Video understanding is one of the evolving areas of research in artificial intelligence (AI), focusing on enabling machines to comprehend and analyze visual content. Tasks like recognizing objects, understanding human actions, and interpreting events within a video come under this domain. Advancements in this domain find crucial applications in autonomous driving, surveillance, and entertainment industries. Enhancing the ability of AI to process and understand videos, researchers aim to improve the performance and reliability of various technologies that rely on visual data.
The main challenge in video understanding lies in the complexity of interpreting dynamic and multi-faceted visual information. Traditional models need help accurately analyzing temporal aspects, object interactions, and plot progression within scenes. These limitations hinder the development of robust systems capable of comprehensive video comprehension. Addressing this challenge requires innovative approaches that can manage the intricate details and vast amounts of data present in video content, pushing the boundaries of current AI capabilities.
Current methods for video understanding often rely on large multi-modal models that integrate visual and textual information. These models typically use annotated datasets where human-written questions and answers are generated based on specific scenes. However, these approaches are labor-intensive and prone to errors, making them less scalable and unreliable. Existing benchmarks, like MovieQA and TVQA, offer some insights but must cover the full spectrum of video understanding, particularly in handling complex interactions and events within scenes.
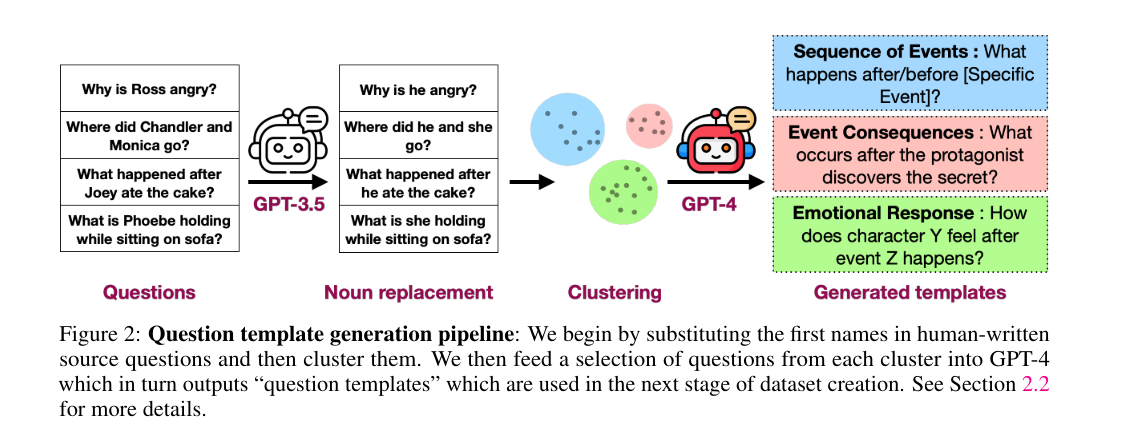
Researchers from the University of Maryland and Weizmann Institute of Science have introduced a novel approach called CinePile, which was developed by a team that included members from Gemini and other companies. This method leverages automated question template generation to create a large-scale, long-video understanding benchmark. The system integrates visual and textual data to generate detailed and diverse questions about movie scenes. CinePile aims to bridge the gap between human performance and current AI models by providing a comprehensive dataset that challenges the models’ understanding and reasoning capabilities.
CinePile uses a multi-stage process to curate its dataset. Initially, raw video clips are collected and annotated with scene descriptions. A binary classification model distinguishes between dialogue and visual descriptions. These annotations are then used to generate question templates through a language model, which are applied to the video scenes to create comprehensive question-answer pairs. The process involves shot detection algorithms to pick and annotate important frames using the Gemini Vision API. The concatenated text descriptions produce a visual summary of each scene. This summary then generates long-form questions and answers, focusing on various aspects like character dynamics, plot analysis, thematic exploration, and technical details.
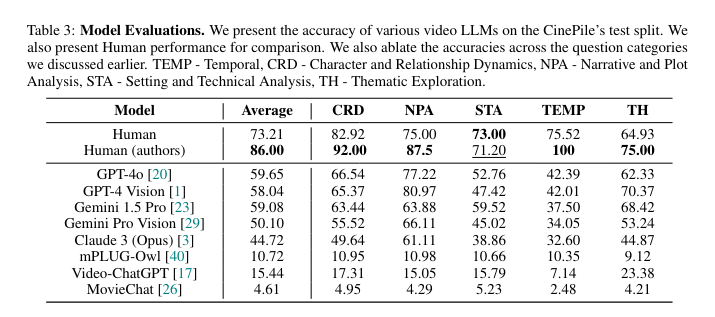
The CinePile benchmark features approximately 300,000 questions in the training set and about 5,000 in the test split. The evaluation of current video-centric models, both open-source and proprietary, showed that even state-of-the-art systems need to catch up to human performance. For example, the models often must adhere more strictly to instructions, producing verbose responses instead of concise answers. The researchers noted that open-source models like Llava 1.5-13B, OtterHD, mPlug-Owl, and MinGPT-4 showed high fidelity in image captioning but struggled with hallucinations and unnecessary text snippets. This highlights the complexity and challenges inherent in video understanding tasks and underscores the need for more sophisticated models and evaluation methods.
In conclusion, the research team addressed a critical gap in video understanding by developing CinePile. This innovative approach enhances the ability to generate diverse and contextually rich questions about videos, paving the way for more advanced and scalable video comprehension models. The work underscores the importance of integrating multi-modal data and automated processes in advancing AI capabilities in video analysis. CinePile sets a new standard for evaluating video-centric AI models by providing a robust benchmark, driving future research and development in this vital field.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.