Vision-language models (VLMs), capable of processing both images and text, have gained immense popularity due to their versatility in solving a wide range of tasks, from information retrieval in scanned documents to code generation from screenshots. However, the development of these powerful models has been hindered by a lack of understanding regarding the critical design choices that truly impact their performance. This knowledge gap makes it challenging for researchers to make meaningful progress in this field. To address this issue, a team of researchers from Hugging Face and Sorbonne Université conducted extensive experiments to unravel the factors that matter the most when building vision-language models, focusing on model architecture, multimodal training procedures, and their impact on performance and efficiency.
Current state-of-the-art VLMs typically leverage pre-trained unimodal models, such as large language models and image encoders, and combine them through various architectural choices. However, the researchers observed that these design decisions are often made without proper justification, leading to confusion about their impact on performance. To shed light on this matter, they compared different model architectures, including cross-attention and fully autoregressive architectures, as well as the impact of freezing or unfreezing pre-trained backbones during training.
The researchers also delved into the multimodal training procedure, exploring strategies like learned pooling to reduce the number of visual tokens, preserving the original aspect ratio and image resolution, and image splitting to trade compute for performance. By rigorously evaluating these design choices in a controlled environment, they aimed to extract experimental findings that could guide the development of more efficient and effective VLMs. Motivated by these findings, the researchers trained Idefics2, an open-source 8B parameter foundational vision-language model, aiming to achieve state-of-the-art performance while maintaining computational efficiency.
One of the key aspects explored by the researchers was the choice of pre-trained backbones for the vision and language components. They found that for a fixed number of parameters, the quality of the language model backbone had a more significant impact on the final VLM’s performance than the quality of the vision backbone. Specifically, replacing a lower-quality language model (e.g., LLaMA-1-7B) with a better one (e.g., Mistral-7B) yielded a more substantial performance boost compared to upgrading the vision encoder (e.g., from CLIP-ViT-H to SigLIP-SO400M).
The researchers then compared the cross-attention and fully autoregressive architectures, two prevalent choices in VLM design. While the cross-attention architecture initially performed better when pre-trained backbones were frozen, the fully autoregressive architecture outperformed it when the pre-trained backbones were allowed to adapt during training. Interestingly, unfreezing the pre-trained backbones under the fully autoregressive architecture could lead to training divergences, which they mitigated by leveraging Low-Rank Adaptation (LoRA) to stabilize the training process.
To improve efficiency, the researchers explored the use of learned pooling to reduce the number of visual tokens required for each image. This strategy improved performance on downstream tasks and significantly reduced the computational cost during training and inference. Furthermore, they adapted a vision encoder pre-trained on fixed-size square images to preserve the original aspect ratio and resolution of input images, enabling flexible computation during training and inference without degrading performance.
To put these findings into practice, the researchers trained Idefics2, an open-source 8B parameter foundational vision-language model. Idefics2 was trained using a multi-stage pre-training approach, starting from pre-trained SigLIP-SO400M and Mistral-7B models. It was trained on diverse data sources, including interleaved image-text documents from OBELICS, image-text pairs from PMD and LAION COCO, and PDF documents from OCR-IDL, PDFA, and Rendered Text. This diverse training data aimed to enhance Idefics2’s capabilities in understanding and processing various multimodal inputs while leveraging the researchers’ insights into efficient and effective VLM design.
The researchers evaluated the performance of their proposed methods and design choices using various benchmark datasets, including VQAv2, TextVQA, OKVQA, and COCO. The general findings showed that splitting images into sub-images during training allowed for trading compute efficiency for improved performance during inference, particularly in tasks involving reading text in an image.
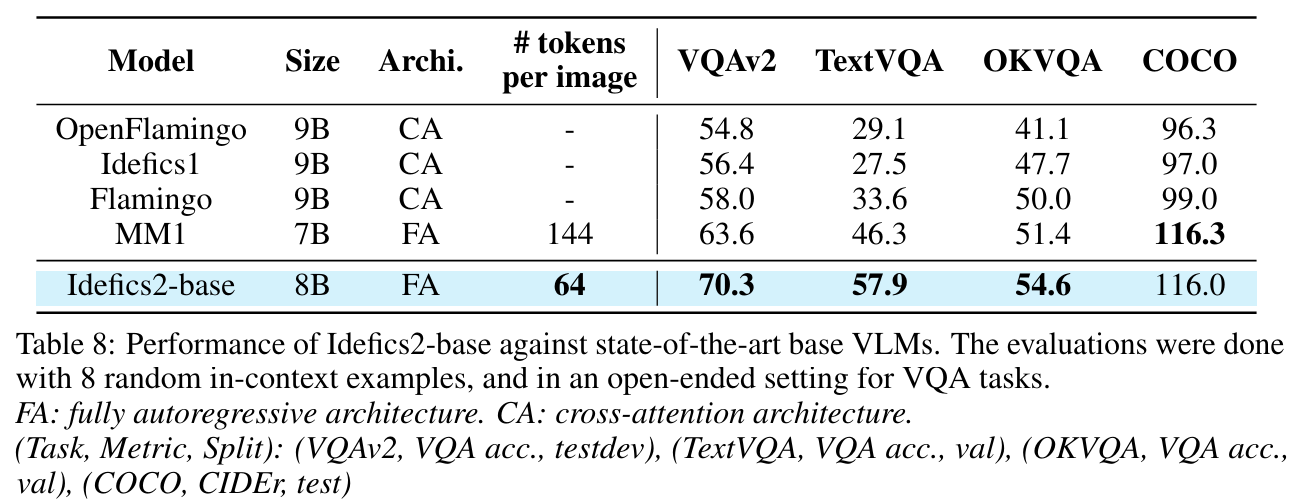
Quantitative results showed that their approach outperformed current state-of-the-art VLMs in the same size category, achieving impressive performance on benchmarks like MMMU, MathVista, TextVQA, and MMBench. Notably, Idefics2 exhibited performance on par with models four times larger and even matched the performance of closed-source models like Gemini 1.5 Pro on several benchmarks. For instance, on the MathVista benchmark, Idefics2 scored 54.9%, matching Gemini 1.5 Pro’s performance. On the challenging TextVQA benchmark, which tests OCR abilities, Idefics2 scored 73.6%, outperforming larger models like LLaVA-Next (68.9%) and DeepSeek-VL (71.5%).
These results showcase Idefics2’s state-of-the-art performance while being computationally efficient during inference, demonstrating the effectiveness of the researchers’ approach in building powerful and efficient VLMs through informed design choices.
While the researchers have made significant strides in understanding the critical factors in VLM development, there are likely further opportunities for improvement and exploration. As the field continues to evolve, their work serves as a solid foundation for future research and advancements in vision-language modeling. The researchers have also released their training dataset, The Cauldron, a massive collection of 50 vision-language datasets. By open-sourcing their work, including the model, findings, and training data, they aim to contribute to the field’s advancement and enable others to build upon their research, fostering collaboration in vision-language modeling.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.