Artificial intelligence has significantly advanced in developing systems that can interpret and respond to multimodal data. At the forefront of this innovation is Lumos, a groundbreaking multimodal question-answering system designed by researchers at Meta Reality Labs. Unlike traditional systems, Lumos distinguishes itself by its exceptional ability to extract and understand text from images, enhancing the input to Multimodal Large Language Models (MM-LLMs). This capability is pivotal, especially when dealing with images captured from a first-person viewpoint, where text presence varies in clarity, size, and orientation.
The creation of Lumos was motivated by the challenge of bridging the gap between visual data interpretation and textual understanding. Traditionally, Optical Character Recognition (OCR) technologies have needed help with the diversity and complexity of scene texts. These challenges include, but are not limited to, varying font sizes, styles, orientations, and the overall quality of text as captured in real-world scenarios. Such variability often led to inaccuracies that could derail the comprehension abilities of multimodal systems.
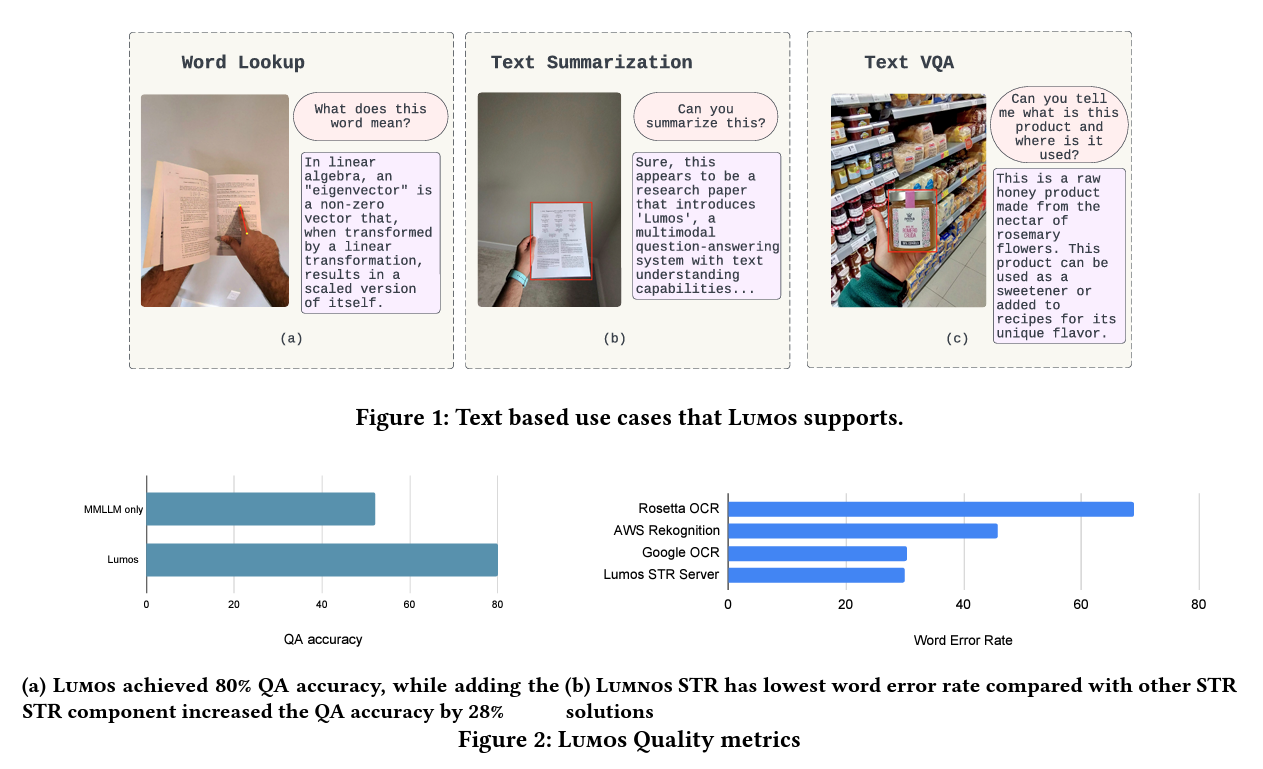
The Lumos team at Meta Reality Labs devised a novel Scene Text Recognition (STR) component to counter these obstacles. This component is ingeniously designed to capture text from images accurately, thus feeding enriched data into MM-LLMs. The strategic inclusion of STR significantly amplifies Lumos’s understanding of visual content, enabling it to deliver more precise and contextually relevant responses to user queries.
Delving deeper into Lumos’s methodology reveals a sophisticated system architecture that meticulously addresses the intricacies of text recognition and multimodal understanding. The team explored STR’s challenges comprehensively, including ensuring high-quality text extraction, minimizing latency for real-time processing, and optimizing model inference for efficiency. Through an iterative design, testing, and refinement process, Lumos was engineered to excel in real-world applications where the variability of image text is vast.
The performance evaluation of Lumos underscores its superiority and efficiency in the landscape of multimodal question-answering systems. For instance, Lumos achieved an 80% accuracy rate in question-answering tasks, a significant leap from the capabilities of existing systems. This remarkable performance is attributed to the STR component, which increased question-answering accuracy by 28%. Such numbers highlight Lumos’s effectiveness and its potential to redefine interactions with visual content.
Moreover, the system’s design considerations for on-device processing underscore a commitment to user experience. By optimizing for low latency and efficient model inference, Lumos ensures that the wonders of multimodal understanding are accessible in real-time applications, setting a new standard for interactive AI systems.
In conclusion, the development of Lumos by Meta Reality Labs marks a pivotal moment in the evolution of multimodal question-answering systems. By adeptly overcoming the challenges associated with scene text recognition and leveraging advanced modeling techniques, Lumos offers a glimpse into the future of AI, where systems can seamlessly blend visual and textual understanding to interact with the world around us in unprecedented ways. Through its innovative approach and impressive performance metrics, Lumos not only enhances the capabilities of MM-LLMs but also paves the way for new applications across diverse domains, heralding a new era of intelligent systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.