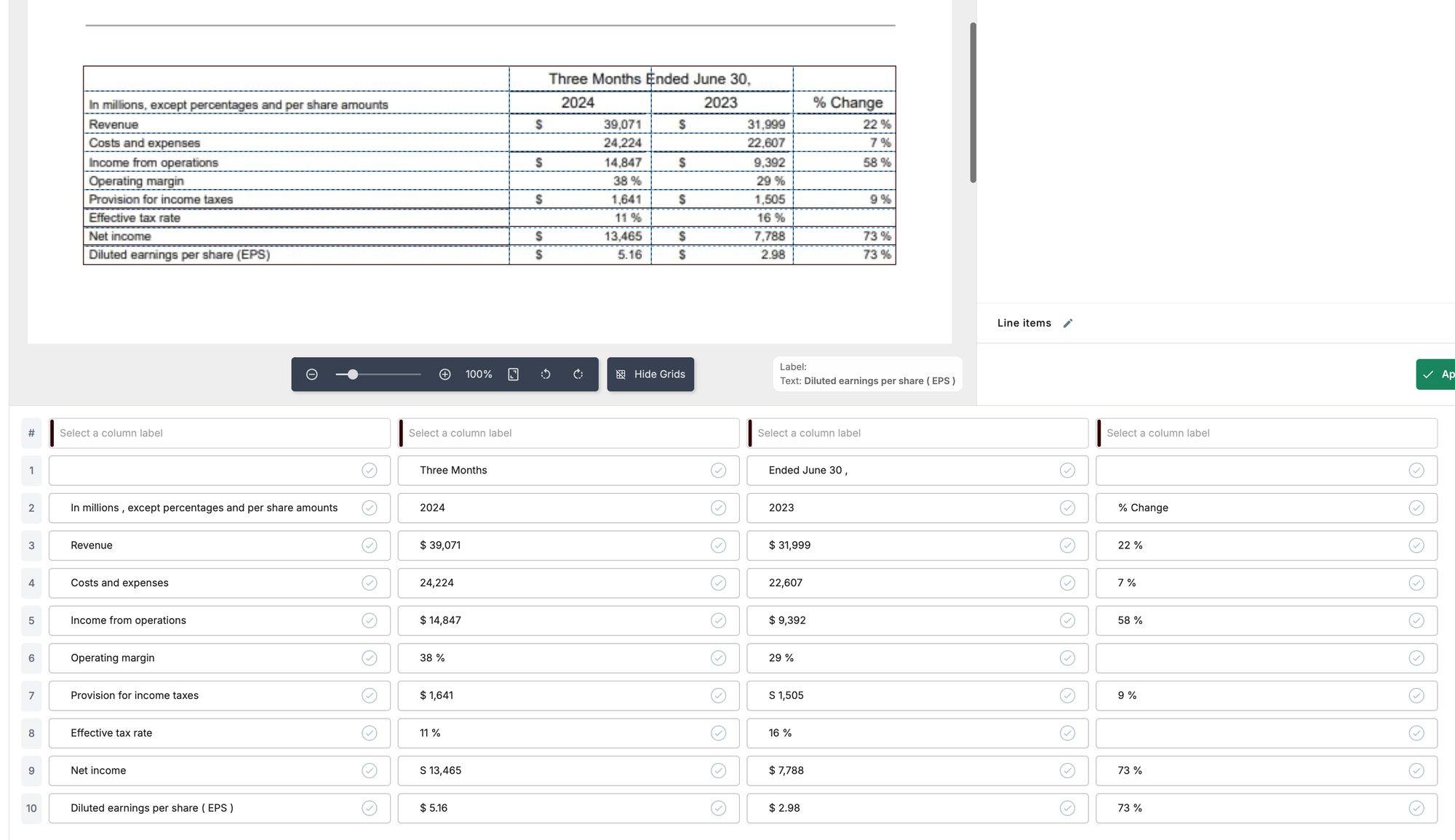
In this section, we will code the implementation of table extraction using an LLM. We will extract a table from the first page of a Meta earnings report as seen here:
This process will cover the following key steps:
- OCR
- Call LLM APIs to extract tables
- Parsing the APIs output
- Finally, reviewing the result
1. Pass Document to OCR Engine like Nanonets:
import requests
import base64
import json
url = "https://app.nanonets.com/api/v2/OCR/FullText"
payload = {"urls": ["MY_IMAGE_URL"]}
files = [
(
"file",
("FILE_NAME", open("/content/meta_table_image.png", "rb"), "application/pdf"),
)
]
headers = {}
response = requests.request(
"POST",
url,
headers=headers,
data=payload,
files=files,
auth=requests.auth.HTTPBasicAuth("XXX", ""),
)
def extract_words_text(data):
# Parse the JSON-like string
parsed_data = json.loads(data)
# Navigate to the 'words' array
words = parsed_data["results"][0]["page_data"][0]["words"]
# Extract only the 'text' field from each word and join them
text_only = " ".join(word["text"] for word in words)
return text_only
extracted_text = extract_words_text(response.text)
print(extracted_text)
OCR Result:
FACEBOOK Meta Reports Second Quarter 2024 Results MENLO PARK Calif. July 31.2024 /PRNewswire/ Meta Platforms Inc (Nasdag METAX today reported financial results for the quarter ended June 30, 2024 "We had strong quarter and Meta Al is on track to be the most used Al assistant in the world by the end of the year said Mark Zuckerberg Meta founder and CEC "We've released the first frontier-level open source Al model we continue to see good traction with our Ray-Ban Meta Al glasses and we're driving good growth across our apps Second Quarter 2024 Financial Highlights Three Months Ended June 30 In millions excent percentages and ner share amounts 2024 2023 % Change Revenue 39.071 31.999 22 Costs and expenses 24.224 22.607 7% Income from onerations 14.847 9302 58 Operating margin 38 29 Provision for income taxes 1.64 1505 0.0 Effective tax rate 11 16 % Net income 13.465 7.789 73 Diluted earnings per share (FPS 5.16 2.0 73 Second Quarter 2024 Operational and Other Financial Highlights Family daily active people (DAPY DAP was 3.27 billion on average for June 2024, an increase of 7% year -over vear Ad impressions Ad impressions delivered across our Family of Apps increased by 10% year -over-vear Average price per ad Average price per ad increased by 10% vear -over-year Revenue Total revenue was $39.07 billion an increase of 22% year-over -year Revenue or a constantDiscussion: The result is formatted as a long string of text, and while overall the accuracy is fair, there are some words and numbers that were extracted incorrectly. This highlights one area where using LLMs to process this extraction could be beneficial, as the LLM can use surrounding context to understand the text even with the words that are extracted incorrectly. Keep in mind that if there are issues with the OCR results of numeric content in tables, it is unlikely the LLM could fix this – this means that we should carefully check the output of any OCR system. An example in this case is one of the actual table values ‘9,392’ was extracted incorrectly as ‘9302’.
2. Send extracted text to LLMs and parse the output:
Now that we have our text extracted using OCR, let’s pass it to several different LLMs, instructing them to extract any tables detected within the text into Markdown format.
A note on prompt engineering: When testing LLM table extraction, it is possible that prompt engineering could improve your extraction. Aside from tweaking your prompt to increase accuracy, you could give custom instructions for example extracting the table into any format (Markdown, JSON, HTML, etc), and to give a description of each column within the table based on surrounding text and the context of the document.
OpenAI GPT-4:
%pip install openai
from openai import OpenAI
# Set your OpenAI API key
client = OpenAI(api_key='OpenAI_API_KEY')
def extract_table(extracted_text):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant that extracts table data into Markdown format."},
{"role": "user", "content": f"Here is text that contains a table or multiple tables:\n{extracted_text}\n\nPlease extract the table."}
]
)
return response.choices[0].message.content
extract_table(extracted_text)Results:
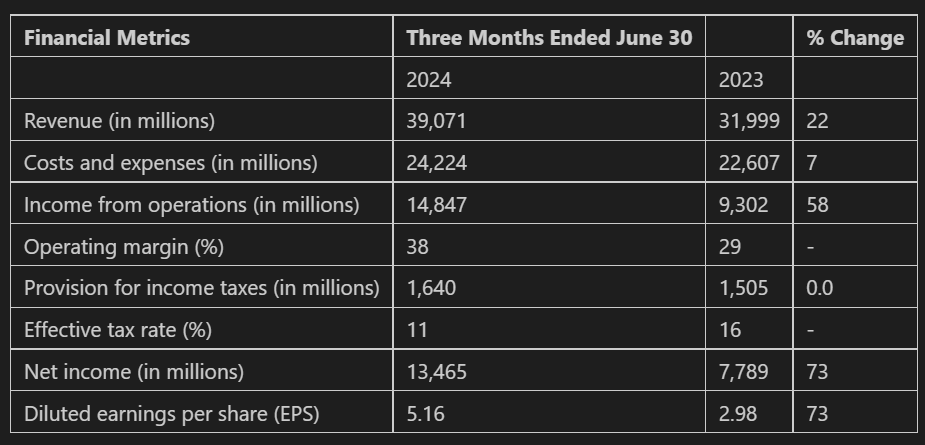
Discussion: The values extracted from the text are placed into the table correctly and the general structure of the table is representative. The cells that should not have a value within them correctly have a ‘-’. However, there are a few interesting phenomena. Firstly, the LLM gave the first column the name ‘Financial Metrics’, which is not in the original document. It also appended ‘(in millions’ and (%) onto several financial metric names. These additions make sense within the context, but it is not an exact extraction. Secondly, the column name ‘Three Months Ended June 30’ should span across both 2024 and 2023.
Google gemini-pro:
import google.generativeai as genai
# Set your Gemini API key
genai.configure(api_key="Your_Google_AI_API_KEY")
def extract_table(extracted_text):
# Set up the model
model = genai.GenerativeModel("gemini-pro")
# Create the prompt
prompt = f"""Here is text that contains a table or multiple tables:
{extracted_text}
Please extract the table and format it in Markdown."""
# Generate the response
response = model.generate_content(prompt)
# Return the generated content
return response.text
result = extract_table(extracted_text)
print(result)
Result:
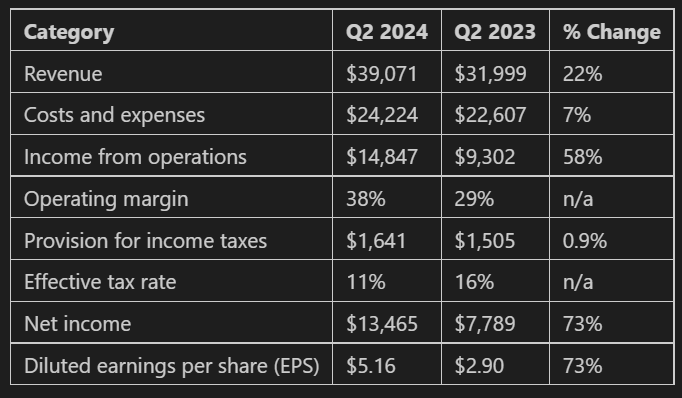
Discussion: Again, the extracted values are in the correct places. The LLM created some column names including ‘Category’, ‘Q2 2024’, and ‘Q2 2023’, while leaving out ‘Three Months Ended June 30’. Gemini decided to put ‘n/a’ in cells that had no data, rather than ‘-’. Overall the extraction looks good in content and structure based on the context of the document, but if you were looking for an exact extraction, this is not exact.
Mistral-Nemo-Instruct
import requests
def query_huggingface_api(prompt, model_name="mistralai/Mistral-Nemo-Instruct-2407"):
API_URL = f"https://api-inference.huggingface.co/models/{model_name}"
headers = {"Authorization": f"Bearer YOUR_HF_TOKEN"}
payload = {
"inputs": prompt,
"parameters": {
"max_new_tokens": 1024,
"temperature": 0.01, # low temperature, reduce creativity for extraction
},
}
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
prompt = f"Here is text that contains a table or multiple tables:\n{extracted_text}\n\nPlease extract the table in Markdown format."
result = query_huggingface_api(prompt)
print(result)
# Extracting the generated text
if isinstance(result, list) and len(result) > 0 and "generated_text" in result[0]:
generated_text = result[0]["generated_text"]
print("\nGenerated Text:", generated_text)
else:
print("\nError: Unable to extract generated text.")
Result:
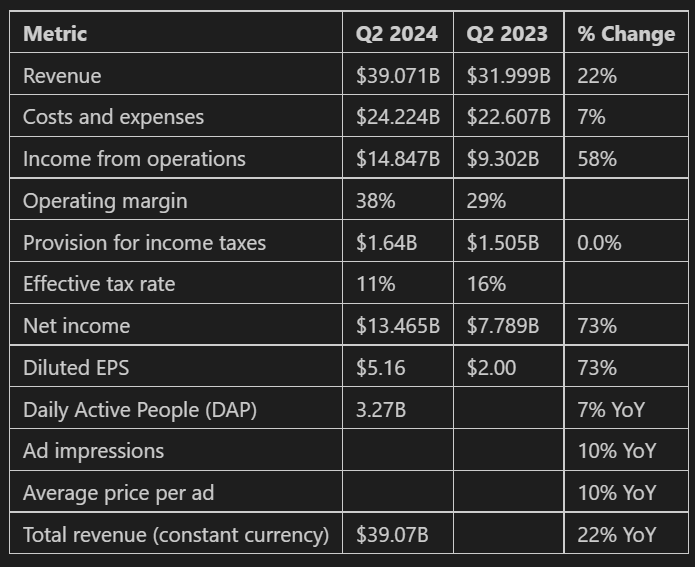
Discussion: Mistral-Nemo-Instruct, is a less powerful LLM than GPT-4o or Gemini and we see that the extracted table is less accurate. The original rows in the table are represented well, but the LLM interpreted the bullet points at the bottom of the document page to be a part of the table as well, which should not be included.
Prompt Engineering
Let’s do some prompt engineering to see if we can improve this extraction:
prompt = f"Here is text that contains a table or multiple tables:\n{extracted_text}\n\nPlease extract the table 'Second Quarter 2024 Financial Highlights' in Markdown format. Make sure to only extract tables, not bullet points."
result = query_huggingface_api(prompt)Result:
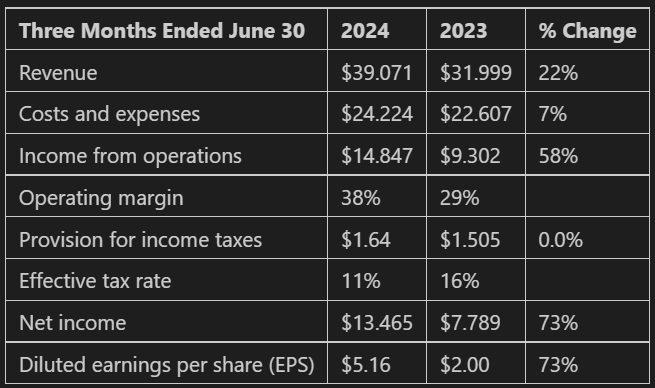
Discussion: Here, we engineer the prompt to specify the title of the table we want extracted, and remind the model to only extract tables, not bullet points. The results are significantly improved from the initial prompt. This shows we can use prompt engineering to improve results, even with smaller models.
Nanonets
With a few clicks on the website and within a minute, the author could extract all the data. The UI gives the provision to verify and correct the outputs if needed. In this case there was no need for corrections.
Blurry Image Demonstration
Next, we will try to extract a table out of a lower quality scanned document. This time we will use the Gemini pipeline implemented above and see how it does:

Result:
Discussion: The extraction was not accurate at all! It seems that the low quality of the scan has a drastic impact on the LLMs ability to extract the embedded elements. What would happen if we zoomed in on the table?
Zoomed In Blurry Table
Result:
Discussion: Still, this method falls short, the results are slightly improved but still quite inaccurate. The problem is we are passing the data from the original document through so many steps, OCR, to prompt engineering, to LLM extraction, it is difficult to ensure a quality extraction.
Takeaways:
- LLMs like GPT-4o, Gemini, and Mistral can be used to extract tables from OCR extractions, with the ability to output in various formats such as Markdown or JSON.
- The accuracy of the LLM extracted table depends heavily on the quality of the OCR text extraction.
- The flexibility to give instructions to the LLM on how to extract and format the table is one advantage over traditional table extraction methods.
- LLM-based extraction can be accurate in many cases, but there’s no guarantee of consistency across multiple runs. The results may vary slightly each time.
- The LLM sometimes makes interpretations or additions that, while logical in context, may not be exact reproductions of the original table. For example, it might create column names that weren’t in the original table.
- The quality and format of the input image significantly impact the OCR process and LLM’s extraction accuracy.
- Complex table structures (e.g., multi-line cells) can confuse the LLM, leading to incorrect extractions.
- LLMs can handle multiple tables in a single image, but the accuracy may vary depending on the quality of the OCR step.
- While LLMs can be effective for table extraction, they act as a “black box,” making it difficult to predict or control their exact behavior.
- The approach requires careful prompt engineering and potentially some pre-processing of images (like zooming in on tables) to achieve optimal results.
- This method of table extraction using OCR and LLMs could be particularly useful for applications where flexibility and handling of various table formats are required, but may not be ideal for scenarios demanding 100% consistency and accuracy, or low quality document image.
Vision Language Models (VLMs)
Vision Language Models (VLMs) are generative AI models that are trained on images as well as text and are considered multimodal – this means we can send an image of a document directly to a VLM for extraction and analytics. While OCR techniques implemented above are useful for standardized, consistent, and clean document extraction – the ability to pass an image of a document directly to the LLM could potentially improve the results as there is no need to rely on the accuracy of OCR transcriptions.
Let’s take the example we implemented on the blurry image above, but pass it straight to the model rather than go through the OCR step first. In this case we will use the gemini-1.5-flash VLM model:
Zoomed In Blurry Table:
Gemini-1.5-flash implementation:
from PIL import Image
def extract_table(image_path):
# Set up the model
model = genai.GenerativeModel("gemini-1.5-flash")
image = Image.open(image_path)
# Create the prompt
prompt = f"""Here is text that contains a table or multiple tables - Please extract the table and format it in Markdown."""
# Generate the response
response = model.generate_content([prompt, image])
# Return the generated content
return response.text
result = extract_table("/content/Screenshot_table.png")
print(result)
Result:

Discussion: This method worked and correctly extracted the blurry table. For tables where OCR might have trouble getting an accurate recognition, VLMs can fill in the gap. This is a powerful technique, but the challenges we talked about earlier in the article still apply to VLMs. There is no guarantee of consistent extractions, there is risk of hallucination, prompt engineering could be required, and VLMs are still black box models.
Recent Advancements in VLMs
As you can tell, VLMs will be the next logical step to LLMs where on top of text, the model will also process images. Given the vast nature of the field, we have dedicated a whole article summarizing the key insights and takeaways.
Bridging Images and Text – a Survey of VLMs
Distilling insights from over 50 arXiv papers, let’s explore the current state-of-the-art models, with dedicated discussions on documents based models, datasets and benchmarks.

A comprehensive survey of VLMs
To summarize, VLMs are hybrids of vision models and LLMs that try to align image inputs with text inputs to perform all the tasks that LLMs. Even though there are dozens of reliable architectures and models available as of now, more and more models are being released on a weekly basis and we are yet to see a stagnation in terms of field’s true capabilities.
Cognizant to the drawbacks of LLMs, Nanonets has used several guardrails to ensure the extracted tables are accurate and reliable.
- We convert the OCR output into a rich text format to help the LLM understand the structure and placement of content in the original document.
- The rich text clearly highlights all the required fields, ensuring the LLM can easily distinguish between the content and the desired information.
- All the prompts have been meticulously engineered to minimize hallucinations
- We include validations both within the prompt and after the predictions to ensure that the extracted fields are always accurate and meaningful.
- In cases of tricky and hard to decipher layouts, nanonets has mechanisims to help the LLM with examples to boost the accuracy.
- Nanonets has devised algorithms to deduce LLMs correctness and reliably give low confidence to predictions where LLM can be hallucinating.
Online Image to Excel Convert – PNG & JPG to Excel
Online Tool to Extract Data and Convert Image to Excel. Convert PNG & JPG to Excel CSV files within seconds using Nanonets.
Extract table information using Nanonets in under a minute.
Nanonets offers a versatile and powerful approach to table extraction, leveraging advanced AI technologies to cater to a wide range of document processing needs. Their solution stands out for its flexibility and comprehensive feature set, addressing various challenges in document analysis and data extraction.
- Zero-Training AI Extraction: Nanonets provides pre-trained models capable of extracting data from common document types without requiring additional training. This out-of-the-box functionality allows for immediate deployment in many scenarios, saving time and resources.
- Custom Model Training: Nanonets offers the ability to train custom models. Users can fine-tune extraction processes on their specific document types, enhancing accuracy for particular use cases.
- Full-Text OCR: Beyond extraction, Nanonets incorporates robust Optical Character Recognition (OCR) capabilities, enabling the conversion of entire documents into machine-readable text.
- Pre-trained Models for Common Documents: Nanonets offers a library of pre-trained models optimized for frequently encountered document types such as receipts and invoices.
- Flexible Table Extraction: The platform supports both automatic and manual table extraction. While AI-driven automatic extraction handles most cases, the manual option allows for human intervention in complex or ambiguous scenarios, ensuring accuracy and control.
- Document Classification: Nanonets can automatically categorize incoming documents, streamlining workflows by routing different document types to appropriate processing pipelines.
- Custom Extraction Workflows: Users can create tailored document extraction workflows, combining various features like classification, OCR, and table extraction to suit specific business processes.
- Minimal and No Code Setup: Unlike traditional methods that may require installing and configuring multiple libraries or setting up complex environments, Nanonets offers a cloud-based solution that can be accessed and implemented with minimal setup. This reduces the time and technical expertise needed to get started. Users can often train custom models by simply uploading sample documents and annotating them through the interface.
- User-Friendly Interface: Nanonets provides an intuitive web interface for many tasks, reducing the need for extensive coding. This makes it accessible to non-technical users who might struggle with code-heavy solutions.
- Quick Deployment & Low Technical Debt: Pre-trained models, easy retraining, and configuration-based updates allow for rapid scaling without needing extensive coding or system redesigns.
By addressing these common pain points, Nanonets offers a more accessible and efficient approach to table extraction and document processing. This can be particularly valuable for organizations looking to implement these capabilities without investing in extensive technical resources or enduring long development cycles.
Conclusion
The landscape of table extraction technology is undergoing a significant transformation with the application of LLMs and other AI driven tools like Nanonets. Our review has highlighted several key insights:
- Traditional methods, while still valuable and are proven for simple extractions, can struggle with complex and varied table formats, especially in unstructured documents.
- LLMs have demonstrated flexible capabilities in understanding context, adapting to diverse table structures, and in some cases can extract data with improved accuracy and flexibility.
- While LLMs can present unique advantages to table extraction such as contextual understanding, they are not as consistent as tried and true OCR methods. It is likely a hybrid approach is the correct path.
- Tools like Nanonets are pushing the boundaries of what’s possible in automated table extraction, offering solutions that range from zero-training models to highly customizable workflows.
Emerging trends and areas for further research include:
- The development of more specialized LLMs tailored specifically for table extraction tasks and fine tuned for domain-specific use-cases and terminology.
- Enhanced methods for combining traditional OCR with LLM-based approaches in hybrid systems.
- Advancements in VLMs, reducing reliance on OCR accuracy.
It is also important to understand that the future of table extraction lies in the combination of AI capabilities alongside human expertise. While AI can handle increasingly complex extraction tasks, there are inconsistencies in these AI extractions and we saw in the demonstration section of this article.
Overall, LLMs at the very least offer us a tool to improve and analyze table extractions. At the point of writing this article, the best approach is likely combining traditional OCR and AI technologies for top extraction capabilities. However, keep in mind that this landscape changes quickly and LLM/VLM capabilities will continue to improve. Being prepared to adapt extraction strategies will continue to be forefront in data processing and analytics.


{kind=link}