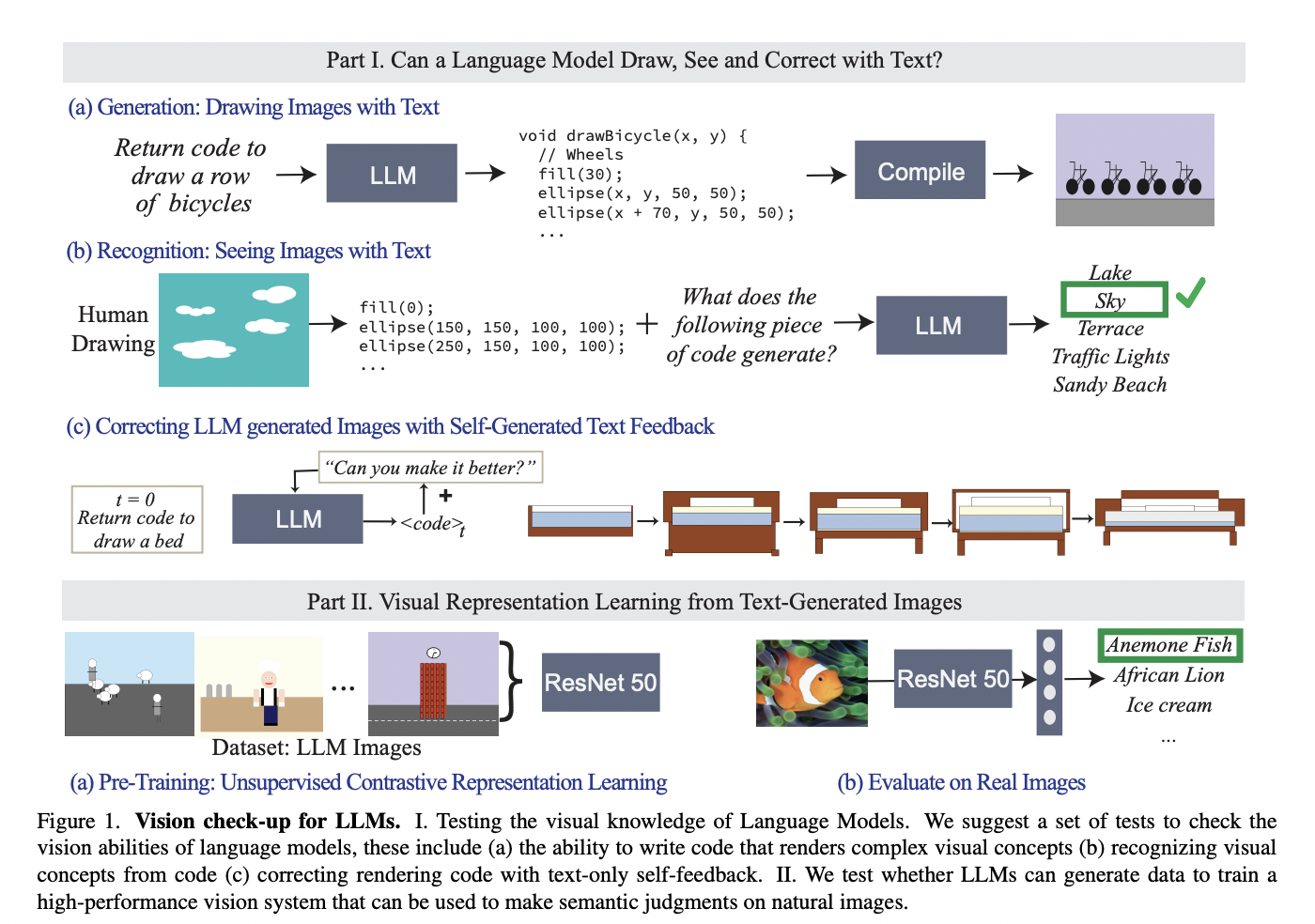
A pressing issue emerges in text-to-image (T2I) generation using reinforcement learning (RL) with quality rewards. Even though potential enhancement in image quality through reinforcement learning RL has been observed, the aggregation of multiple rewards can lead to over-optimization in certain metrics and degradation in others. Manual determination of optimal weights becomes a challenging task. This creates a need for an effective strategy that jointly optimizes multiple rewards in RL for T2I generation.
Various models have been proposed for T2I generations, such as Stable Diffusion models utilizing latent text representations from LLMs. Multiple quality metrics, including aesthetics, human preference, image-text alignment, and image sentiment, are considered in evaluating the generated image quality. RL fine-tuning has shown superior performance in human preference learning by treating denoising as a multi-step decision-making task. An example is Promptist, which fine-tunes the prompt expansion model using alignment and aesthetic scores as rewards. However, it falls short in jointly fine-tuning the T2I model, limiting its adaptability to image generation tasks.
Researchers at Google DeepMind and OpenAI, along with Rutgers University and Korea University, have proposed Parrot, a novel multi-reward RL framework for T2I generation that employs a joint optimization approach for the T2I model and prompt expansion network that enhances the generation of quality-aware text prompts. The method introduces original prompt-centered guidance at inference time to counteract potential forgetting of the original prompt.
Parrot incorporates preference information using reward-specific identifiers, automatically determining each reward objective’s importance. The supervised fine-tuning of the prompt expansion network was performed on the Promptist dataset for RL training. The T2I model, based on the JAX version of Stable Diffusion 1.5, is pre-trained with the LAION-5B dataset. The fine-tuning of the RL-based T2I diffusion model is achieved using a policy gradient algorithm, treating the denoising process as a Markov decision process.
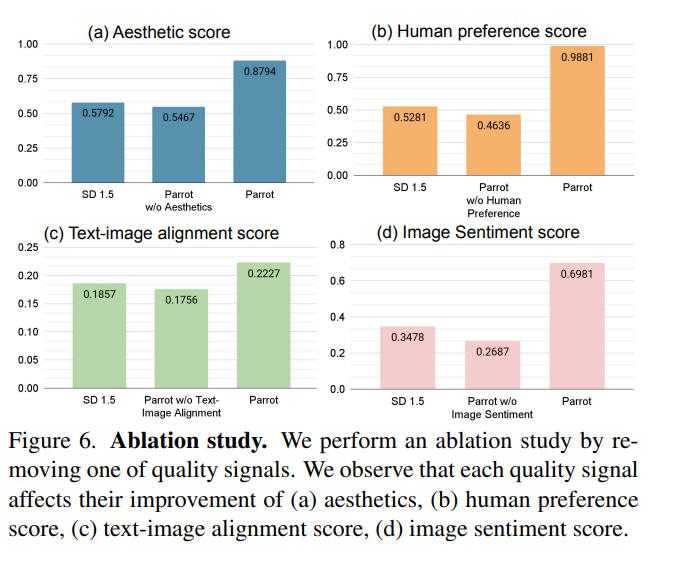
Compared to using a single reward model, the framework also improves the stated multiple quality metrics, such as aesthetics, image sentiment, and human preference. Its original prompt-centered guidance effectively addresses the issue of overwhelming the main content with added context, resulting in images that faithfully capture the original prompt while incorporating visually pleasing details.
Despite its effectiveness, reliance on existing metrics poses limitations, emphasizing the need for advancements. Parrot’s adaptability to a broader range of rewards enhances its applicability in quantifying image quality. Ethical concerns arise regarding Parrot’s potential to generate inappropriate content, emphasizing the need for scrutiny and ethical considerations in deployment.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.