Reinforcement learning without the boilerplate code

In my previous articles about reinforcement learning, I have shown you how to implement (deep) Q-learning using nothing but a bit of numpy and TensorFlow. While this was an important step towards understanding how these algorithms work under the hood, the code tended to get lengthy — and I even merely implemented one of the most basic versions of deep Q-learning.
Given the explanations in this article, understanding the code should be quite straightforward. However, if we really want to get things done, we should rely on well-documented, maintained, and optimized libraries. Just as we don’t want to implement linear regression over and over again, we don’t want to do the same for reinforcement learning.
In this article, I will show you the reinforcement library Stable-Baselines3 which is as easy to use as scikit-learn. Instead of training models to predict labels, though, we get trained agents that can navigate well in their environment.
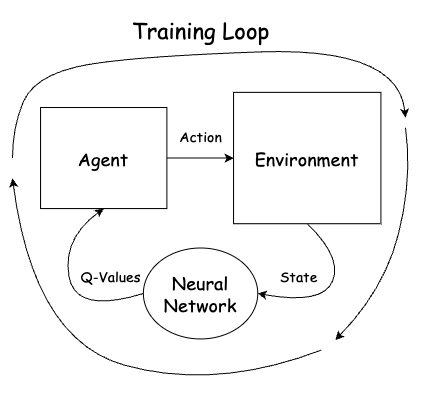
If you are not sure what (deep) Q-learning is about, I suggest reading my previous articles. On a high level, we want to train an agent that interacts with its environment with the goal of maximizing its total reward. The most important part of reinforcement learning is to find a good reward function for the agent.
I usually imagine a character in a game searching its way to get the highest score, e.g., Mario running from start to finish without dying and — in the best case — as fast as possible.

In order to do so, in Q-learning, we learn quality values for each pair (s, a) where s is a state and a is an action the agent can take. Q(s, a) is the…