The intersection of artificial intelligence and creativity has witnessed an exceptional breakthrough in the form of text-to-image (T2I) diffusion models. These models, which convert textual descriptions into visually compelling images, have broadened the horizons of digital art, content creation, and more. Yet this rapidly evolving area of Personalized T2I generation study grapples with several core issues. Foremost among these is the intensive computational resource requirement for training models capable of producing high-quality, personalized images from text descriptions. Furthermore, the process is often plagued by hyper-parameter sensitivity, resulting in inconsistent outputs that need help to align complex visual concepts and compositions accurately.
Current methods in personalized T2I generation have seen numerous advancements through various models and frameworks. Autoregressive models like DALL-E and CogView have pioneered image generation with considerable success. Meanwhile, diffusion models such as Stable Diffusion and Imagen have elevated the field by offering enhanced fidelity and diversity in T2I tasks. For personalization, Textual Inversion and Custom Diffusion concentrate on fine-tuning parameters for specific visual concepts. ELITE and BLIP-Diffusion have streamlined fast personalization for single-subject T2I. In contrast, approaches like Mix-of-Show and Zip-LoRA innovate by combining multiple concepts for generating images with several subjects.
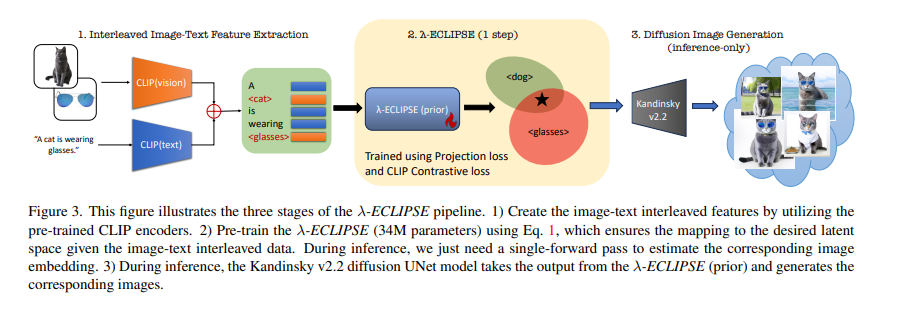
A team of researchers at Arizona State University has introduced a novel approach called λ-ECLIPSE, which circumvents the need for traditional diffusion models. This method demonstrates that effective personalized T2I generation can be achieved without depending on the latent space of diffusion models, thus significantly reducing resource requirements. λ-ECLIPSE achieves this by leveraging the latent space of a pre-trained CLIP model to perform subject-driven T2I mapping, introducing a more efficient pathway for generating personalized images with just 34M parameters.

The model is trained on a dataset of 2 million instances and is specifically tuned for the Kandinsky v2.2 diffusion image decoder. On the hardware side, it is trained on 2 x A100 GPUs with a peak learning rate of 0.00005 and employs 50 DDIM steps and 7.5 classifier-free guidance during inference. A unique image-text interleaved training approach captures the nuanced relationships between textual descriptions and visual concepts, utilizing pre-trained CLIP encoders for precise modality-specific embeddings. This method supports single and multi-subject generations, offering controlled guidance via edge maps for improved image fidelity. The contrastive pretraining strategy effectively balances concept and composition alignment, while the inclusion of canny edge maps introduces a layer of detailed control.
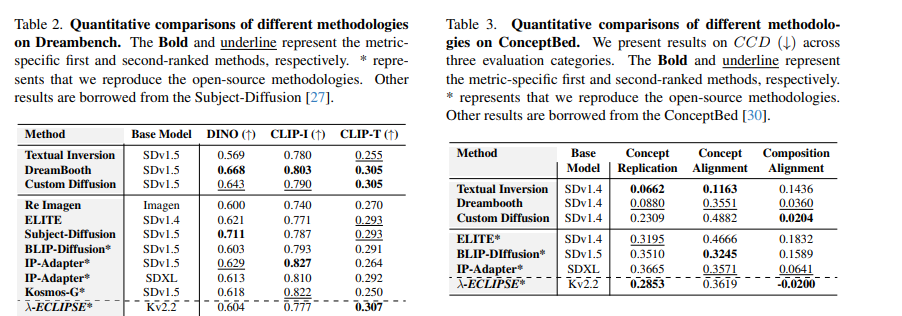
The performance of λ-ECLIPSE is worthy of consideration, especially regarding composition alignment while preserving the integrity of reference subjects. It demonstrates superior performance across a range of benchmarks, offering a promising solution to the challenges of personalized T2I generation. For Dreambench, four images per prompt are generated and evaluated, reporting average performance on three metrics (DINO, CLIP-I, and CLIP-T). In the case of ConceptBed, each of the 33K prompts is processed to generate a single image. Therefore, its ability to facilitate multi-subject-driven image generation, control outputs without explicit fine-tuning, and leverage the smooth latent space for interpolations between multiple concepts sets a new benchmark in the field.

In conclusion, the λ-ECLIPSE model represents a significant leap forward in personalized text-to-image generation. By efficiently utilizing the latent space of pre-trained CLIP models, it offers a scalable, resource-efficient solution that does not compromise the quality or personalization of generated images. This research addresses the current limitations in the field and opens up new possibilities for creative and personalized digital content generation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.