Vision-language models (VLMs) have gained significant attention due to their ability to handle various multimodal tasks. However, the rapid proliferation of benchmarks for evaluating these models has created a complex and fragmented landscape. This situation poses several challenges for researchers. Implementing protocols for numerous benchmarks is time-consuming, and interpreting results across multiple evaluation metrics becomes difficult. The computational resources required to run all available benchmarks are substantial, leading many researchers to evaluate new models on only a subset of benchmarks. This selective approach creates blind spots in understanding model performance and complicates comparisons between different VLMs. A standardized evaluation framework is needed to draw meaningful conclusions about the most effective strategies for advancing VLM technology. Ultimately, the field needs a more streamlined and comprehensive approach to benchmark these models.
Researchers from Meta FAIR, Univ Gustave Eiffel, CNRS, LIGM, and Brown University introduced a comprehensive framework UniBench, designed to address the challenges in evaluating VLMs. This unified platform implements 53 diverse benchmarks in a user-friendly codebase, covering a wide range of capabilities from object recognition to spatial understanding, counting, and domain-specific medical and satellite imagery applications. UniBench categorizes these benchmarks into seven types and seventeen finer-grained capabilities, allowing researchers to quickly identify model strengths and weaknesses in a standardized manner.
The utility of UniBench is demonstrated through the evaluation of nearly 60 openly available VLMs, encompassing various architectures, model sizes, training dataset scales, and learning objectives. This systematic comparison across different axes of progress reveals that while scaling the model size and training data significantly improves performance in many areas, it offers limited benefits for visual relations and reasoning tasks. UniBench also uncovers persistent struggles in numerical comprehension tasks, even for state-of-the-art VLMs.
To facilitate practical use, UniBench provides a distilled set of representative benchmarks that can be run quickly on standard hardware. This comprehensive yet efficient approach aims to streamline VLM evaluation, enabling more meaningful comparisons and insights into effective strategies for advancing VLM research.

UniBench demonstrates its utility through a comprehensive evaluation of 59 openly available VLMs, covering a wide range of architectures, sizes, and training approaches. The framework assesses these models across 53 diverse benchmarks, categorized into seven types and seventeen capabilities. This systematic evaluation reveals several key insights into VLM performance and areas for improvement.
Results show that scaling model size and training data significantly enhances performance in many areas, particularly in object recognition and scene understanding. However, this scaling approach offers limited benefits for visual relations and reasoning tasks. Also, even state-of-the-art VLMs struggle with seemingly simple benchmarks involving numerical comprehension, such as character recognition or counting, including on well-established datasets like MNIST and SVHN.
The evaluation highlights that large open models, such as Eva ViT-E/14, perform well as general-purpose VLMs. In contrast, specialized models like NegCLIP excel in specific tasks, particularly visual relations. UniBench’s comprehensive approach allows for a nuanced understanding of model strengths and weaknesses, providing valuable insights for both researchers and practitioners in selecting appropriate models for specific applications or identifying areas for future improvement in VLM development.

UniBench’s comprehensive evaluation of 59 VLMs across 53 diverse benchmarks reveals several key insights:
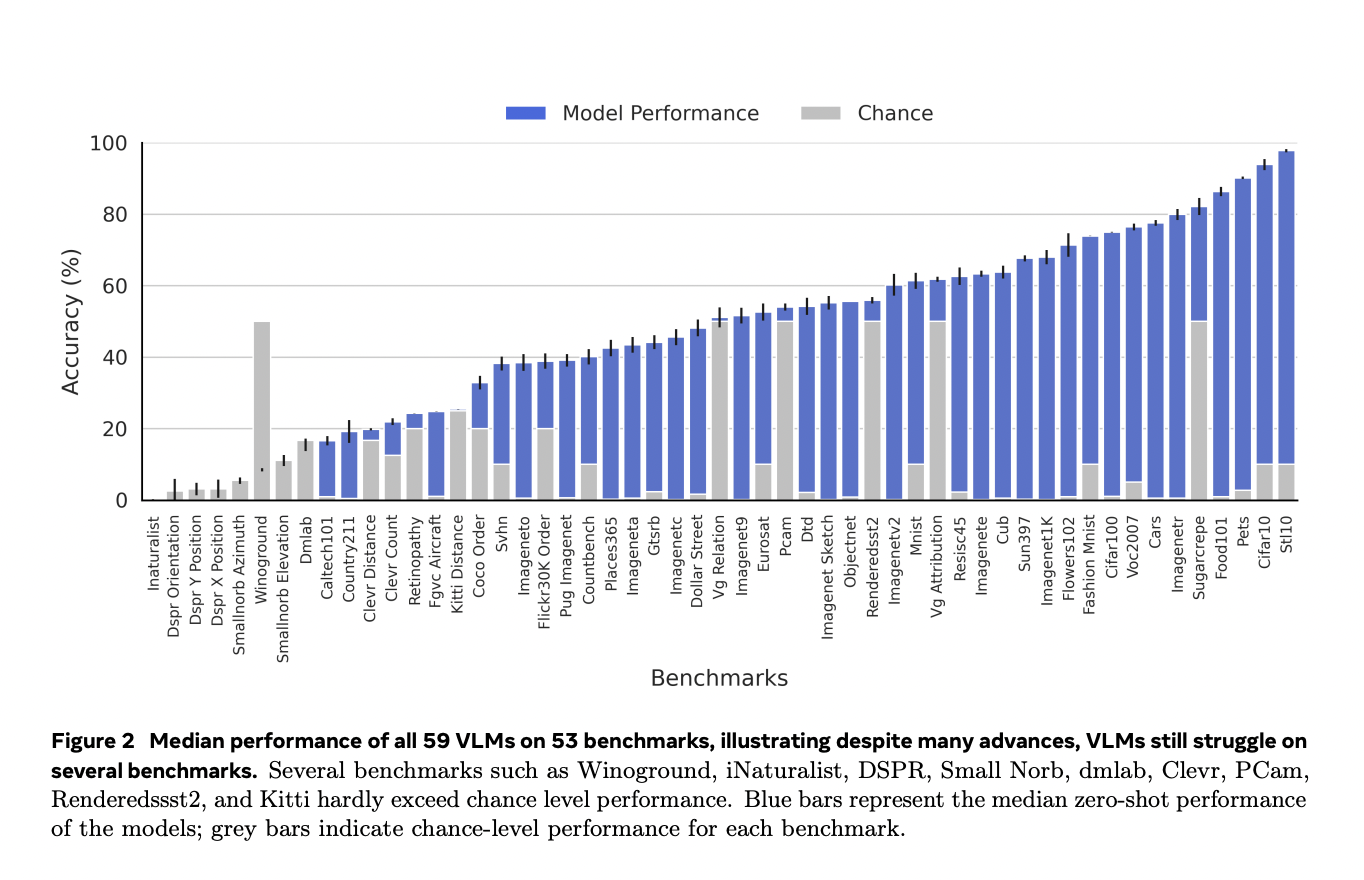
1. Performance varies widely across tasks. While VLMs excel in many areas, they struggle with certain benchmarks, performing near or below random chance level on tasks like Winoground, iNaturalist, DSPR, Small Norb, dmlab, Clevr, PCam, Renderedssst2, and Kitti.
2. Scaling limitations: Increasing model size and training dataset size significantly improves performance in many areas, particularly object recognition and robustness. However, this scaling approach offers minimal benefits for visual relations and reasoning tasks.
3. Surprising weaknesses: VLMs perform poorly on traditionally simple tasks like MNIST digit recognition. Even with top-5 accuracy, VLMs barely reach 90% on MNIST, while a basic 2-layer MLP achieves 99% accuracy.
4. Counting and numerical tasks: VLMs consistently struggle with number comprehension across multiple benchmarks, including SVHN, CountBench, and ClevrCount.
5. Data quality over quantity: Models trained on 2 billion high-quality samples outperform those trained on larger datasets, emphasizing the importance of data curation.
6. Tailored objectives: Models like NegCLIP, with specialized learning objectives, significantly outperform larger models on relational understanding tasks.
7. Model recommendations: For general-purpose use, large ViT encoders like Eva-2 ViT-E/14 show the best overall performance. For specific tasks like relations or counting, specialized models like NegCLIP are recommended.
UniBench addresses the challenge of comprehensive VLM evaluation by distilling its 53 benchmarks into a representative subset of seven, balancing thoroughness with efficiency. This approach overcomes the computational demands of a full evaluation, which requires processing 6 million images over 2+ hours on an A100 GPU. While ImageNet correlates with many benchmarks, it poorly represents 18 others, highlighting the need for diverse metrics. UniBench’s streamlined set, selected to represent key axes of progress, runs in just 5 minutes on a single A100 GPU for a ViT-B/32 model. This efficient pipeline offers a practical solution for swift yet comprehensive VLM assessment, enabling researchers and practitioners to gain meaningful insights quickly.
This study introduces UniBench, a comprehensive evaluation framework for vision-language models that addresses the challenges of fragmented benchmarking in the field. It implements 53 diverse benchmarks, categorized into seven types and seventeen capabilities, allowing for systematic assessment of 59 VLMs. Key findings reveal that while scaling model size and training data improves performance in many areas, it offers limited benefits for visual relations and reasoning tasks. Surprisingly, VLMs struggle with simple numerical tasks like MNIST digit recognition. UniBench also highlights the importance of data quality over quantity and the effectiveness of tailored learning objectives. To balance thoroughness with efficiency, UniBench offers a distilled set of seven representative benchmarks, runnable in just 5 minutes on a single GPU.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.