The captivating domain of 3D animation and modeling, which encompasses creating lifelike three-dimensional representations of objects and living beings, has long intrigued scientific and artistic communities. This area, crucial for advancements in computer vision and mixed reality applications, has provided unique insights into the dynamics of physical movements in a digital realm.
A prominent challenge in this field is the synthesis of 3D animal motion. Traditional methods rely on extensive 3D data, including scans and multi-view videos, which are laborious and costly. The complexity lies in accurately capturing animals’ diverse and dynamic motion patterns, which significantly differ from static 3D models, without depending on exhaustive data collection methods.
Previous efforts in 3D motion analysis have mainly focused on human movements, using large-scale pose annotations and parametric shape models. These methods, however, need to adequately address animal motion due to the lack of detailed animal motion data and the unique challenges presented by their varied and intricate movement patterns.
The CUHK MMLab, Stanford University, and UT Austin researchers introduced Ponymation, a novel method for learning 3D animal motions directly from raw video sequences. This innovative approach circumvents the need for extensive 3D scans or human annotations, utilizing unstructured 2D images and videos. This method represents a significant shift from traditional methodologies.
Ponymation employs a transformer-based motion Variational Auto-Encoder (VAE) to capture animal motion patterns. It leverages videos to develop a generative model of 3D animal motions, enabling the reconstruction of articulated 3D shapes and the generation of diverse motion sequences from a single 2D image. This capability is a notable advancement over previous techniques.
The method has demonstrated remarkable results in creating lifelike 3D animations of various animals. It accurately captures plausible motion distributions and outperforms existing methods in reconstruction accuracy. The research underscores its effectiveness across different animal categories, underscoring its adaptability and robustness in motion synthesis.
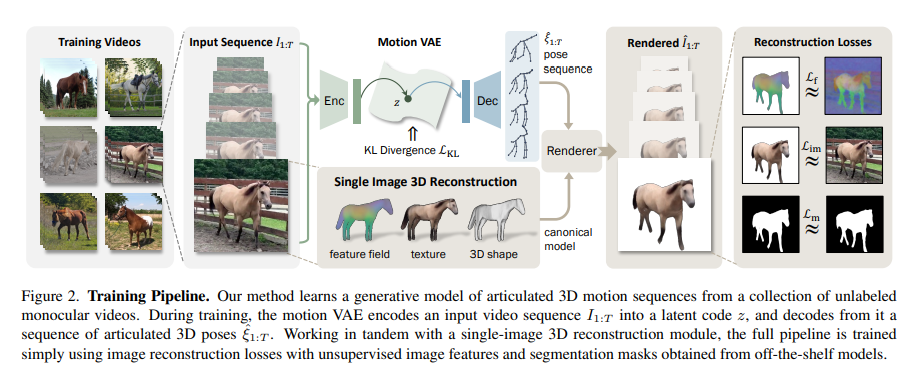
This research constitutes a significant advancement in 3D animal motion synthesis. It effectively addresses the challenge of generating dynamic 3D animal models without extensive data collection, paving the way for new possibilities in digital animation and biological studies. The approach exemplifies how modern computational techniques can yield innovative solutions in 3D modeling.
In conclusion, the summary can be stated in the following points:
- Ponymation revolutionizes 3D animal motion synthesis by learning from unstructured 2D images and videos, eliminating the need for extensive data collection.
- Using a transformer-based motion VAE in Ponymation allows for generating realistic 3D animations from single 2D images.
- The method’s ability to capture various animal motion patterns demonstrates its versatility and adaptability.
- This research opens new avenues in digital animation and biological studies, showcasing the potential of modern computational methods in 3D modeling.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.