Image by Author
I like to think of ChatGPT as a smarter version of StackOverflow. Very helpful, but not replacing professionals any time soon. As a former data scientist, I spent a solid amount of time playing around with ChatGPT when it came out. I was pretty impressed with its coding capacity. It could generate pretty useful code from scratch; it could offer suggestions on my own code. It was pretty good at debugging if I asked it to help me with an error message.
But inevitably, the more time I spent using it, the more I bumped up against its limitations. For any developers fearing ChatGPT will take their jobs, here’s a list of what ChatGPT can’t do.

The first limitation isn’t about its ability, but rather the legality. Any code purely generated by ChatGPT and copy-pasted by you into a company product could expose your employer to an ugly lawsuit.
This is because ChatGPT freely pulls code snippets from data it was trained on, which come from all over the internet. “I had chat gpt generate some code for me and I instantly recognized what GitHub repo it got a big chunk of it from,” explained Reddit user ChunkyHabaneroSalsa.
Ultimately, there’s no telling where ChatGPT’s code is coming from, nor what license it was under. And even if it was generated fully from scratch, anything created by ChatGPT is not copyrightable itself. As Bloomberg Law writers Shawn Helms and Jason Krieser put it, “A ‘derivative work’ is ‘a work based upon one or more preexisting works.’ ChatGPT is trained on preexisting works and generates output based on that training.”
If you use ChatGPT to generate code, you may find yourself in trouble with your employers.
Here’s a fun test: get ChatGPT to create code that would run a statistical analysis in Python.
Is it the right statistical analysis? Probably not. ChatGPT doesn’t know if the data meets the assumptions needed for the test results to be valid. ChatGPT also doesn’t know what stakeholders want to see.
For example, I might ask ChatGPT to help me figure out if there’s a statistically significant difference in satisfaction ratings across different age groups. ChatGPT suggests an independent sample T-test and finds no statistically significant difference in age groups. But the t-test isn’t the best choice here for several reasons, like the fact that there might be multiple age groups, or that the data aren’t normally distributed.
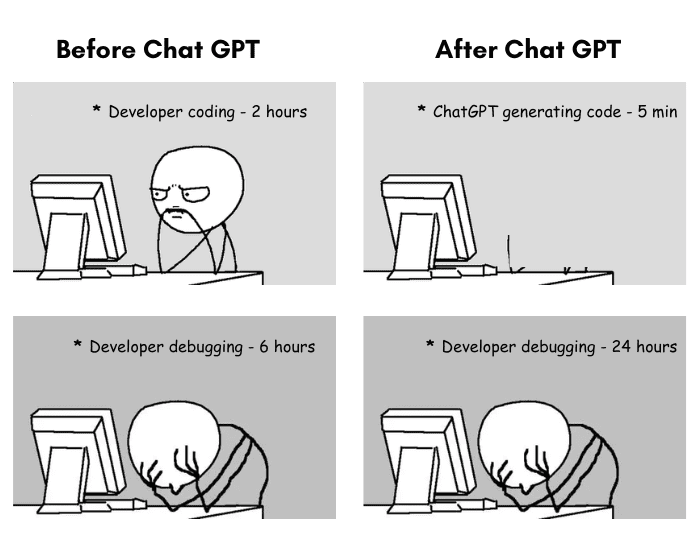
Image from decipherzone.com
A full stack data scientist would know what assumptions to check and what kind of test to run, and could conceivably give ChatGPT more specific instructions. But ChatGPT on its own will happily generate the correct code for the wrong statistical analysis, rendering the results unreliable and unusable.
For any problem like that which requires more critical thinking and problem-solving, ChatGPT is not the best bet.
Any data scientist will tell you that part of the job is understanding and interpreting stakeholder priorities on a project. ChatGPT, or any AI for that matter, cannot fully grasp or manage those.
For one, stakeholder priorities often involve complex decision-making that takes into account not just data, but also human factors, business goals, and market trends.
For example, in an app redesign, you might find the marketing team wants to prioritize user engagement features, the sales team is pushing for features that support cross-selling, and the customer support team needs better in-app support features to assist users.
ChatGPT can provide information and generate reports, but it can’t make nuanced decisions that align with the varied – and sometimes competing – interests of different stakeholders.
Plus, stakeholder management often requires a high degree of emotional intelligence – the ability to empathize with stakeholders, understand their concerns on a human level, and respond to their emotions. ChatGPT lacks emotional intelligence and cannot manage the emotional aspects of stakeholder relationships.
You may not think of that as a coding task, but the data scientist currently working on the code for that new feature rollout knows just how much of it is working with stakeholder priorities.
ChatGPT can’t come up with anything truly novel. It can only remix and reframe what it has learned from its training data.

Image from theinsaneapp.com
Want to know how to change the legend size on your R graph? No problem – ChatGPT can pull from the 1,000s of StackOverflow answers to questions asking the same thing. But (using an example I asked ChatGPT to generate), what about something it’s unlikely to have come across before, such as organizing a community potluck where each person’s dish must contain an ingredient that starts with the same letter as their last name and you want to make sure there’s a good variety of dishes.
When I tested this prompt, it gave me some Python code that decided the name of the dish had to match the last name, not even capturing the ingredient requirement correctly. It also wanted me to come up with 26 dish categories, one per letter of the alphabet. It was not a smart answer, probably because it was a completely novel problem.
Last but not least, ChatGPT cannot code ethically. It doesn’t possess the ability to make value judgments or understand the moral implications of a piece of code in the way a human does.
Ethical coding involves considering how code might affect different groups of people, ensuring that it doesn’t discriminate or cause harm, and making decisions that align with ethical standards and societal norms.
For example, if you ask ChatGPT to write code for a loan approval system, it might churn out a model based on historical data. However, it cannot understand the societal implications of that model potentially denying loans to marginalized communities due to biases in the data. It would be up to the human developers to recognize the need for fairness and equity, to seek out and correct biases in the data, and to ensure that the code aligns with ethical practices.
It’s worth pointing out that people aren’t perfect at it, either – someone coded Amazon’s biased recruitment tool, and someone coded the Google photo categorization that identified Black people as gorillas. But humans are better at it. ChatGPT lacks the empathy, conscience, and moral reasoning needed to code ethically.
Humans can understand the broader context, recognize the subtleties of human behavior, and have discussions about right and wrong. We participate in ethical debates, weigh the pros and cons of a particular approach, and be held accountable for our decisions. When we make mistakes, we can learn from them in a way that contributes to our moral growth and understanding.
I loved Redditor Empty_Experience_10’s take on it: “If all you do is program, you’re not a software engineer and yes, your job will be replaced. If you think software engineers get paid highly because they can write code means you have a fundamental misunderstanding of what it is to be a software engineer.”
I’ve found ChatGPT is great at debugging, some code review, and being just a bit faster than searching for that StackOverflow answer. But so much of “coding” is more than just punching Python into a keyboard. It’s knowing what your business’s goals are. It’s understanding how careful you have to be with algorithmic decisions. It’s building relationships with stakeholders, truly understanding what they want and why, and looking for a way to make that possible.
It’s storytelling, it’s knowing when to choose a pie chart or a bar graph, and it’s understanding the narrative that data is trying to tell you. It’s about being able to communicate complex ideas in simple terms that stakeholders can understand and make decisions upon.
ChatGPT can’t do any of that. So long as you can, your job is secure.
Nate Rosidi is a data scientist and in product strategy. He’s also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Connect with him on Twitter: StrataScratch or LinkedIn.