Many branches of biology, including ecology, evolutionary biology, and biodiversity, are increasingly turning to digital imagery and computer vision as research tools. Modern technology has greatly improved their capacity to analyze large amounts of images from museums, camera traps, and citizen science platforms. This data can then be used for species delineation, understanding adaptation mechanisms, estimating population structure and abundance, and monitoring and conserving biodiversity.
Nevertheless, finding and training an appropriate model for a given task and manually labeling enough data for the particular species and study at hand are still significant challenges when trying to employ computer vision to solve a biological question. This requires a great deal of machine learning knowledge and time.
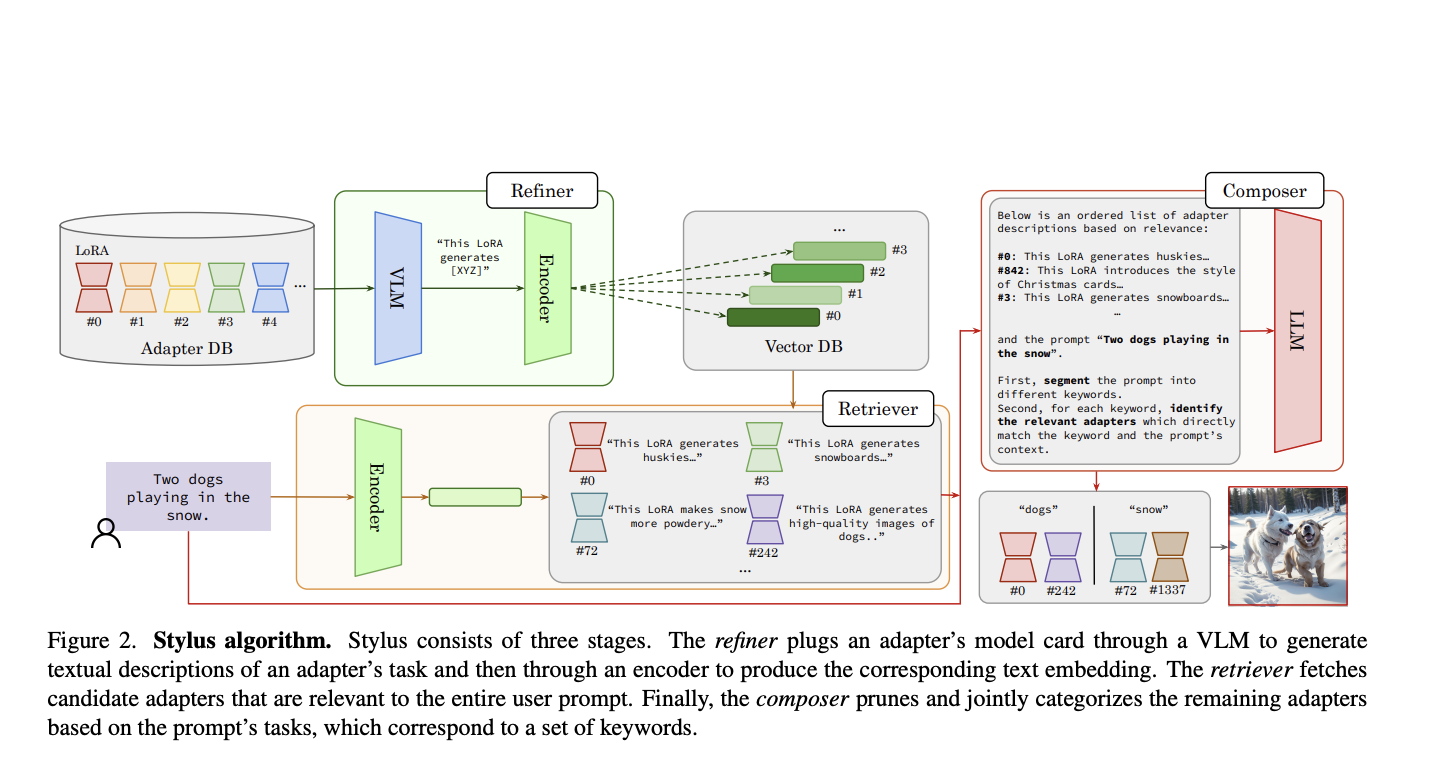
Researchers from Ohio State University, Microsoft, University of California Irvine, and Rensselaer Polytechnic Institute are investigating building such a model of the Tree of Life’s foundational vision in this effort. This model must fulfill these requirements to be generally applicable to real-world biological tasks. Before everything else, it needs to be able to accommodate researchers investigating a wide variety of clades, not just one, and ideally generalize to the entire tree of life. Furthermore, it ought to acquire fine-grained representations of images of creatures because, in the field of biology, it is common to encounter visually similar organisms, such as closely related species within the same genus or species that imitate one another’s appearances for the sake of fitness. Due to the Tree of Life’s organization of living things into broad groups (such as animals, fungi, and plants) and very fine-grained ones, this level of granularity is significant. Finally, excellent results in the low-data regime (i.e., zero-shot or few-shot) are crucial because of the high expense of data collecting and labeling in biology.
Current general-domain vision models trained on hundreds of millions of images do not perform adequately when applied to evolutionary biology and ecology, even though these goals are not new to computer vision. The researchers have identified two main obstacles to creating a vision foundation model in biology. To begin, better pre-training datasets are required since the already available ones are inadequate in terms of size, diversity, or granularity of labels. Secondly, as current pre-training algorithms do not address the three major objectives well, it is necessary to find better pre-training methods that take advantage of the unique characteristics of the biological domain.
With these aims and the obstacles to their realization in mind, the team presents the following:
- TREE OF LIFE-10M, a massive MLready biology picture dataset
- BIOCLIP is a vision-based model for the tree of life trained using appropriate taxa in TREEOFLIFE-10M.
An extensive and varied biology image dataset that is ML-ready is TREEOFLIFE-10M. With over 10 million photographs spanning 454 thousand taxa in the Tree of Life, the researchers have curated and released the largest-to-date ML-ready dataset of biology images with accompanying taxonomic labels.2 Just 2.7 million photos represent 10,000 taxa makeup iNat21, the biggest ML-ready biology image collection. Existing high-quality datasets, such as iNat21 and BIOSCAN-1M, are incorporated into TREEOFLIFE-10M. Most of the data diversity in TREEOFLIFE-10M comes from the Encyclopedia of Life (eol.org), which contains newly selected photos from that source. The taxonomic hierarchy and higher taxonomic rankings of every image in TREEOFLIFE-10M are annotated to the highest degree feasible. BIOCLIP and other models for the future of biology can be trained with the help of TREEOFLIFE-10M.
BIOCLIP is a representation of the Tree of Life based on eyesight. One common and straightforward approach to training vision models on large-scale labeled datasets like TREEOFLIFE10M is to learn to predict taxonomic indices from images using a supervised classification target. ResNet50 and Swin Transformer also use this strategy. Nevertheless, this disregards and does not use the complex system of taxonomic labels—taxa do not stand alone but are interrelated within a thorough taxonomy. Therefore, it’s possible that a model trained using basic supervised classification won’t be able to zero-shot classify unknown taxa or generalize well to taxa that weren’t present during training. Instead, the team follows a new approach combining BIOCLIP’s extensive biological taxonomy with CLIP-style multimodal contrastive learning. By using the CLIP contrastive learning objective, they can learn to associate pictures with their respective taxonomic names after they “flatten” the taxonomy from Kingdom to the distal-most taxon rank into a string known as a taxonomic name. When using the taxonomic names of taxa that are not visible, BIOCLIP can also do zero-shot classification.
The team also suggests and shows that a mixed text type training technique is beneficial; this means that they keep the generalization from taxonomy names but have more leeway to be flexible when testing by combining multiple text types (e.g., scientific names with common names) during training. For instance, downstream users can still use common species names, and BIOCLIP will perform exceptionally well. Their thorough evaluation of BIOCLIP is based on ten fine-grained picture classification datasets spanning flora, fauna, and insects and a specially curated RARE SPECIES dataset that was not used during training. BIOCLIP significantly beats CLIP and OpenCLIP, resulting in an average absolute improvement of 17% in few-shot and 18% in zero-shot circumstances, respectively. In addition, its intrinsic analysis can explain BIOCLIP’s better generalizability, which shows that it has learned a hierarchical representation that conforms to the Tree of Life.
The training of BIOCLIP remains focused on classification, even though the team has used the CLIP objective to learn visual representations for hundreds of thousands of taxa effectively. To enable BIOCLIP to extract fine-grained trait-level representations, they plan to incorporate research-grade photos from inaturalist.org, which has 100 million photographs or more, and gather more detailed textual descriptions of species’ appearances in future work.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.