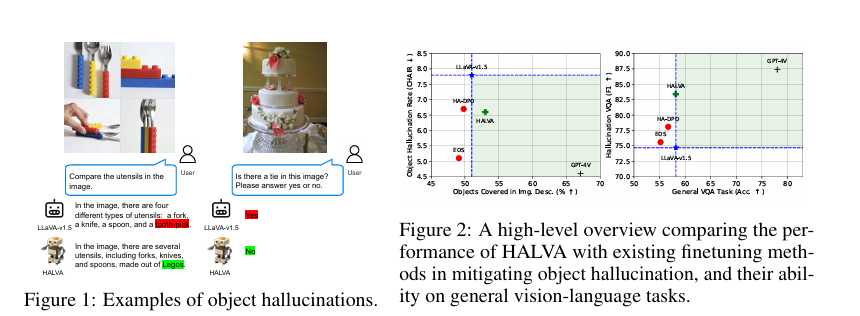
A new research addresses a critical issue in Multimodal Large Language Models (MLLMs): the phenomenon of object hallucination. Object hallucination occurs when these models generate descriptions of objects not present in the input data, leading to inaccuracies undermining their reliability and effectiveness. For instance, a model might incorrectly assert the presence of a “tie” in an image of a “wedding cake” or misidentify objects in a scene due to learned associations rather than actual observations. This problem is particularly pressing as MLLMs are increasingly deployed in applications requiring high accuracy, such as visual question answering and image captioning. The authors highlight that existing methods to mitigate hallucinations often come with significant trade-offs, including increased inference time, the need for extensive retraining, and potential degradation of the model’s overall performance on general tasks.
To tackle this problem, this paper from Queen’s University, Vector Institute, Google Cloud AI Research, and Google DeepMind propose a novel method called Data-Augmented Contrastive Tuning (DACT). This approach builds on the foundation of existing MLLM frameworks but introduces a more efficient mechanism for reducing hallucination rates without compromising the model’s general capabilities.MLLMs trained with this framework are called Hallucination Attenuated Language and Vision Assistant (HALVA). Current methods for addressing object hallucination can be categorized into inference-based, pretraining, and finetuning techniques. Inference-based methods often slow the model’s response time, while pre-training techniques require vast amounts of data and are not easily applicable to off-the-shelf models. While effective, finetuning methods can diminish the model’s performance in other vision-language tasks. DACT, however, employs a two-pronged strategy: it generates hallucinated responses through data augmentation and applies a contrastive tuning objective to reduce the likelihood of these hallucinations during language generation. This method allows minimal retraining and maintains the model’s performance across various tasks.
The proposed DACT method consists of two main components: generative data augmentation and contrastive tuning. In the first step, the authors create hallucinated responses by selectively altering the correct responses based on the input data. This involves replacing certain objects with co-occurring but incorrect ones in the proper response, generating a set of contrastive pairs. For example, if the correct response describes a scene with a “fork,” the augmented response might include a “spoon” or “knife” that does not appear in the input image. The second component, contrastive tuning, focuses on minimizing the likelihood of generating these hallucinated tokens relative to the correct tokens. This is achieved through a contrastive objective that encourages the model to favor accurate descriptions while maintaining a KL-divergence constraint to ensure that the model does not diverge significantly from its original performance.
Results indicate that HALVA significantly reduces hallucination rates while maintaining or even enhancing the model’s performance on general tasks. For instance, on the AMBER benchmark, HALVA variants demonstrate a marked decrease in hallucination rates compared to existing fine-tuning methods, such as HA-DPO and EOS. Specifically, the HALVA-7B and HALVA-13B models show substantial reductions in object hallucination rates, improving both instance-level and sentence-level evaluations.
In visual question-answering tasks, HALVA also outperforms the base model and other fine-tuning methods, achieving higher F1 scores and demonstrating its effectiveness in mitigating hallucinations while preserving overall accuracy. The authors also highlight that HALVA’s benefits extend beyond object hallucination, improving performance on other vision-language hallucinations as evaluated by the HallusionBench benchmark.
In conclusion, the research presents a compelling solution to the problem of object hallucination in MLLMs through the introduction of Data-Augmented Contrastive Tuning. By effectively mitigating hallucination rates while preserving the model’s overall performance, this method addresses a significant challenge in the deployment of multimodal models. The combination of generative data augmentation and contrastive tuning offers a promising avenue for enhancing the reliability of MLLMs, paving the way for their broader application in tasks requiring accurate visual understanding and language generation. The potential impact of the DACT method is significant, offering a promising future for the field of artificial intelligence and machine learning.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Shreya Maji is a consulting intern at MarktechPost. She is pursued her B.Tech at the Indian Institute of Technology (IIT), Bhubaneswar. An AI enthusiast, she enjoys staying updated on the latest advancements. Shreya is particularly interested in the real-life applications of cutting-edge technology, especially in the field of data science.