In the dynamic arena of artificial intelligence, the intersection of visual and linguistic data through large vision-language models (LVLMs) is a pivotal development. LVLMs have revolutionized how machines interpret and understand the world, mirroring human-like perception. Their applications span a vast array of fields, including but not limited to sophisticated image recognition systems, advanced natural language processing, and the creation of nuanced multimodal interactions. The essence of these models lies in their unique ability to seamlessly blend visual information with textual context, offering a more comprehensive understanding of both elements.
One of the paramount challenges in the evolution of LVLMs is the intricate balance between model performance and the computational resources required. As the size of these models increases to boost their performance and accuracy, they become more complex. This complexity directly translates to heightened computational demands. This becomes a significant hurdle in practical scenarios, especially when there is a crunch of resources or limitations in processing power. The challenge, thus, is to amplify the model’s capabilities without proportionally escalating the resource consumption.
The approach to enhance LVLMs has been predominantly centered around scaling up the models. This entails increasing the number of parameters within the model to enrich its performance capabilities. While this method has indeed been effective in enhancing the model’s functioning, it comes with the drawback of escalated training and inference costs. This makes them less practical for real-world applications. The conventional strategy typically involves activating all model parameters for each token in the calculation process, which, despite being effective, is resource-intensive.
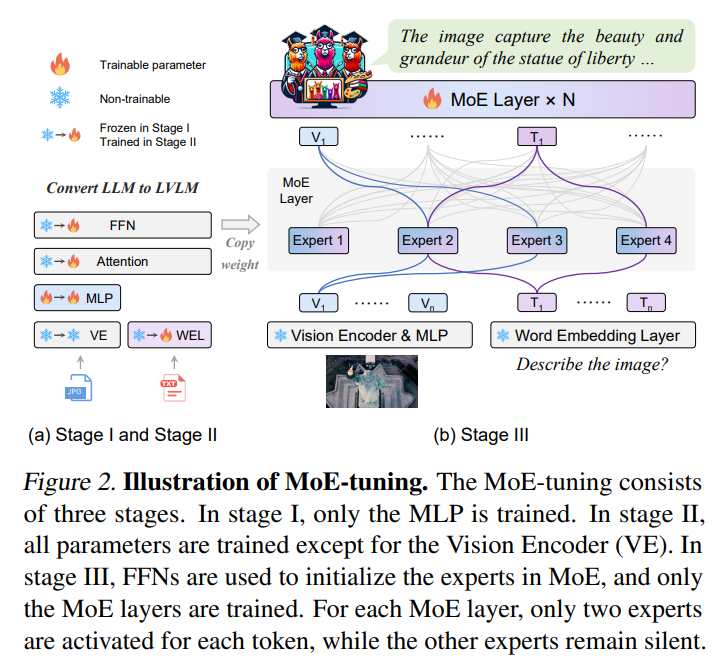
Researchers from Peking University, Sun Yat-sen University, FarReel Ai Lab, Tencent Data Platform, and Peng Cheng Laboratory have introduced MoE-LLaVA, a novel framework leveraging a Mixture of Experts (MoE) approach specifically for LVLMs. This innovative model has been the brainchild of a collaboration among a diverse group of researchers from various academic and corporate research institutions. MoE-LLaVA diverges from the conventional LVLM architectures, aiming to establish a sparse model. This model strategically activates only a fraction of its total parameters at any given time. This approach maintains the manageable computational costs while simultaneously expanding the model’s overall capacity and efficiency.
The core technology of MoE-LLaVA is rooted in its unique MoE-tuning training strategy. This strategy is a meticulously designed, multi-stage process. It commences with the adaptation of visual tokens to fit the language model framework. The process then progresses into a transition phase, shifting towards a sparse mixture of experts. The architectural design of MoE-LLaVA is intricate and includes a vision encoder, a visual projection layer (MLP), and a series of stacked language model blocks. These blocks are interspersed with strategically placed MoE layers. The architecture is fine-tuned to process image and text tokens efficiently, ensuring a harmonious and streamlined processing flow. This design enhances the model’s efficiency and provides a balanced distribution of computational workload across its various components.

One of the most striking achievements of MoE-LLaVA is its ability to deliver performance metrics comparable to those of the LLaVA-1.5-7B model across various visual understanding datasets. It accomplishes this feat with only 3 billion sparsely activated parameters, a notable reduction in resource usage. Furthermore, MoE-LLaVA demonstrates exceptional prowess in object hallucination benchmarks, surpassing the performance of the LLaVA-1.5-13B model. This underscores its superior visual understanding capabilities and highlights its potential to reduce hallucinations in model outputs significantly.
MoE-LLaVA represents a monumental leap in LVLMs, effectively addressing the longstanding challenge of balancing model size with computational efficiency. The key takeaways from this research include:
- MoE-LLaVA’s innovative use of MoEs in LVLMs carves a new path for developing efficient, scalable, and powerful multi-modal learning systems.
- It sets a new benchmark in managing large-scale models with considerably reduced computational demands, reshaping the future research landscape in this domain.
- The success of MoE-LLaVA highlights the critical role of collaborative and interdisciplinary research, bringing together diverse expertise to push the boundaries of AI technology.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.