In the landscape of text-to-image models, the demand for high-quality visuals has surged. However, these models often need to grapple with resource-intensive training and slow inference, hindering their real-time applicability. In response, this paper introduces PIXART-δ, an advanced iteration that seamlessly integrates Latent Consistency Models (LCM) and a custom ControlNet module into the existing PIXART-α framework. PIXART-α, renowned for its efficient training and superior image generation quality, serves as the foundation. LCM accelerates the inference process, generating high-quality samples in just 2∼4 steps on pre-trained Latent Diffusion Models (LDMs). This enhancement allows PIXART-δ to achieve an impressive inference speed of 0.5 seconds per 1024 × 1024 image on an A100 GPU, a 7× improvement over PIXART-α.
The incorporation of ControlNet, originally designed for UNet architectures, posed a unique challenge when applied to Transformer-based models like PIXART-δ. To overcome this, the team introduces a novel ControlNet-Transformer architecture, ensuring effective integration and preserving ControlNet’s efficacy in managing control information. The proposed design involves selectively applying the ControlNet structure to the initial N base blocks of the Transformer, demonstrating significant improvements in controllability and performance.
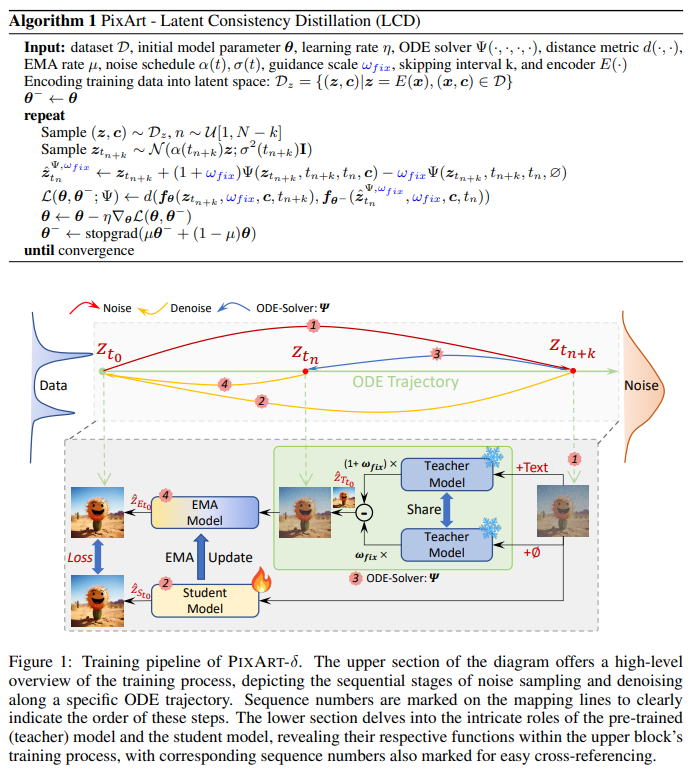
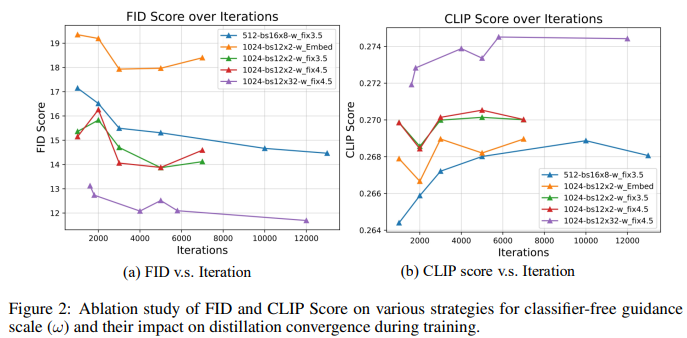
The training process leverages Latent Consistency Distillation (LCD), a refined version of the original Consistency Distillation (CD) algorithm. The pseudo-code for PIXART-δ with Classifier-Free Guidance (CFG) is outlined in Algorithm 1, where the Teacher, Student, and EMA Model (Figure 1) function as denoisers for the ODE solver. The innovative LCD algorithm demonstrates its effectiveness, which was evaluated using FID and CLIP scores as performance benchmarks (shown in Figure 2).
Training efficiency is a key highlight, with PIXART-δ successfully undergoing the distillation process within a 32GB GPU memory constraint, supporting image resolutions up to 1024 × 1024. This efficiency allows PIXART-δ to be trained on consumer-grade GPUs, expanding its accessibility.
In terms of inference speed, PIXART-δ outperforms comparable methods like SDXL LCM-LoRA, PIXART-α, and the SDXL standard across different hardware platforms. With only four steps, PIXART-δ maintains a consistent lead in generation speed, showcasing its efficiency compared to the 14 and 25 steps required by PIXART-α and SDXL standards, respectively.
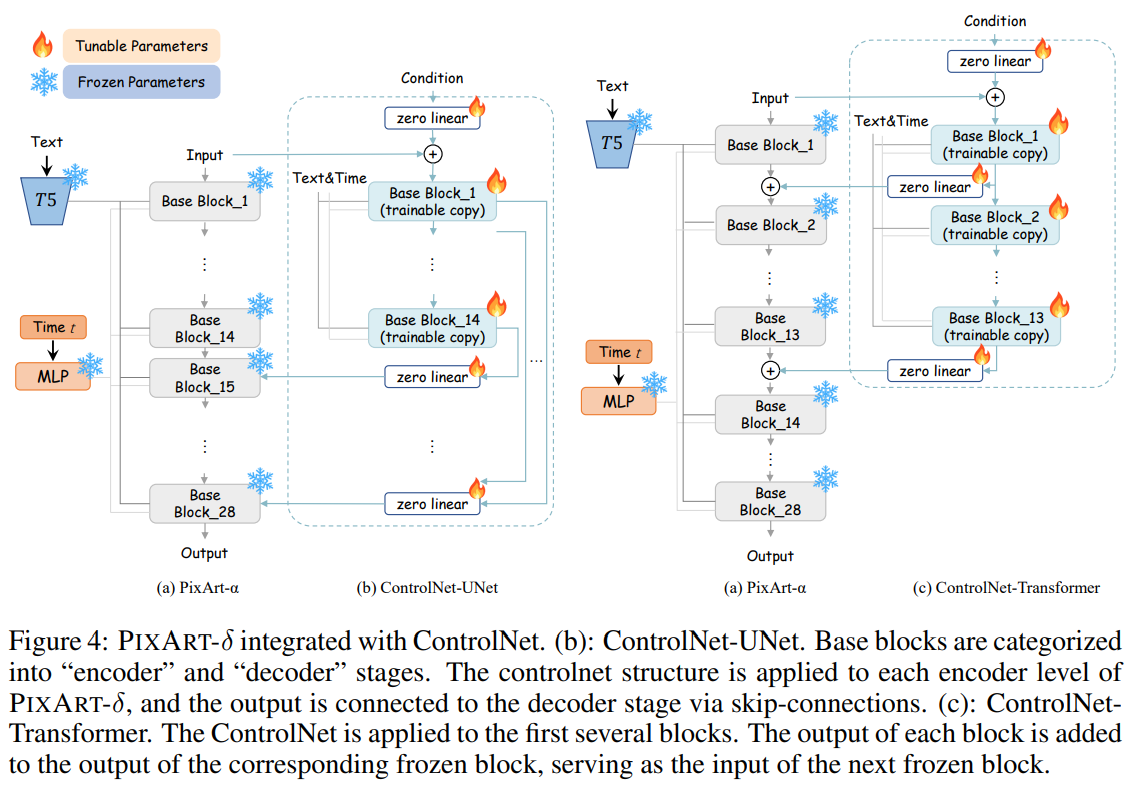

The introduction of ControlNet into PIXART-δ involves replacing the original zero-convolution with a zero linear layer tailored for Transformer architectures. The ControlNet-Transformer design, illustrated in Fig. 4 (c), selectively applies ControlNet to the initial N base blocks, achieving a seamless integration that enhances controllability and overall performance.
An ablation study on ControlNet-Transformer reveals its superiority, demonstrating faster convergence and improved performance across different scenarios. The number of copied blocks (N) is found to impact performance, with satisfactory results achieved with N = 1 for most scenarios but improved performance in challenging edge conditions as N increases (shown in Figure 5).
Analyzing the effect of training steps on ControlNet-Transformer (N = 13), the team observes rapid convergence, particularly noticeable in enhancing the quality of outline edges for human faces and bodies. The efficiency and effectiveness of ControlNet-Transformer are further emphasized, reinforcing its potential for real-time applications.
In summary, PIXART-δ represents a significant advancement in text-to-image generation, combining accelerated sampling with Latent Consistency Models and precise control through the innovative ControlNet-Transformer. Extensive experiments showcase PIXART-δ’s faster sampling and ControlNet-Transformer’s effectiveness in high-resolution and controlled image generation. This model stands at the forefront of state-of-the-art image generation, unlocking new possibilities for real-time applications.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.