Avatar technology has become ubiquitous in platforms like Snapchat, Instagram, and video games, enhancing user engagement by replicating human actions and emotions. However, the quest for a more immersive experience led researchers from Meta and BAIR to introduce “Audio2Photoreal,” a groundbreaking method for synthesizing photorealistic avatars capable of natural conversations.
Imagine engaging in a telepresent conversation with a friend represented by a photorealistic 3D model, dynamically expressing emotions aligned with their speech. The challenge lies in overcoming the limitations of non-textured meshes, which fail to capture subtle nuances like eye gaze or smirking, resulting in a robotic and uncanny interaction (see Figure 1, middle). The research aims to bridge this gap, presenting a method for generating photorealistic avatars based on the speech audio of a dyadic conversation.
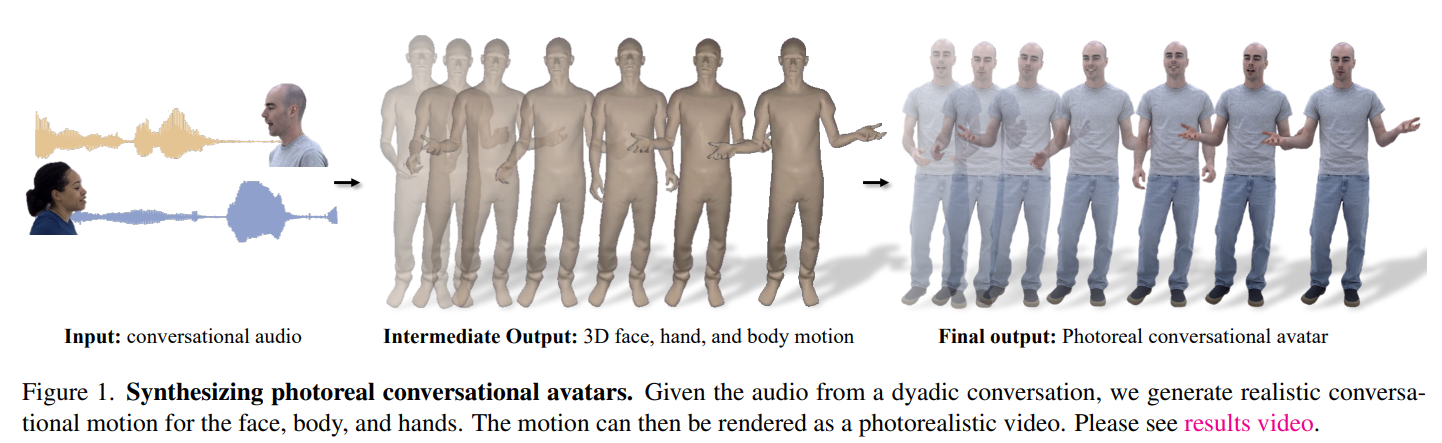
The approach involves synthesizing diverse high-frequency gestures and expressive facial movements synchronized with speech. Leveraging both an autoregressive VQ-based method and a diffusion model for body and hands, the researchers achieve a balance between frame rate and motion details. The result is a system that renders photorealistic avatars capable of conveying intricate facial, body, and hand motions in real time.
To support this research, the team introduces a unique multi-view conversational dataset, providing a photorealistic reconstruction of non-scripted, long-form conversations. Unlike previous datasets focused on upper body or facial motion, this dataset captures the dynamics of interpersonal conversations, offering a more comprehensive understanding of conversational gestures.

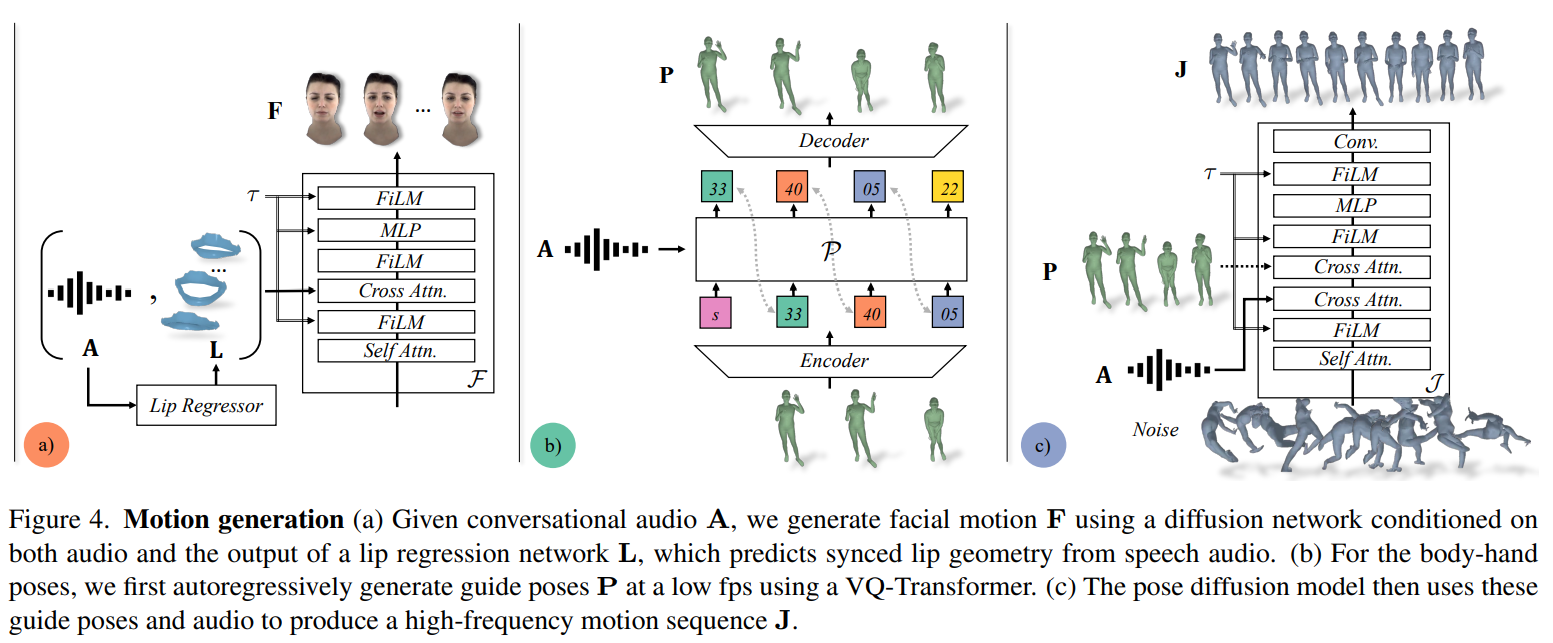
The system employs a two-model (shown in Figure 3) approach for face and body motion synthesis, each addressing the unique dynamics of these components. The face motion model (Figure 4(a)), a diffusion model conditioned on input audio and lip vertices, focuses on generating speech-consistent facial details. In contrast, the body motion model uses an autoregressive audio-conditioned transformer to predict coarse guide poses (Figure 4(b)) at 1fps, later refined by the diffusion model (Figure 4(c)) for diverse yet plausible body motions.

The evaluation demonstrates the model’s effectiveness (shown in Figure 6) in generating realistic and diverse conversational motions, outperforming various baselines. Photorealism proves crucial in capturing subtle nuances, as highlighted in perceptual evaluations. The quantitative results showcase the method’s ability to balance realism and diversity, surpassing prior works in terms of motion quality.
While the model excels in generating compelling and plausible gestures, it operates on short-range audio, limiting its capability for long-range language understanding. Additionally, the ethical considerations of consent are addressed by rendering only consenting participants in the dataset.

In conclusion, “Audio2Photoreal” represents a significant leap in synthesizing conversational avatars, offering a more immersive and realistic experience. The research not only introduces a novel dataset and methodology but also opens avenues for exploring ethical considerations in photorealistic motion synthesis.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.