

Inception of LLMs – NLP and Neural Networks
The creation of Large Language Models didn’t happen overnight. Remarkably, the first concept of language models started with rule-based systems dubbed Natural Language Processing. These systems follow predefined rules that make decisions and infer conclusions based on text input. These systems rely on if-else statements processing keyword information and generating predetermined outputs. Think of a decision tree where output is a predetermined response if the input contains X, Y, Z, or none. For example: If the input includes keywords “mother,” output “How is your mother?” Else, output, “Can you elaborate on that?”
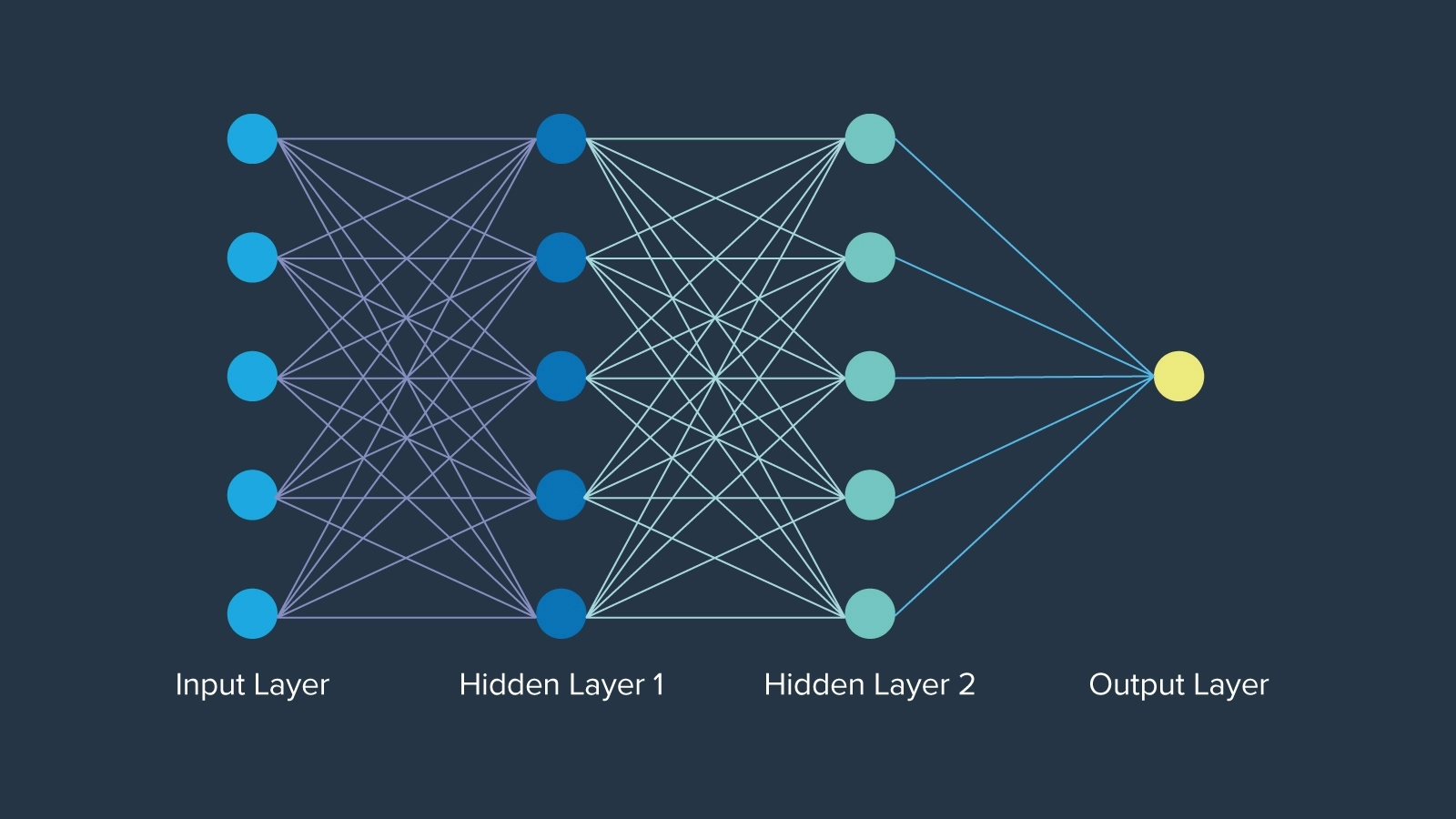
The biggest early advancement was neural networks, which were considered when first introduced in 1943 inspired by neurons in human brain function, by mathematician Warren McCulloch. Neural networks even pre-date the term “artificial intelligence” by roughly 12 years. The network of neurons in each layer is organized in a specific manner, where each node holds a weight that determines its importance in the network. Ultimately, neural networks opened closed doors creating the foundation on which AI will forever be built.
Evolution of LLMs – Embeddings, LSTM, Attention & Transformers
Computers can’t comprehend the meanings of words working together in a sentence the same way humans can. To improve computer comprehension for semantic analysis, a word embedding technique must first be applied which allows models to capture the relationships between neighboring words leading to improved performance in various NLP tasks. However, there needs to be a method to store word embedding in memory.
Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) were great leaps within neural networks, with the capability of handling sequential data more effectively than traditional neural networks. While LSTMs are no longer used, these models paved the way for more complex language understanding and generation tasks that eventually led to the transformer model.
The Modern LLM – Attention, Transformers, and LLM Variants
The introduction of the attention mechanism was a game-changer, enabling models to focus on different parts of an input sequence when making predictions. Transformer models, introduced with the seminal paper “Attention is All You Need” in 2017, leveraged the attention mechanism to process entire sequences simultaneously, vastly improving both efficiency and performance. The eight Google Scientists didn’t realize the ripples their paper would make in creating present-day AI.
Following the paper, Google’s BERT (2018) was developed and touted as the baseline for all NLP tasks, serving as an open-source model used in numerous projects that allowed the AI community to build projects and grow. Its knack for contextual understanding, pre-trained nature and option for fine-tuning, and demonstration of transformer models set the stage for larger models.
Alongside BERT, OpenAI released GPT-1 the first iteration of their transformer model. GPT-1 (2018), started with 117 million parameters, followed by GPT-2 (2019) with a massive leap to 1.5 billion parameters, with progression continuing with GPT-3 (2020), boasting 175 billion parameters. OpenAI’s groundbreaking chatbot ChatGPT, based on GPT-3, was released two years later on Nov. 30, 2022, marking a significant craze and truly democratizing access to powerful AI models. Learn about the difference between BERT and GPT-3.
What Technological Advancements are Driving the Future of LLMs?
Advances in hardware, improvements in algorithms and methodologies, and integration of multi-modality all contribute to the advancement of large language models. As the industry finds new ways to utilize LLMs effectively, the continued advancement will tailor itself to each application and eventually entirely change the landscape of computing.
Advances in Hardware
The most simple and direct method for improving LLMs is to improve the actual hardware that the model runs on. The development of specialized hardware like Graphics Processing Units (GPUs) significantly accelerated the training and inference of large language models. GPUs, with their parallel processing capabilities, have become essential for handling the vast amounts of data and complex computations required by LLMs.
OpenAI uses NVIDIA GPUs to power its GPT models and was one of the first NVIDIA DGX customers. Their relationship spanned from the emergence of AI to the continuance of AI where the CEO hand-delivered the first NVIDIA DGX-1 but also the latest NVIDIA DGX H200. These GPUs incorporate huge amounts of memory and parallel computing for training, deploying, and inference performance.
Improvements in Algorithms and Architectures
The transformer architecture is known for already assisting LLMs. The introduction of that architecture has been pivotal to the advancement of LLMs as they are now. Its ability to process entire sequences simultaneously rather than sequentially has dramatically improved model efficiency and performance.
Having said that, more can still be expected of the transformer architecture, and how it can continue evolving Large Language Models.
- Continuous refinements to the transformer model, including better attention mechanisms and optimization techniques, will lead to more accurate and faster models.
- Research into novel architectures, such as sparse transformers and efficient attention mechanisms, aims to reduce computational requirements while maintaining or enhancing performance.
Integration of Multimodal Inputs
The future of LLMs lies in their ability to handle multimodal inputs, integrating text, images, audio, and potentially other data forms to create richer and more contextually aware models. Multimodal models like OpenAI’s CLIP and DALL-E have demonstrated the potential of combining visual and textual information, enabling applications in image generation, captioning, and more.
These integrations allow LLMs to perform even more complex tasks, such as comprehending context from both text and visual cues, which ultimately makes them more versatile and powerful.
Future of LLMs
The advancements haven’t stopped, and there are more coming as LLM creators plan to incorporate even more innovative techniques and systems in their work. Not every improvement in LLMs requires more demanding computation or deeper conceptual understanding. One key enhancement is developing smaller, more user-friendly models.
While these models may not match the effectiveness of “Mammoth LLMs” like GPT-4 and LLaMA 3, it’s important to remember that not all tasks require massive and complex computations. Despite their size, advanced smaller models like Mixtral 8x7B and Mistal 7B can still deliver impressive performances. Here are some key areas and technologies expected to drive the development and improvement of LLMs:
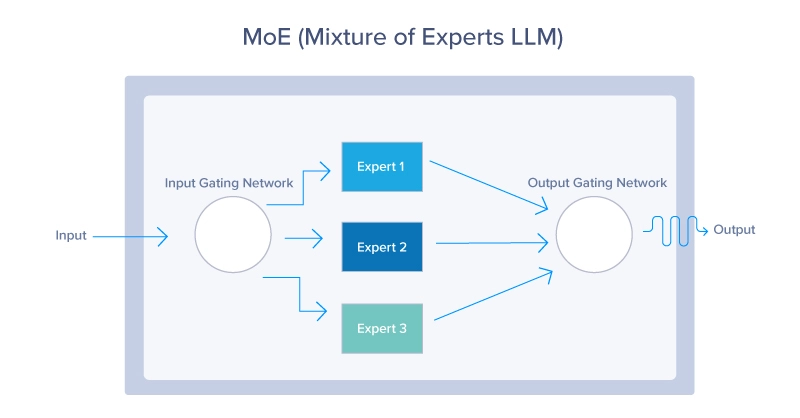
1. Mixture of Experts (MoE)
MoE models use a dynamic routing mechanism to activate only a subset of the model’s parameters for each input. This approach allows the model to scale efficiently, activating the most relevant “experts” based on the input context, as seen below. MoE models offer a way to scale up LLMs without a proportional increase in computational cost. By leveraging only a small portion of the entire model at any given time, these models can use less resources while still providing excellent performance.
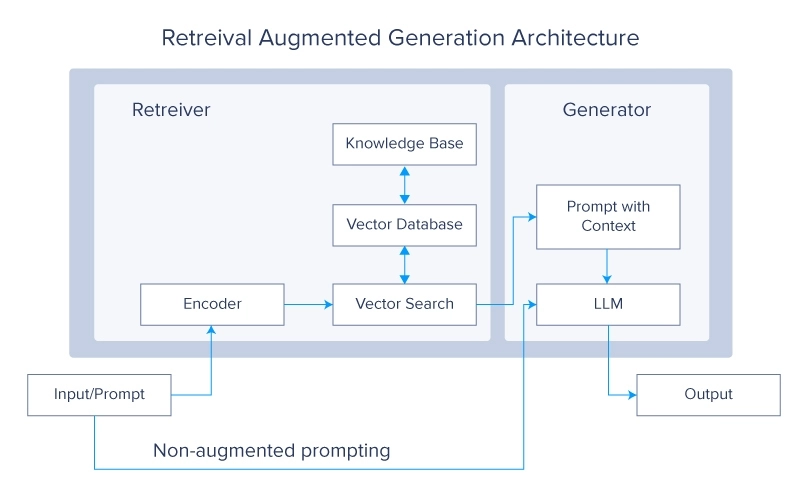
2. Retrieval-Augmented Generation (RAG) Systems
Retrieval Augmented Generation systems are currently a very hot topic in the LLM community. The concept questions why you should train the LLMs on more data when you can simply make it retrieve the desired data from an external source. Then that data is used to generate a final answer.
RAG systems enhance LLMs by retrieving relevant information from large external databases during the generation process. This integration allows the model to access and incorporate up-to-date and domain-specific knowledge, improving its accuracy and relevance. Combining the generative capabilities of LLMs with the precision of retrieval systems results in a powerful hybrid model that can generate high-quality responses while staying informed by external data sources.
3. Meta-Learning
Meta-learning approaches allow LLMs to learn how to learn, enabling them to adapt quickly to new tasks and domains with minimal training.
The concept of Meta-learning depends on several key concepts such as:
- Few-Shot Learning: by which LLMs are trained to understand and perform new tasks with only a few examples, significantly reducing the amount of data required for effective learning. This makes them highly versatile and efficient in handling diverse scenarios.
- Self-Supervised Learning: LLMs use large amounts of unlabelled data to generate labels and learn representations. This form of learning allows models to create a rich understanding of language structure and semantics which is then fine-tuned for specific applications.
- Reinforcement Learning: In this approach, LLMs learn by interacting with their environment and receiving feedback in the form of rewards or penalties. This helps models to optimize their actions and improve decision-making processes over time.
Conclusion
LLMs are marvels of modern technology. They’re complex in their functioning, massive in size, and groundbreaking in their advancements. In this article, we explored the future potential of these extraordinary advancements. Starting from their early beginnings in the world of artificial intelligence, we also delved into key innovations like Neural Networks and Attention Mechanisms.
We then examined a multitude of strategies for enhancing these models, including advancements in hardware, refinements in their internal mechanisms, and the development of new architectures. By now, we hope you have gained a clearer and more comprehensive understanding of LLMs and their promising trajectory in the near future.
Kevin Vu manages Exxact Corp blog and works with many of its talented authors who write about different aspects of Deep Learning.
