
Introduction
In today’s fast-paced business world, the ability to extract relevant and accurate data from diverse sources is crucial for informed decision-making, process optimization, and strategic planning. Whether it’s analyzing customer feedback, extracting key information from legal documents, or parsing web content, efficient data extraction can provide valuable insights and streamline operations.
Enter large language models (LLMs) and their APIs – powerful tools that utilize advanced natural language processing (NLP) to understand and generate human-like text. However, it’s important to note that LLM APIs
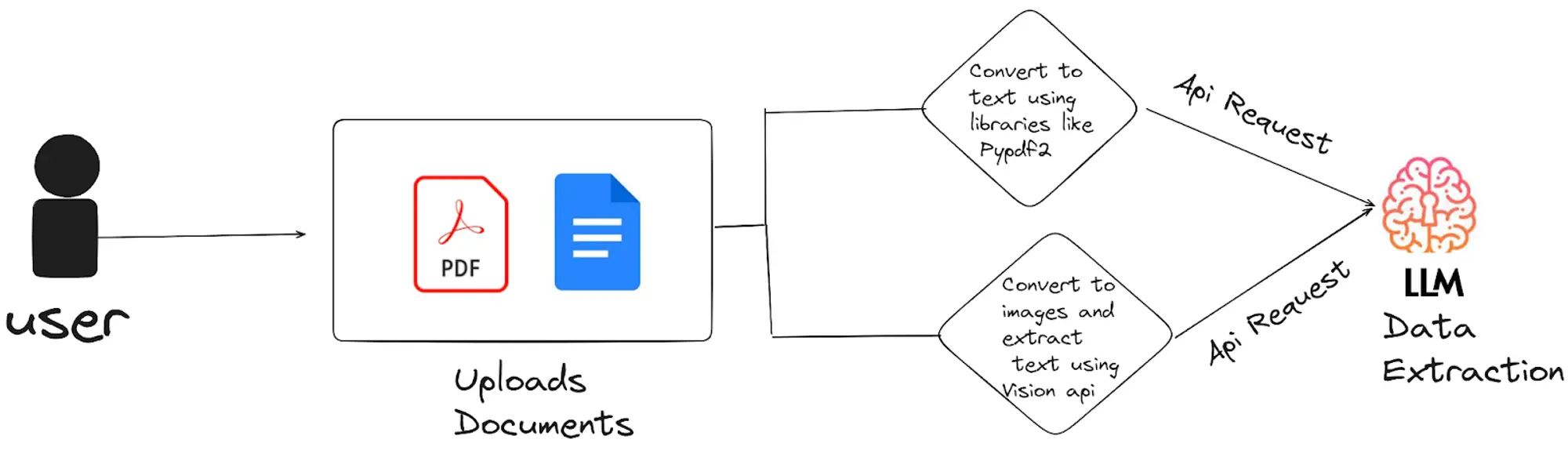
For document analysis, the typical workflow involves:
- Document Conversion to Images: While some LLM APIs process PDFs directly, converting them to images often enhances OCR accuracy, making it easier to extract text from non-searchable or poorly scanned documents
- Text Extraction Methods:
- Using Vision APIs:
Vision APIs excel at extracting text from images, even in challenging scenarios involving complex layouts, varying fonts, or low-quality scans. This approach ensures reliable text extraction from documents that are difficult to process otherwise. - Direct Extraction from Machine-Readable PDFs:
For straightforward, machine-readable PDFs, libraries like PyPDF2 can extract text directly without converting the document to images. This method is faster and more efficient for documents where the text is already selectable and searchable. - Enhancing Extraction with LLM APIs:
Today, text can be directly extracted and analyzed from image in a single step using LLMs. This integrated approach simplifies the process by combining extraction, content processing, key data point identification, summary generation, and insight provision into one seamless operation. To explore how LLMs can be applied to different data extraction scenarios, including the integration of retrieval-augmented generation techniques, see this overview of building RAG apps.
- Using Vision APIs:
In this blog, we’ll explore a few LLM APIs designed for data extraction directly from files and compare their features. Table of Contents:
- Understanding LLM APIs
- Selection Criteria for Top LLM APIs
- LLM APIs We Selected For Data Extraction
- Comparative Analysis of LLM APIs for Data Extraction
- Experiment analysis
- API Features and Pricing Analysis
- Other literature on the internet Analysis
- Conclusion
Understanding LLM APIs
What Are LLM APIs?
Large language models are artificial intelligence systems that have been trained on vast amounts of text data, enabling them to understand and generate human-like language. LLM APIs, or application programming interfaces, provide developers and businesses with access to these powerful language models, allowing them to integrate these capabilities into their own applications and workflows.
At their core, LLM APIs utilize sophisticated natural language processing algorithms to comprehend the context and meaning of text, going beyond simple pattern matching or keyword recognition. This depth of understanding is what makes LLMs so valuable for a wide range of language-based tasks, including data extraction. For a deeper dive into how these models operate, refer to this detailed guide on what large language models are.
While traditional LLM APIs primarily focus on processing and analyzing extracted text, multimodal models like ChatGPT and Gemini can also interact with images and other media types. These models don’t perform traditional data extraction (like OCR) but play a crucial role in processing, analyzing, and contextualizing both text and images, transforming data extraction and analysis across various industries and use cases.
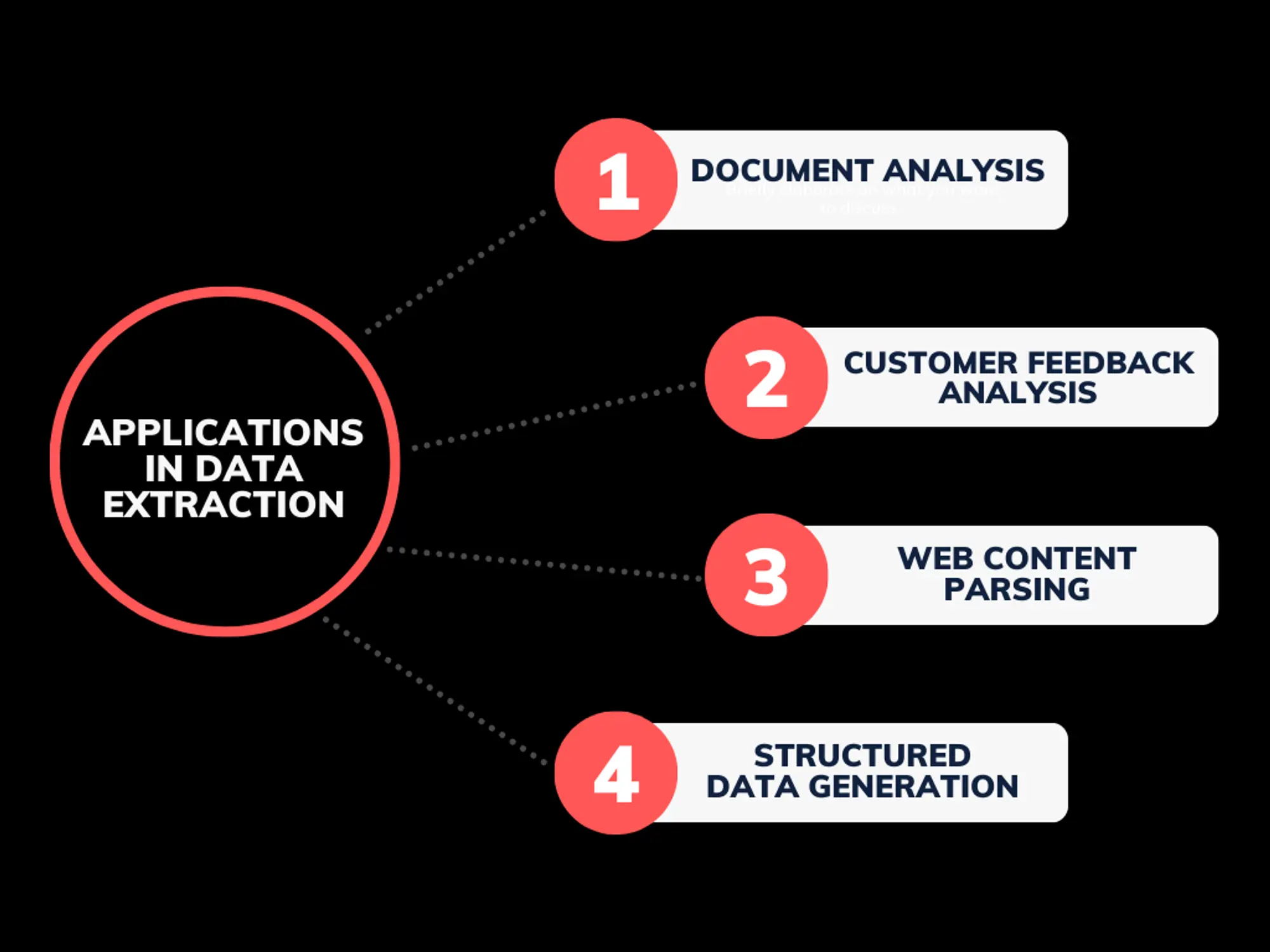
- Document Analysis: LLM APIs extract text from document images, which are then parsed to identify key information from complex documents like legal contracts, financial reports, and regulatory filings.
- Customer Feedback Analysis: After text extraction, LLM-powered sentiment analysis and natural language understanding help businesses quickly extract insights from customer reviews, surveys, and support conversations.
- Web Content Parsing: LLM APIs can be leveraged to process and structure data extracted from web pages, enabling the automation of tasks like price comparison, lead generation, and market research.
- Structured Data Generation: LLM APIs can generate structured data, such as tables or databases, from unstructured text sources extracted from reports or articles.
As you explore the world of LLM APIs for your data extraction needs, it’s important to consider the following key features that can make or break the success of your implementation:
Accuracy and Precision
Accurate data extraction is the foundation for informed decision-making and effective process automation. LLM APIs should demonstrate a high level of precision in understanding the context and extracting the relevant information from various sources, minimizing errors and inconsistencies.
Scalability
Your data extraction needs may grow over time, requiring a solution that can handle increasing volumes of data and requests without compromising performance. Look for LLM APIs that offer scalable infrastructure and efficient processing capabilities.
Integration Capabilities
Seamless integration with your existing systems and workflows is crucial for a successful data extraction strategy. Evaluate the ease of integrating LLM APIs with your business applications, databases, and other data sources.
Customization Options
While off-the-shelf LLM APIs can provide excellent performance, the ability to fine-tune or customize the models to your specific industry or use case can further enhance the accuracy and relevance of the extracted data.
Security and Compliance
When dealing with sensitive or confidential information, it’s essential to ensure that the LLM API you choose adheres to strict security standards and regulatory requirements, such as data encryption, user authentication, and access control.
Context Lengths
The ability to process and understand longer input sequences, known as context lengths, can significantly improve the accuracy and coherence of the extracted data. Longer context lengths allow the LLM to better grasp the overall context and nuances of the information, leading to more precise and relevant outputs.
Prompting Techniques
Advanced prompting methods, such as few-shot learning and prompt engineering, enable LLM APIs to better understand and respond to specific data extraction tasks. By carefully crafting prompts that guide the model’s reasoning and output, users can optimize the quality and relevance of the extracted data.
Structured Outputs
LLM APIs that can deliver structured, machine-readable outputs, such as JSON or CSV formats, are particularly valuable for data extraction use cases. These structured outputs facilitate seamless integration with downstream systems and automation workflows, streamlining the entire data extraction process.
Selection Criteria for Top LLM APIs
With these key features in mind, the next step is to identify the top LLM APIs that meet these criteria. The APIs discussed below have been selected based on their performance in real-world applications, alignment with industry-specific needs, and feedback from developers and businesses alike.
Factors Considered:
- Performance Metrics: Including accuracy, speed, and precision in data extraction.
- Complex Document Handling: The ability to handle different types of documents
- User Experience: Ease of integration, customization options, and the availability of comprehensive documentation.
Now that we’ve explored the key features to consider, let’s dive into a closer look at the top LLM APIs we’ve selected for data extraction:
OpenAI GPT-3/GPT-4 API
OpenAI API is known for its advanced GPT-4 model, which excels in language understanding and generation. Its contextual extraction capability allows it to maintain context across lengthy documents for precise information retrieval. The API supports customizable querying, letting users focus on specific details and providing structured outputs like JSON or CSV for easy data integration. With its multimodal capabilities, it can handle both text and images, making it versatile for various document types. This blend of features makes OpenAI API a robust choice for efficient data extraction across different domains.
Google Gemini API

Google Gemini API is Google’s latest LLM offering, designed to integrate advanced AI models into business processes. It excels in understanding and generating text in multiple languages and formats, making it suitable for data extraction tasks. Gemini is noted for its seamless integration with Google Cloud services, which benefits enterprises already using Google’s ecosystem. It features document classification and entity recognition, enhancing its ability to handle complex documents and extract structured data effectively.
Claude 3.5 Sonnet API
Claude 3.5 Sonnet API by Anthropic focuses on safety and interpretability, which makes it a unique option for handling sensitive and complex documents. Its advanced contextual understanding allows for precise data extraction in nuanced scenarios, such as legal and medical documents. Claude 3.5 Sonnet’s emphasis on aligning AI behavior with human intentions helps minimize errors and improve accuracy in critical data extraction tasks.
Nanonets API
Nanonets is not a traditional LLM API but is highly specialized for data extraction. It offers endpoints specifically designed to extract structured data from unstructured documents, such as invoices, receipts, and contracts. A standout feature is its no-code model retraining process—users can refine models by simply annotating documents on the dashboard. Nanonets also integrates seamlessly with various apps and ERPs, enhancing its versatility for enterprises. G2 reviews highlight its user-friendly interface and exceptional customer support, especially for handling complex document types efficiently.
In this section, we’ll conduct a thorough comparative analysis of the selected LLM APIs—Nanonets, OpenAI, Google Gemini, and Claude 3.5 Sonnet—focusing on their performance and features for data extraction.
Experiment Analysis: We will detail the experiments conducted to evaluate each API’s effectiveness. This includes an overview of the experimentation setup, such as the types of documents tested (e.g., multipage textual documents, invoices, medical records, and handwritten text), and the criteria used to measure performance. We’ll analyze how each API handles these different scenarios and highlight any notable strengths or weaknesses.
API Features and Pricing Analysis: This section will provide a comparative look at the key features and pricing structures of each API. We’ll explore aspects such as Token lengths, Rate limits, ease of integration, customization options, and more. Pricing models will be reviewed to assess the cost-effectiveness of each API based on its features and performance.
Other Literature on the Internet Analysis: We’ll incorporate insights from existing literature, user reviews, and industry reports to provide additional context and perspectives on each API. This analysis will help to round out our understanding of each API’s reputation and real-world performance, offering a broader view of their strengths and limitations.
This comparative analysis will help you make an informed decision by presenting a detailed evaluation of how these APIs perform in practice and how they stack up against each other in the realm of data extraction.
Experiment Analysis
Experimentation Setup
We tested the following LLM APIs:
- Nanonets OCR (Full Text) and Custom Model
- ChatGPT-4o-latest
- Gemini 1.5 Pro
- Claude 3.5 Sonnet
Document Types Tested:
- Multipage Textual Document: Evaluates how well APIs retain context and accuracy across multiple pages of text.
- Invoices/Receipt with Text and Tables: Assesses the ability to extract and interpret both structured (tables) and unstructured (text) data.
- Medical Record: Challenges APIs with complex terminology, alphanumeric codes, and varied text formats.
- Handwritten Document: Tests the ability to recognize and extract inconsistent handwriting.
Multipage Textual Document
Objective: Assess OCR precision and content retention. Want to be able to extract raw text from the below documents.
Metrics Used:
- Levenshtein Accuracy: Measures the number of edits required to match the extracted text with the original, indicating OCR precision.
- ROUGE-1 Score: Evaluates how well individual words from the original text are captured in the extracted output.
- ROUGE-L Score: Checks how well the sequence of words and structure are preserved.
Documents Tested:
- Red badge of courage.pdf (10 pages): A novel to test content filtering and OCR accuracy.
- Self Generated PDF (1 page): A single-page document created to avoid copyright issues.

Results
| API | Outcome | Levenshtein Accuracy | ROUGE-1 Score | ROUGE-L Score |
|---|---|---|---|---|
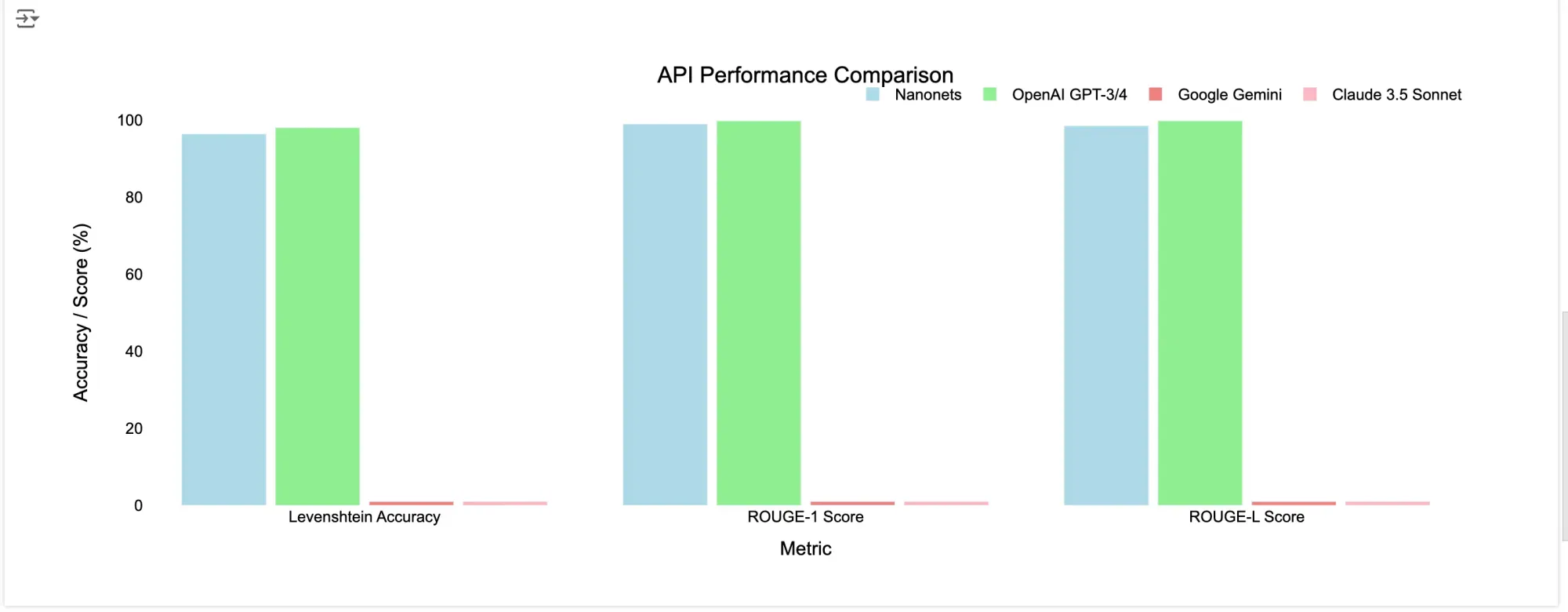
| Nanonets OCR | Success | 96.37% | 98.94% | 98.46% |
| ChatGPT-4o-latest | Success | 98% | 99.76% | 99.76% |
| Gemini 1.5 Pro | Error: Recitation |
x | x | x |
| Claude 3.5 Sonnet | Error: Output blocked by content filtering policy |
x | x | x |
| API | Outcome | Levenshtein Accuracy |
ROUGE-1 Score |
ROUGE-L Score |
|---|---|---|---|---|
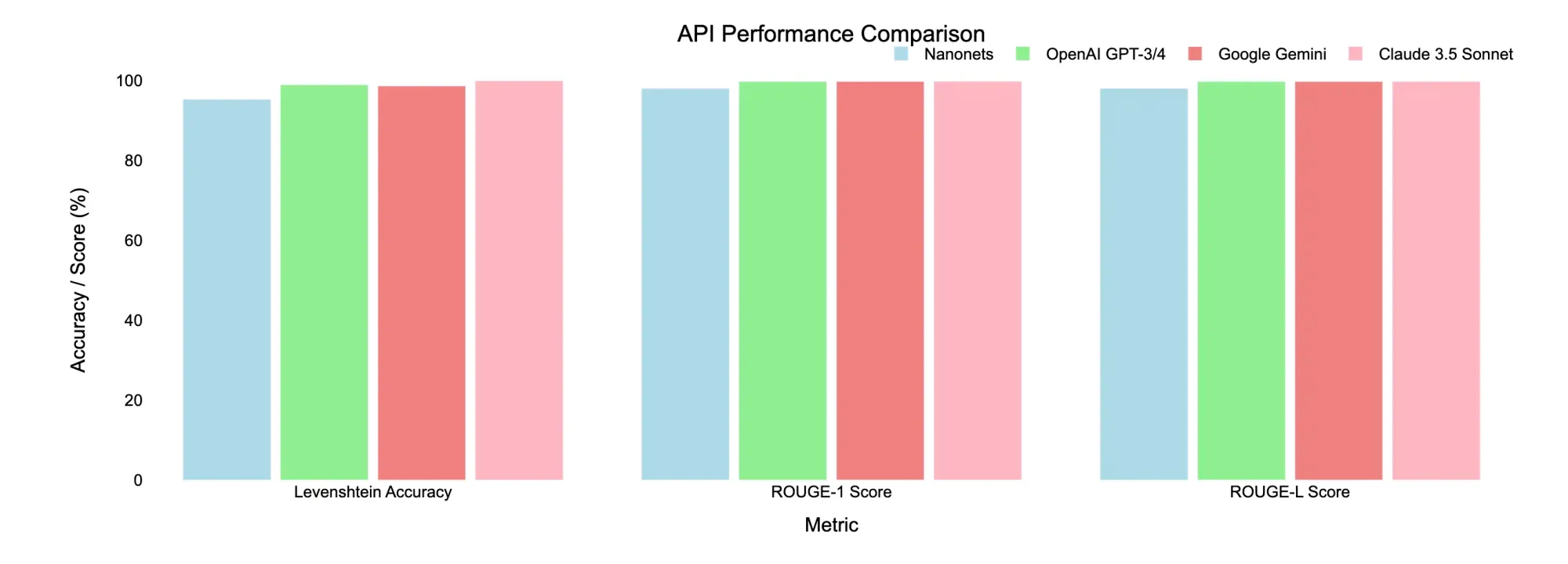
| Nanonets OCR | Success | 95.24% | 97.98% | 97.98% |
| ChatGPT-4o-latest | Success | 98.92% | 99.73% | 99.73% |
| Gemini 1.5 Pro | Success | 98.62% | 99.73% | 99.73% |
| Claude 3.5 Sonnet | Success | 99.91% | 99.73% | 99.73% |
Key Takeaways
- Nanonets OCR and ChatGPT-4o-latest consistently performed well across both documents, with high accuracy and fast processing times.
- Claude 3.5 Sonnet encountered issues with content filtering, making it less reliable for documents that might trigger such policies, however in terms of retaining the structure of the original document, it stood out as the best.
- Gemini 1.5 Pro struggled with “Recitation” errors, likely due to its content policies or non-conversational output text patterns
Conclusion: For documents that might have copyright issues, Gemini and Claude might not be ideal due to potential content filtering restrictions. In such cases, Nanonets OCR or ChatGPT-4o-latest could be more reliable choices.
💡
Overall, while both Nanonets and ChatGPT-4o-latest performed well here, the drawback with GPT was that we needed to make 10 separate requests (one for each page) and convert PDFs to images before processing. In contrast, Nanonets handled everything in a single step.
Objective: Evaluate the effectiveness of different LLM APIs in extracting structured data from invoices and receipts. This is different from just doing an OCR and includes assessing their ability to accurately identify and extract key-value pairs and tables
Metrics Used:
- Precision: Measures the accuracy of extracting key-value pairs and table data. It’s the ratio of correctly extracted data to the total number of data points extracted. High precision indicates that the API extracts relevant information accurately without including too many false positives.
- Cell Accuracy: Assesses how well the API extracts data from tables, focusing on the correctness of data within individual cells. This metric checks if the values in the cells are correctly extracted and aligned with their respective headers.
Documents Tested:
- Test Invoice An invoice with 13 key-value pairs and a table with 8 rows and 5 columns based on which we will be judging the accuracy

Results
The results are from when we performed the experiment using a generic prompt from Chatgpt, Gemini, and Claude and using a generic invoice template model for Nanonets
Key-Value Pair Extraction
| API | Crucial Key-Value Pairs Extracted | Crucial Keys Missed | Key Values with Differences |
|---|---|---|---|
| Nanonets OCR | 13/13 | None | – |
| ChatGPT-4o-latest | 13/13 | None | Invoice Date: 11/24/18 (Expected: 12/24/18), PO Number: 31.8850876 (Expected: 318850876) |
| Gemini 1.5 Pro | 12/13 | Seller Name | Invoice Date: 12/24/18, PO Number: 318850876 |
| Claude 3.5 Sonnet | 12/13 | Seller Address | Invoice Date: 12/24/18, PO Number: 318850876 |
Table Extraction
| API | Essential Columns Extracted | Rows Extracted | Incorrect Cell Values |
|---|---|---|---|
| Nanonets OCR | 5/5 | 8/8 | 0/40 |
| ChatGPT-4o-latest | 5/5 | 8/8 | 1/40 |
| Gemini 1.5 Pro | 5/5 | 8/8 | 2/40 |
| Claude 3.5 Sonnet | 5/5 | 8/8 | 0/40 |
Key Takeaways
- Nanonets OCR proved to be highly effective for extracting both key-value pairs and table data with high precision and cell accuracy.
- ChatGPT-4o-latest and Claude 3.5 Sonnet performed well but had occasional issues with OCR accuracy, affecting the extraction of specific values.
- Gemini 1.5 Pro showed limitations in handling some key-value pairs and cell values accurately, particularly in the table extraction.
Conclusion: For financial documents, using Nanonets for data extraction would be a better choice. While the other models can benefit from tailored prompting techniques to improve their extraction capabilities, OCR accuracy is something that might require custom retraining missing in the other 3. We will talk about this in more detail in a later section of the blog.
Medical Document
Objective: Evaluate the effectiveness of different LLM APIs in extracting structured data from a medical document, particularly focusing on text with superscripts, subscripts, alphanumeric characters, and specialized terms.
Metrics Used:
- Levenshtein Accuracy: Measures the number of edits required to match the extracted text with the original, indicating OCR precision.
- ROUGE-1 Score: Evaluates how well individual words from the original text are captured in the extracted output.
- ROUGE-L Score: Checks how well the sequence of words and structure are preserved.
Documents Tested:
- Italian Medical Report A single-page document with complex text including superscripts, subscripts, and alphanumeric characters.
Results
| API | Levenshtein Accuracy | ROUGE-1 Score | ROUGE-L Score |
|---|---|---|---|
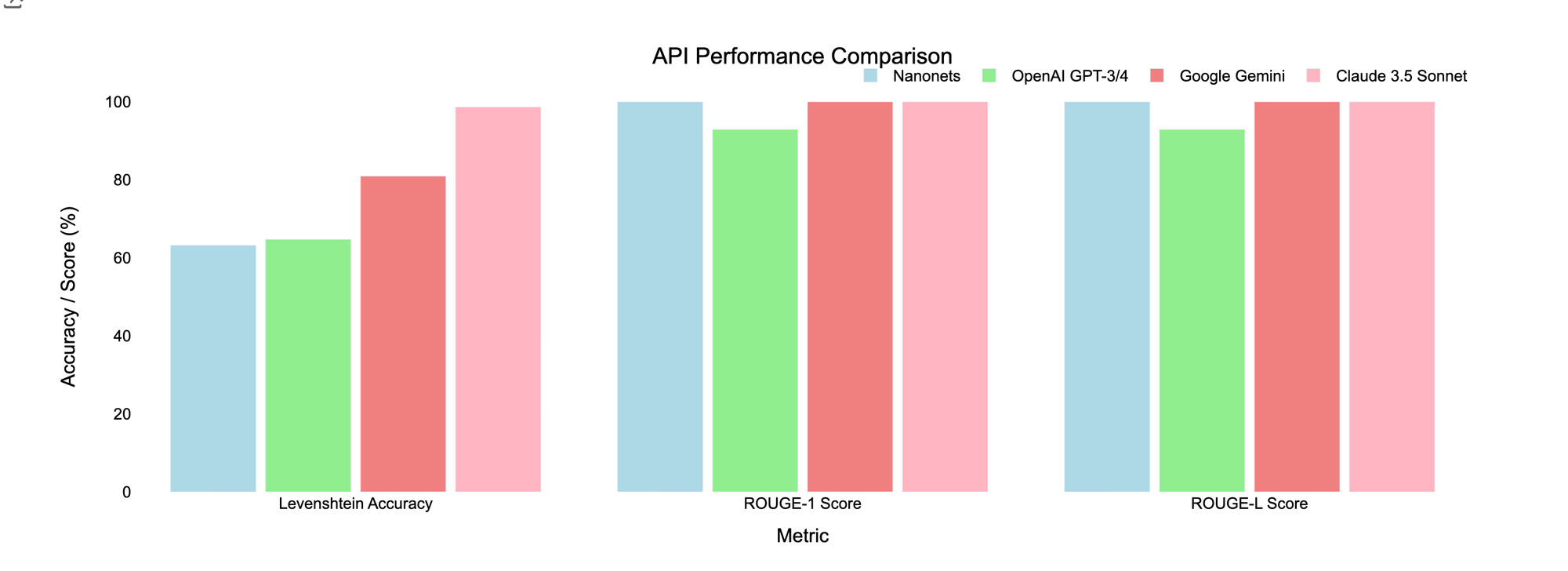
| Nanonets OCR | 63.21% | 100% | 100% |
| ChatGPT-4o-latest | 64.74% | 92.90% | 92.90% |
| Gemini 1.5 Pro | 80.94% | 100% | 100% |
| Claude 3.5 Sonnet | 98.66% | 100% | 100% |
Key Takeaways
- Gemini 1.5 Pro and Claude 3.5 Sonnet performed exceptionally well in preserving the document’s structure and accurately extracting complex characters, with Claude 3.5 Sonnet leading in overall accuracy.
- Nanonets OCR provided decent extraction results but struggled with the complexity of the document, particularly with retaining the overall structure of the document, resulting in lower Levenshtein Accuracy.
- ChatGPT-4o-latest showed slightly better performance in preserving the structural integrity of the document.
Conclusion: For medical documents with intricate formatting, Claude 3.5 Sonnet is the most reliable option for maintaining the original document’s structure. However, if structural preservation is less critical, Nanonets OCR and Google Gemini also offer strong alternatives with high text accuracy.
Handwritten Document
Objective: Assess the performance of various LLM APIs in accurately extracting text from a handwritten document, focusing on their ability to handle irregular handwriting, varying text sizes, and non-standardized formatting.
Metrics Used:
- ROUGE-1 Score: Evaluates how well individual words from the original text are captured in the extracted output.
- ROUGE-L Score: Checks how well the sequence of words and structure are preserved.
Documents Tested:
- Handwritten doc 1 A single-page document with inconsistent handwriting, varying text sizes, and non-standard formatting.
- Handwritten doc 2 A single-page document with inconsistent handwriting, varying text sizes, and non-standard formatting.

Results
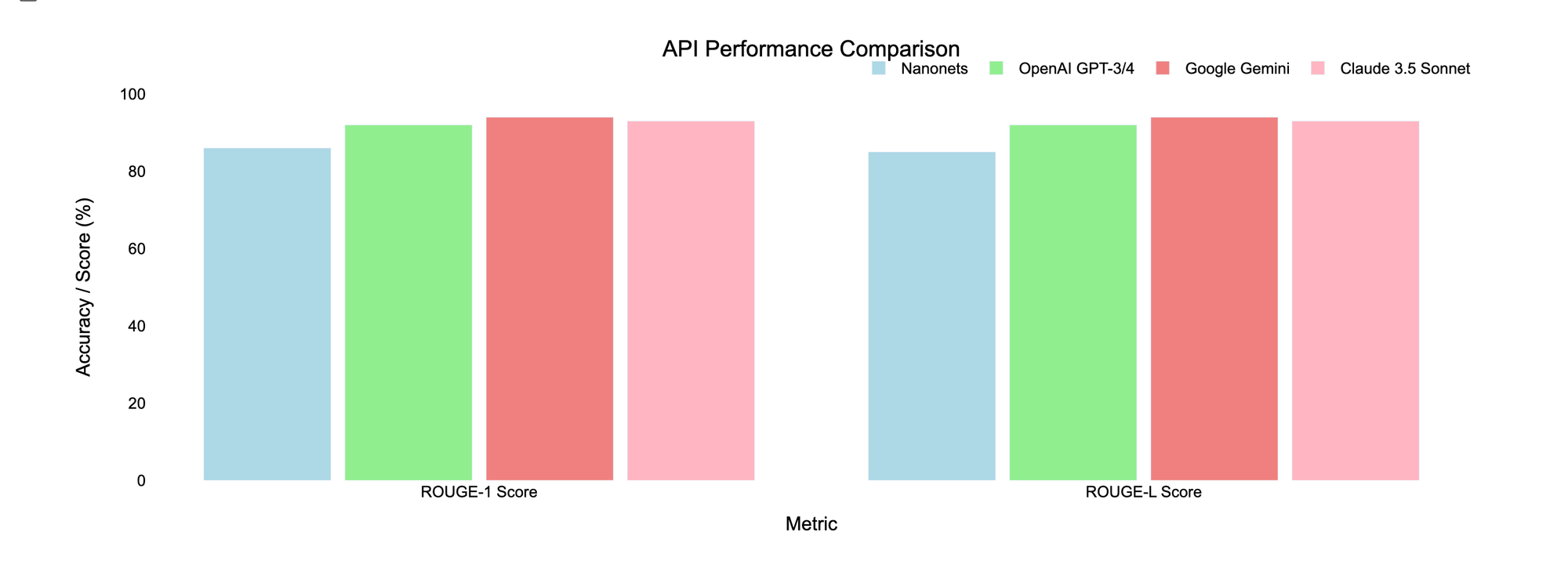
| API | ROUGE-1 Score | ROUGE-L Score |
|---|---|---|
| Nanonets OCR | 86% | 85% |
| ChatGPT-4o-latest | 92% | 92% |
| Gemini 1.5 Pro | 94% | 94% |
| Claude 3.5 Sonnet | 93% | 93% |
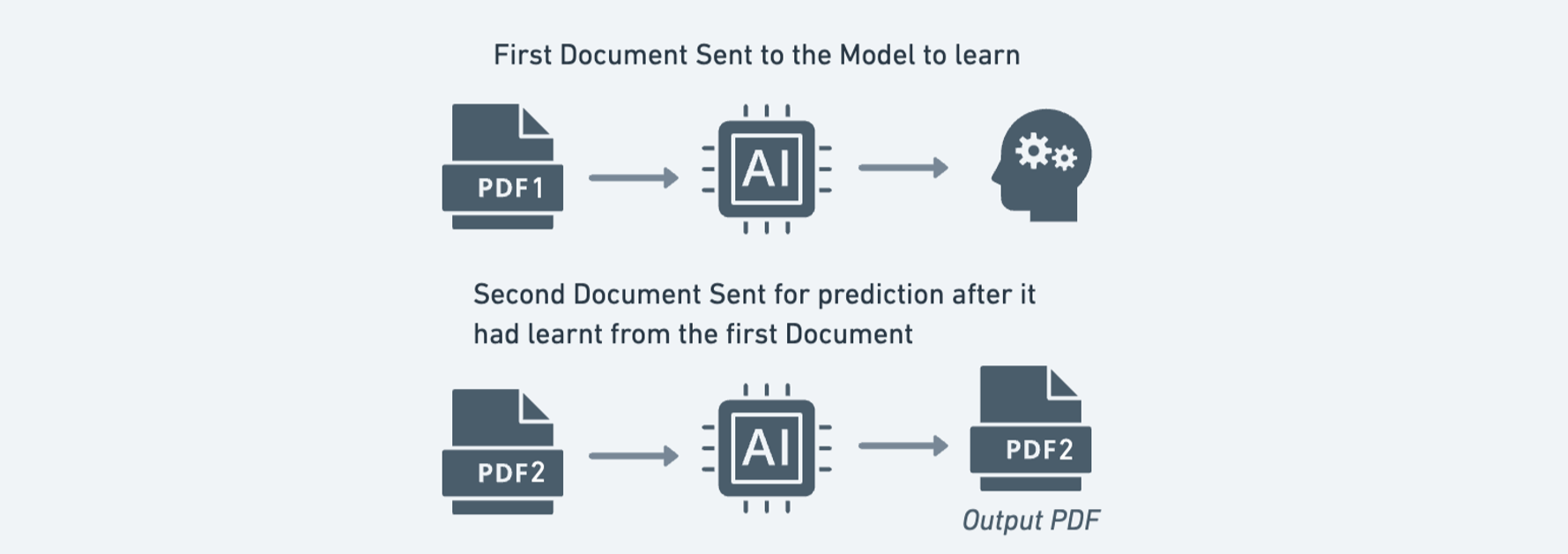
Impact of Training on Sonnet 3.5
To explore the potential for improvement, the second document was used to train Claude 3.5 Sonnet before extracting text from the first document. This resulted in a slight improvement, with both ROUGE-1 and ROUGE-L scores increases from 93% to 94%.
Key Takeaways
- ChatGPT-4o-latest Gemini 1.5 Pro and Claude 3.5 Sonnet performed exceptionally well, with only minimal differences between them. Claude 3.5 Sonnet, after additional training, slightly edged out Gemini 1.5 Pro in overall accuracy.
- Nanonets OCR struggled a little with irregular handwriting, but this is something that can be resolved with the no-code training that it offers, something we’ll cover some other time
Conclusion: For handwritten documents with irregular formatting, all the four options showed the best overall performance. Retraining your model can definitely help with improving accuracy here.
API Features and Pricing Analysis
When selecting a Large Language Model (LLM) API for data extraction, understanding rate limits, pricing, token lengths and additional features might be crucial as well. These factors significantly impact how efficiently and effectively you can process and extract data from large documents or images. For instance, if your data extraction task involves processing text that exceeds the token limit of an API, you may face challenges with truncation or incomplete data, or if your request frequency surpasses the rate limits, you could experience delays or throttling, which can hinder the timely processing of large volumes of data.
| Feature | OpenAI GPT-4 | Google Gemini 1.5 Pro | Anthropic Claude 3.5 Sonnet | Nanonets OCR |
|---|---|---|---|---|
| Token Limit (Free) | N/A (No free tier) | 32,000 | 8,192 | N/A (OCR specific) |
| Token Limit (Paid) | 32,768 (GPT-4 Turbo) | 4,000,000 | 200,000 | N/A (OCR-specific) |
| Rate Limits (Free) | N/A (No free tier) | 2 RPM | 5 RPM | 2 RPM |
| Rate Limits (Paid) | Varies by tier, up to 10,000 TPM* | 360 RPM | Varies by tier, goes up to 4000 RPM | Custom plans available |
| Document Types Supported | Image | images, videos | Images | Images and PDFs |
| Model Retraining | Not available | Not available | Not available | Available |
| Integrations with other Apps | Code-based API integration | Code-based API integration | Code-based API integration | Pre-built integrations with click-to-configure setup |
| Pricing Model | Pay-per-token, tiered plans | Pay as you Go | Pay-per-token, tiered plans | Pay as you Go, Custom pricing based on volume |
| Starting Price | $0.03/1K tokens (prompt), $0.06/1K tokens (completion) for GPT-4 | $3.5/1M tokens (input), $10.5/1M tokens (output) | $0.25/1M tokens (input), $1.25/1M tokens (output) | workflow based, $0.05/step run |
- TPM = Tokens Per Minute, RPM= Requests Per Minute
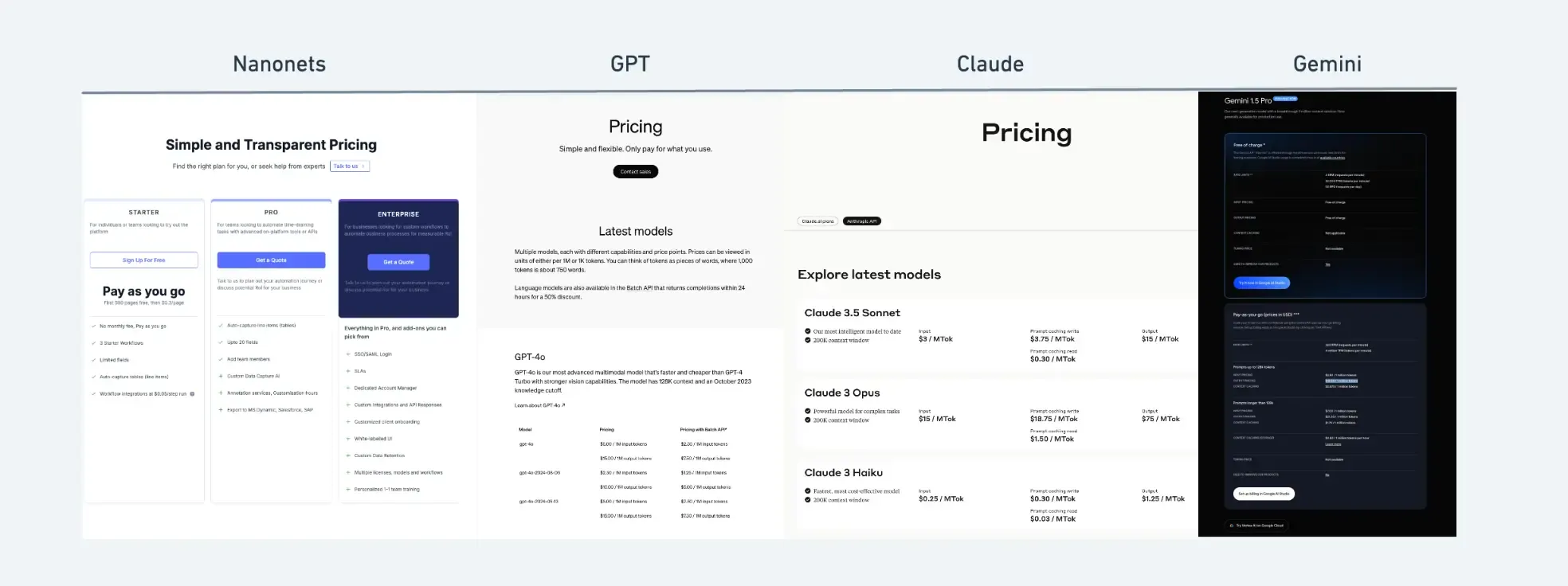
Links for detailed pricing
Other Literature on the Internet Analysis
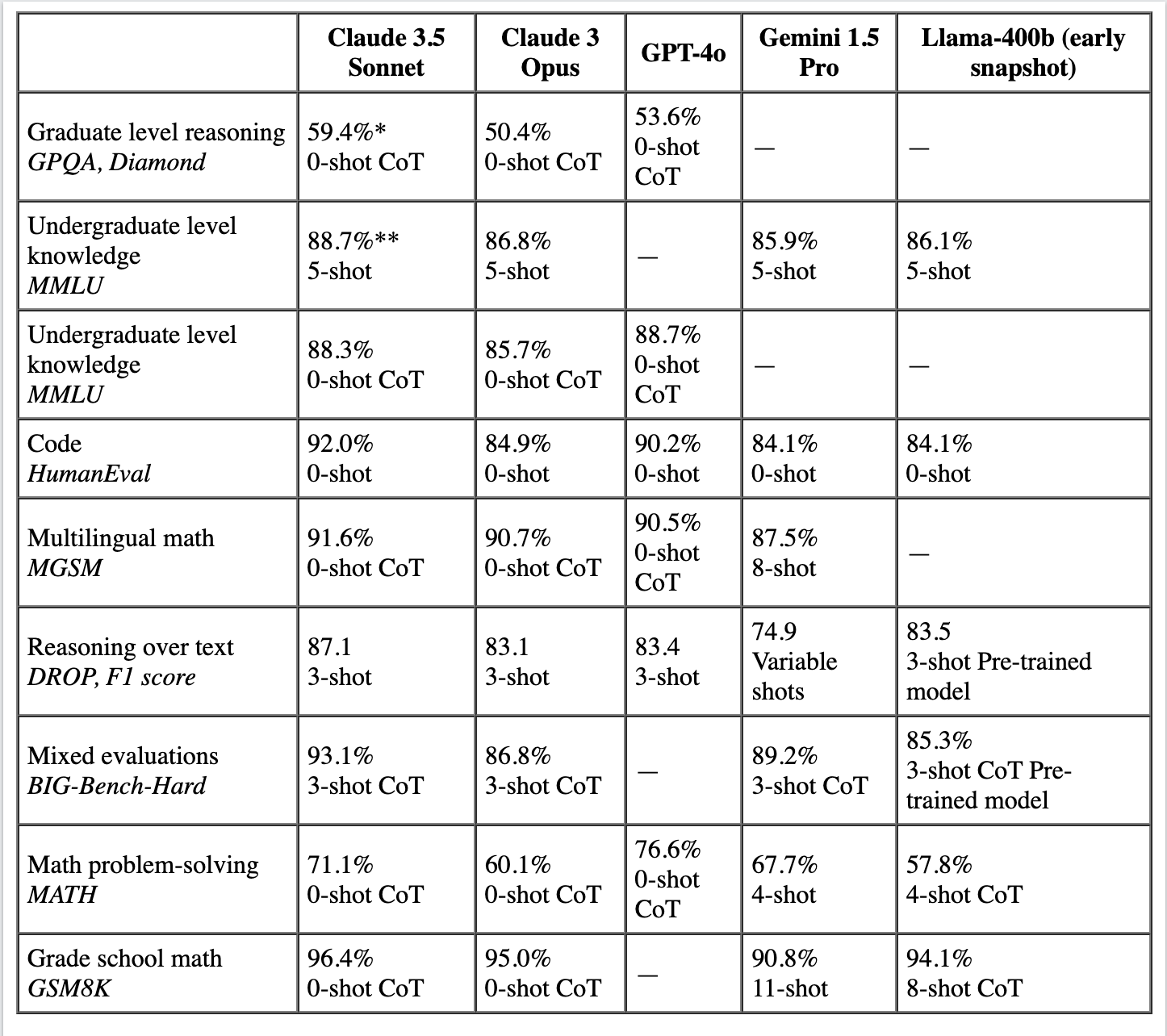
In addition to our hands-on testing, we’ve also considered analyses available from sources like Claude to provide a more comprehensive comparison of these leading LLMs. The table below presents a detailed comparative performance analysis of various AI models, including Claude 3.5 Sonnet, Claude 3 Opus, GPT-4o, Gemini 1.5 Pro, and an early snapshot of Llama-400b. This evaluation covers their abilities in tasks such as reasoning, knowledge retrieval, coding, and mathematical problem-solving. The models were tested under different conditions, like 0-shot, 3-shot, and 5-shot settings, which reflect the number of examples provided to the model before generating an output. These benchmarks offer insights into each model’s strengths and capabilities across various domains.
Key Takeaways
- For detailed pricing and options for each API, check out the links provided above. They’ll help you compare and find the best fit for your needs.
- Additionally, while LLMs typically don’t offer retraining, Nanonets provides these features for its OCR solutions. This means you can tailor the OCR to your specific requirements, potentially improving its accuracy.
- Nanonets also stands out with its pre-built integrations that make it easy to connect with other apps, simplifying the setup process compared to the code-based integrations offered by other services.
Conclusion
Selecting the right LLM API for data extraction is essential, especially for diverse document types like invoices, medical records, and handwritten notes. Each API has unique strengths and limitations based on your specific needs.
- Nanonets OCR excels in extracting structured data from financial documents with high precision, especially for key-value pairs and tables.
- ChatGPT-4 offers balanced performance across various document types but may need prompt fine-tuning for complex cases.
- Gemini 1.5 Pro and Claude 3.5 Sonnet are strong in handling complex text, with Claude 3.5 Sonnet particularly effective in maintaining document structure and accuracy.
For sensitive or complex documents, consider each API’s ability to preserve the original structure and handle various formats. Nanonets is ideal for financial documents, while Claude 3.5 Sonnet is best for documents requiring high structural accuracy.
In summary, choosing the right API depends on understanding each option’s strengths and how they align with your project’s needs.
| Feature | Nanonets | OpenAI GPT-3/4 | Google Gemini | Anthropic Claude |
|---|---|---|---|---|
| Speed (Experiment) | Fastest | Fast | Slow | Fast |
| Strengths (Experiment) | High precision in key-value pair extraction and structured outputs | Versatile across various document types, fast processing | Excellent in handwritten text accuracy, handles complex formats well | Top performer in retaining document structure and complex text accuracy |
| Weaknesses (Experiment) | Struggles with handwritten OCR | Needs fine-tuning for high accuracy in complex cases | Occasional errors in structured data extraction, slower speed | Content filtering issues, especially with copyrighted content |
| Documents suitable for | Financial Documents | Dense Text Documents | Medical Documents, Handwritten Documents | Medical Documents, Handwritten Documents |
| Retraining Capabilities | No-code custom model retraining available | Fine tuning available | Fine tuning available | Fine tuning available |
| Pricing Models | 3 (Pay-as-you-go, Pro, Enterprise) | 1 (Usage-based, per-token pricing) | 1 (Usage-based, per-token pricing) | 1 (Usage-based, per-token pricing) |
| Integration Capabilities | Easy integration with ERP systems and custom workflows | Integrates well with various platforms, APIs | Seamless integration with Google Cloud services | Strong integration with enterprise systems |
| Ease of Setup | Quick setup with an intuitive interface | Requires API knowledge for setup | Easy setup with Google Cloud integration | User-friendly setup with comprehensive guides |

