The development of commercial mixed reality platforms and the quick advancement of 3D graphics technology have made the creation of high-quality 3D scenes one of the main challenges in computer vision. This calls for the capacity to convert any input text, RGB, and RGBD pictures, for example, into a variety of realistic and varied 3D scenarios. Although attempts have been made to construct 3D objects and sceneries directly using the diffusion model in voxel, point cloud, and implicit neural representation, the results have shown limited diversity and quality due to the restrictions in training data based on 3D scans. Using a pre-trained picture-generating diffusion model, like Stable Diffusion, to generate a variety of excellent 3D sceneries is one approach to address the problem. With data-driven knowledge gained from the massive training set, such a huge model produces believable images but cannot ensure multi-view consistency among the images it generates.
The research team from Seoul National University presents in this paper a pipeline named LucidDreamer that uses 3D Gaussian splatting and stable diffusion to produce a variety of high-quality 3D sceneries from several kinds of inputs, including text, RGB, and RGBD. Dreaming and Alignment are two steps that are repeated alternately to create a single, big point cloud using the LucidDreamer pipeline. The original picture and matching depth map create an initial point cloud before starting the two processes. Creating geometrically consistent pictures and projecting them into three-dimensional space are both aspects of the dreaming experience. Before projecting a visible point cloud region in the new camera coordinate onto the new camera plane, the research team moves the camera along the pre-defined camera trajectory. Subsequently, the projected picture is sent into the Stable Diffusion-based inpainting network, which uses the image to create the whole idea. By lifting the inpainted picture and the predicted depth map into the 3D space, a new collection of 3D points is created. Next, by gently shifting the new points’ location in 3D space, the suggested alignment technique smoothly joins them to the current point cloud. The study team uses the enormous point cloud that results from doing the aforementioned procedures a sufficient number of times as the starting SfM points to optimize the Gaussian splats.
Compared to previous representations, the continuous representation of 3D Gaussian splats eliminates the gaps caused by the depth difference in the point cloud, allowing us to display more photo-realistic 3D sceneries. Figure 1 displays a 3D-generating outcome along with the straightforward LucidDreamer technique. Compared to current models, LucidDreamer shows remarkably more realistic and astounding results. Better visual effects are seen across all datasets when the study team compares the created 3D scenes conditioned with a picture from ScanNet, NYUDepth, and Stable Diffusion.
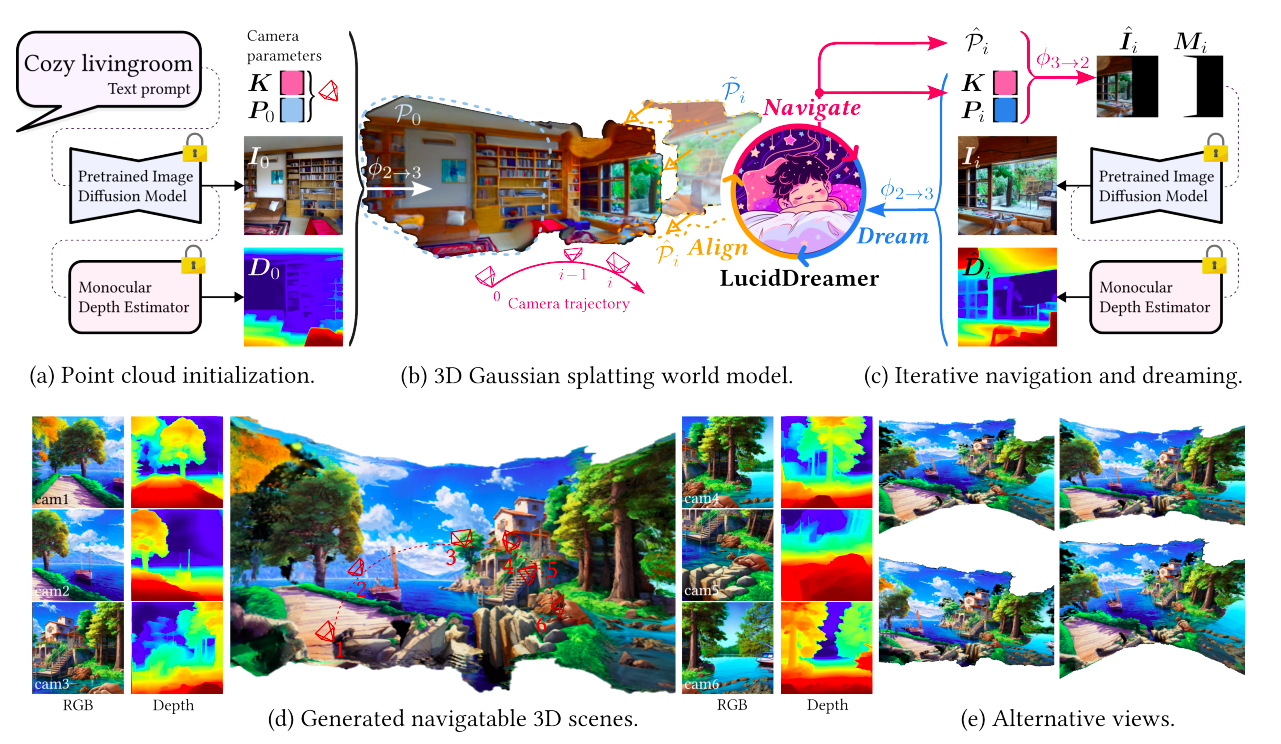
Their model can create 3D sceneries in various genres, including realistic, anime, Lego, and outdoor/indoor. Their concept supports many domains and allows several input conditions to be used simultaneously. For instance, it creates a 3D scene based on the text and adds the picture when it conditions the text and image together. This eliminates the difficulties in producing the intended scene entirely from the text and eliminates the need to produce samples extensively. Additionally, their method permits the modification of the input condition throughout the 3D space creation. These features stimulate creativity by providing an opportunity to construct a variety of 3D settings.
They have made the following contributions to sum up.
• The research team presents LucidDreamer, a domain-free, high-quality 3D scene production tool that uses explicit 3D representation, depth estimation, and stable diffusion to improve domain generalization in 3D scene synthesis.
• Their Dreaming approach produces point clouds as geometrical guidelines for each picture production to generate multi-view images from Stable Diffusion. The produced photos are skillfully integrated using their Alignment technique to create a cohesive 3D scene.
• Their methodology allows users to generate 3D sceneries in several ways by supporting multiple input types (text, RGB, and RGBD), allowing multiple inputs to be used simultaneously, and changing inputs throughout the generating process.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.