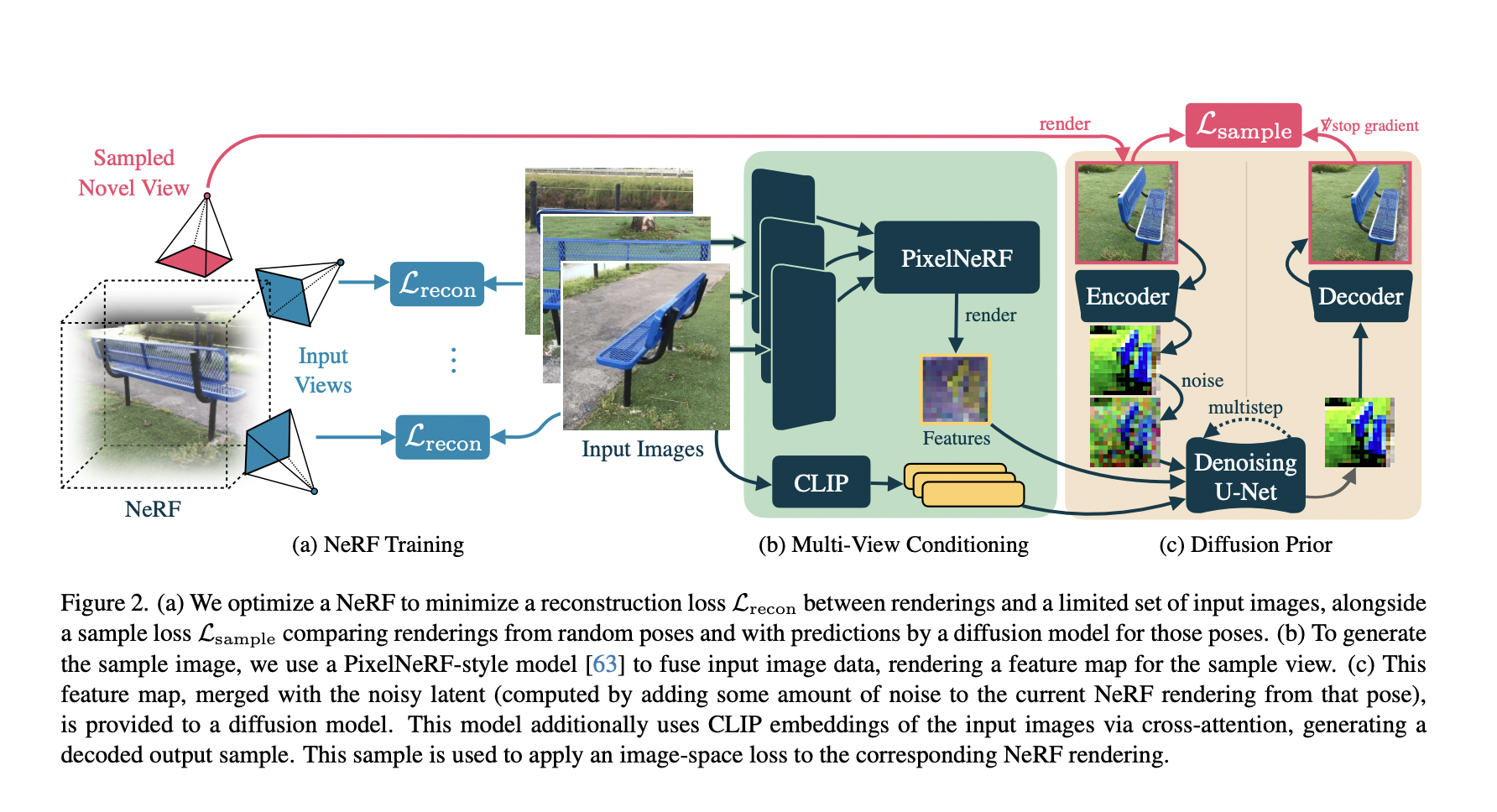
Large Vision-Language Models (LVLMs) combine computer vision and natural language processing to generate text descriptions of visual content. These models have shown remarkable progress in various applications, including image captioning, visible question answering, and image retrieval. However, despite their impressive performance, LVLMs still face some challenges, particularly when it comes to specialized tasks that require dense and fine-grained perception. The problem addressed by the Vary method is the limited vision vocabulary of LVLMs when it comes to specific tasks that demand a more nuanced understanding of visual content.
Researchers from Huazhong University of Science and Technology, MEGVII Technology, and the University of Chinese Academy of Sciences introduced Vary, a method enhancing LVLMs for specialized tasks requiring dense perception. It empowers LVLMs to acquire new features efficiently, improving fine-grained perception. Experimental results demonstrate Vary’s effectiveness across functions. Acknowledging the scope for improvement, the researchers have proposed Vary as a platform for further exploration. It notes the use of GPT-4 for generating training data and highlights Vary’s applicability to various downstream visual tasks, expanding LVLM capabilities while maintaining the original ones.
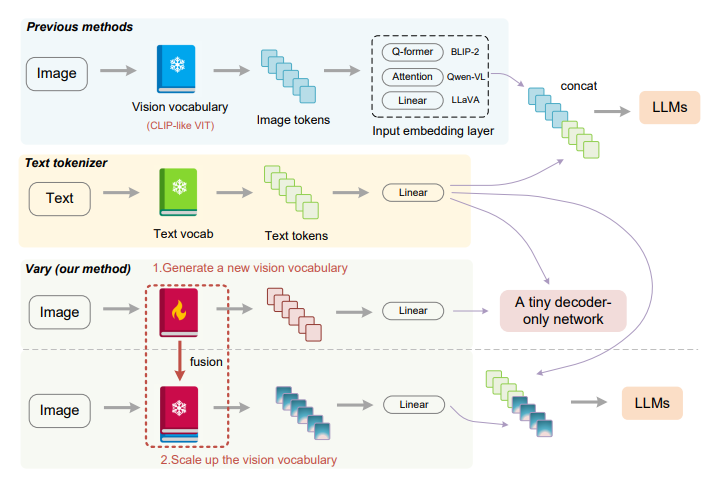
The study addresses the limitations of common vision vocabularies, such as CLIP-VIT, in dense and fine-grained vision perception scenarios, motivating the need to scale up visual vocabularies in LVLMs. It introduces Vary, a method inspired by expanding text vocabulary in LVLMs for foreign languages. Vary generates a new vision vocabulary using a vocabulary network and integrates it with the original, aiming to enhance encoding efficiency and model performance in diverse tasks like non-English OCR and chart understanding. It anticipates that Vary’s design will stimulate further research in this direction.
The research introduces two configurations of Vary: Vary-tiny and Vary-base. Vary-tiny, focusing on fine-grained perception, lacks a text input branch and employs a tiny OPT-125M model. It is trained using document and chart data as positive samples and natural images as negatives. The vocabulary network in Vary-tiny generates a new vision vocabulary, integrated with the original in Vary-base. During Vary-base training, both vocabulary networks are utilized, freezing their weights, while LVLM parameters and input embedding layers are optimized. Implementation details involve AdamW optimization, a cosine annealing scheduler, and specific learning rates. Synthetic data is created for document and chart understanding.
Vary demonstrates promising performance across multiple tasks, excelling in document-level OCR, chart understanding, and MMVet tasks. Specifically, it achieves an ANLS of 78.2% in DocVQA and 36.2% in MMVet, showcasing its competency in new document parsing features. Vary-tiny and Vary-base exhibit strong results in document OCR tasks, with Vary-base outperforming other LVLMs. While the study acknowledges Vary’s success, it emphasizes the ongoing need for improvements in effectively scaling up the visual vocabulary.
In conclusion, the study’s key takeaways can be summarized in a few points:
- Proposal: Efficient Method for Scaling up Vision Vocabulary in LVLMs.
- Methodology: The proposed method introduces a new vision vocabulary generated through a network integrated with the original language.
- Capabilities: This method enhances fine-grained perception, especially in document-level OCR and chart understanding tasks. The original powers of LVLMs are maintained while quickly acquiring new features.
- Performance: Promising scores have been demonstrated in various tasks, with this method outperforming other LVLMs in document parsing features.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.