Learning in simulation and applying the learned policy to the real world is a potential approach to enable generalist robots, and solve complex decision-making tasks. However, the challenge to this approach is to address simulation-to-reality (sim-to-real) gaps. Also, a huge amount of data is needed while learning to solve these tasks, and the load of collecting data in real-time with physical robots increases due to giving unlimited training supervision via state-of-the-art simulation. So, it becomes important to smoothly transfer and deploy robot control policies into real-world hardware using reinforcement learning (RL).
Robot Learning through Sim-to-Real Transfer Physics-based simulations are used as a driving force to develop robotic skills in manipulations like tabletop and mobile even though the gaps are not fully bridged. A current approach, sim-to-real gaps, include system identification, domain randomization, real-world adaptation, and simulator augmentation. A successful sim-to-real transfer contains locomotion, non-prehensile manipulation, etc, and helps in this performance variation. Another method, Human-in-The-Loop Robot Learning, is a common framework that feeds human knowledge into autonomous systems. Various human feedbacks are used in this method to solve sequential decision-making tasks.
Researchers from Stanford University proposed TRANSIC, a data-driven method to enable successful sim-to-real transfer of policies using a human-in-the-loop framework. It allows humans to enhance simulation policies to address multiple unmodeled sim-to-real gaps with the help of intervention and online correction. Human corrections help in learning residual policies and integrated with simulation policies for self-execution. Also, sim-to-real transfer in difficult manipulation tasks is achieved successfully using TRANSIC, and this method shows good properties like scaling with human effort.
To close each gap in sim-to-real gaps using the ability of TRANSIC, 5 different simulation-reality pairs are created, and large gaps for each pair are intentionally created between the simulation and the real world. TRANSIC achieves an average success rate of 77% for all 5 pairs with the sim-to-real gaps and outperforms the best baseline method, IWR, which can achieve an average success rate of only 18%. Some of the capabilities of TRANSIC include learning reusable skills for category-level object generalization, operating in a completely autonomous setting once the learning of the gating mechanism is done, addressing partial point cloud observations and correction data, and learning constant visual features between simulation and reality.
Researchers proved that TRANSIC outperforms the best baseline, IWR in human data scalability. When the size of the correction data increases from 25% to 75%, the proposed method achieves a relative improvement of 42% in the average success rate, outperforming IWR, which achieves only a 23% relative improvement. Moreover, the performance of IWR becomes constant at an early stage and starts decreasing when more human data are available. IWR fails to model the behavioral modes of humans and trained robots, but TRANSIC overcomes these challenges by learning gated residual policies from human correction.
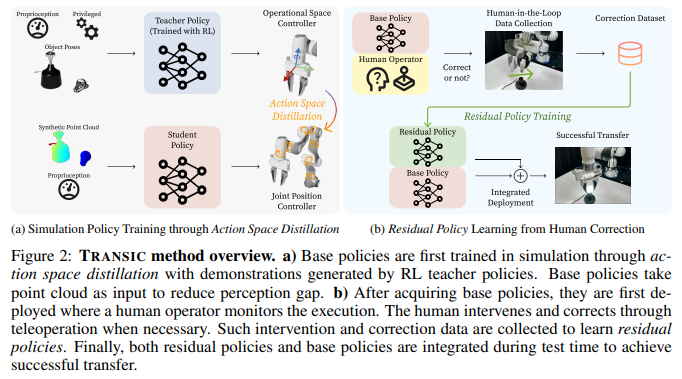
In conclusion, researchers from Stanford University introduced TRANSIC, a human-in-the-loop method to handle sim-to-real transfer of policies for manipulation tasks. To achieve success, a good base policy learned from simulation is integrated with limited real-world data. The proposed method solves the issue of efficiently using human correction data to address the sim-to-real gap. However, some of the limitations to this method are: (a) Current tasks are bound only to the tabletop scenario with a soft parallel-jaw gripper. (b) A human operator is needed during the correction data collection phase. (c) It is challenging to learn by itself, so TRANSIC needs simulation policies with reasonable performances.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.