Image by Editor
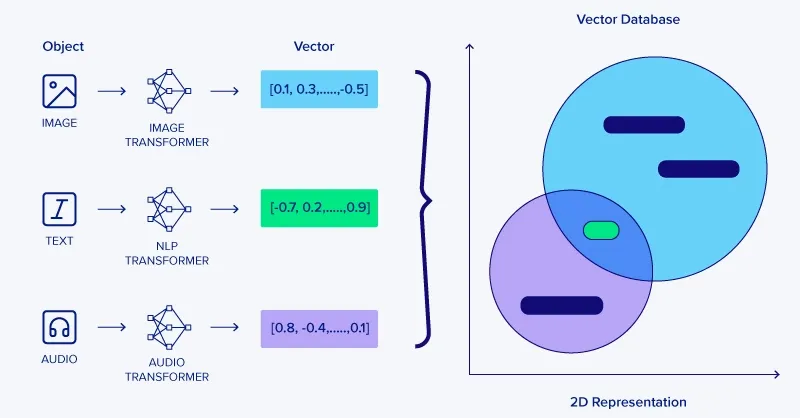
Vector database is a type of database specifically designed to store and manage vector data using arbitrary but related coordinates to related data. Unlike traditional databases that handle scalar data (like numbers, strings, or dates), vector databases are optimized for high-dimensional data points. But first we have to talk about vector embeddings.
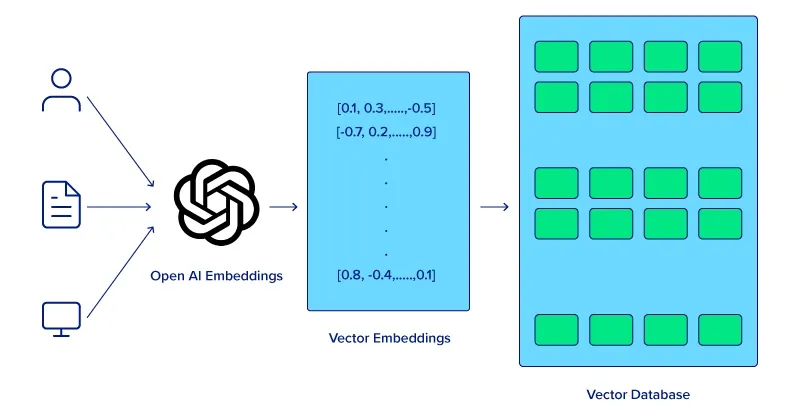
Vector embeddings are a method used in natural language processing (NLP) to represent words as vectors in a lower-dimensional space. This technique simplifies complex data for processing by models like Word2Vec, GloVe, or BERT. These real-world embeddings are highly complex, often with hundreds of dimensions, capturing nuanced attributes of words.
So how can we benefit from vectors in fields such as AI and deep learning? Vector databases offer significant benefits to the machine learning and AI field by providing efficient and scalable solutions for storing, searching, and retrieving high-dimensional data.
The database uses mathematical operations, such as distance metrics, to efficiently search, retrieve, and manipulate vectors. This organization enables the database to quickly find and analyze similar or related data points by comparing the numerical values in the vectors. As a result, vector databases are well-suited for applications like similarity search, where the goal is to identify and retrieve data points that are closely related to a given query vector. This is particularly useful in applications like image recognition, natural language processing, and recommendation systems.
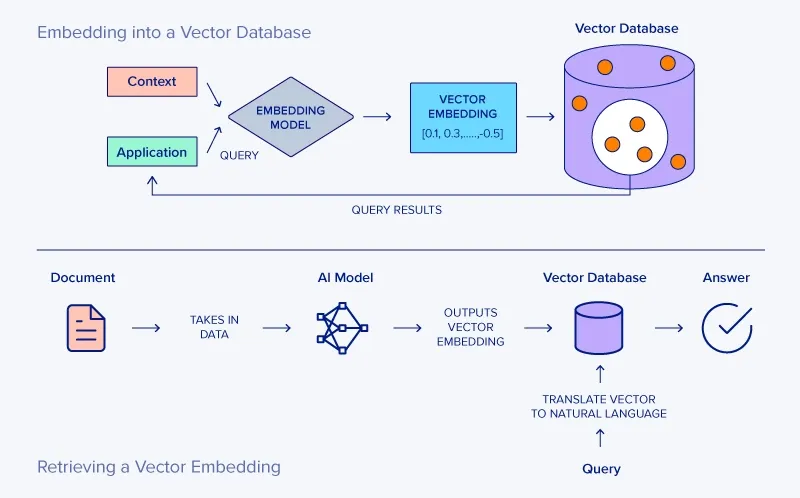
Initially, the process involves storing some text in the designated vector database. The received text undergoes a transformation into a vector form using the chosen AI model. Moving on, the newly created vector is then stored inside the vector database.
When a search prompt is issued, it’s similarly converted into vectors for comparison. The system then identifies the vectors with the highest similarity and returns them. Finally, these vectors are translated back into natural language and presented to the user as search results.
The integration of vector databases with Large Language Models (LLMs) like GPT-4 has revolutionized the way AI systems understand and generate human language. LLMs’ ability to perform deep contextual analysis of text is the result of training these models on extensive datasets, allowing them to grasp the subtleties of language, including idiomatic expressions, complex sentence structures, and even cultural nuances.
These models can achieve this by converting words, sentences, and larger text segments into high-dimensional vectors embeddings which represent much more than the text, encapsulating context and semantic relationships within the text allowing LLMs to better understand more complex ideas and situations.
Vector databases play a critical role in managing these complex vectors. They store and index the high-dimensional data, making it possible for LLMs to efficiently retrieve and process information. This capability is particularly vital for semantic search applications, where the objective is to understand and respond to queries in natural language, providing results based on attributed similarity rather than just keyword matching.
LLMs use these vectors to associate words and ideas, mirroring human understanding of language. For example, LLMs can recognize synonyms, metaphors, and even cultural references, and these linguistic relationships are represented as vectors in the database. The proximity of these vectors to each other within the database can indicate the closeness of the ideas or words they represent, enabling the model to make intelligent associations and inferences. The vectors stored in these databases represent not just the literal text but the associated ideas, concepts, and contextual relationships. This arrangement allows for a more nuanced and sophisticated understanding of language.
Additionally, users can segment lengthy documents into several vectors and automatically store them in a vector database using a technique known as Retrieval Augmented Generation. Retrieval Augmented Generation (RAG) is a technique in the field of natural language processing and artificial intelligence that enhances the process of generating text by incorporating an external knowledge retrieval step. This approach is particularly useful for creating AI models that produce more informed, accurate, and contextually relevant responses.
This approach is pivotal in addressing one of the key limitations of traditional LLMs – their reliance on a fixed dataset acquired during their initial training phase, which can become outdated or lack specific details over time.
Moving on, Generative AI is a significant application of LLMs and using vector databases. Generative AI encompasses technologies like image generation, music composition, and text creation, which have seen remarkable advancements partly due to the effective use of vector databases.
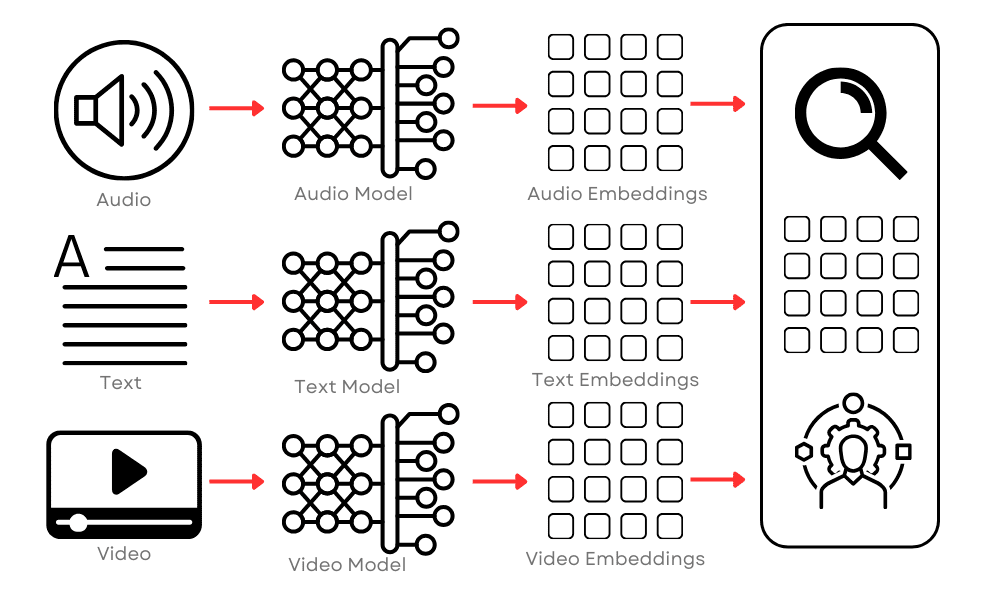
Vector databases also play a pivotal role in enhancing the capabilities of generative AI systems by efficiently managing the complex data they require and produce. Specialized transformers are essential for converting various objects, such as images, audio, and text, into their respective comprehensive vector representations.
In generative AI applications similar to LLMs, the ability to categorize and retrieve content efficiently is crucial. For instance, in image generation, a vector database can store feature vectors of images. These vectors represent key characteristics of the images, such as color, texture, or style. When a generative model needs to create a new image, it can reference these vectors to find and use similar existing images as inspiration or context. This process aids in creating more accurate and contextually relevant generated content.
The integration of vector databases with LLMs facilitates more innovative applications, such as cross-modal AI tasks. In which two different vector entities are matched together for AI tasks. This includes tasks like converting text descriptions to images or vice versa, where understanding and translating between different types of vector representations is key.
Vector databases are also instrumental in handling user interaction data within generative AI systems. By encoding user preferences, behaviors, or responses as vectors, these databases allow generative models to tailor their outputs to individual users.
In music recommendation systems, for instance, user interactions such as played songs, skipped tracks, and time spent on each song are converted into vectors. These vectors then inform the AI about a user’s musical tastes, enabling it to recommend songs that are more likely to resonate with them. As users’ preferences evolve, vector databases continuously update the vector representations, allowing the AI to stay in sync with these changes. This dynamic adaptation is key to maintaining the relevance and effectiveness of personalized AI applications over time.
Vector databases represent a significant leap in data management technology, particularly in their application to AI and machine learning. By efficiently handling high-dimensional vectors, these databases have become essential in the operation and development of advanced AI systems, including LLMs, generative AI, and deep learning.
Their ability to store, manage, and rapidly retrieve complex data structures has not only enhanced the performance of these systems but also opened new possibilities in AI applications. From semantic search in LLMs to feature extraction in deep learning, vector databases are at the heart of modern AI’s most exciting advancements. As AI continues to grow in sophistication and capability, the importance of vector databases is only set to increase, solidifying their position as a key component in the future of AI and machine learning.
Original. Reposted with permission.
Kevin Vu manages Exxact Corp blog and works with many of its talented authors who write about different aspects of Deep Learning.